
如何使用readxl跳过第二行
如何使用readxl跳过第二行
提问于 2018-08-03 13:09:22
我得到了一个excel电子表格:列名在第一行,垃圾文本在第二行,实际数据从第三行开始。我希望使用readxl包将其读取到dataframe中,保留第一行的列名,但放弃第二行。
简单地将所有行读入dataframe,然后删除第一行将无法工作,因为excel文件第二行中的垃圾将与列的数据类型不匹配。
我想要一种不用手工编辑excel文件的方法。
回答 2
Stack Overflow用户
回答已采纳
发布于 2018-08-03 13:22:40
我建议读取整个文件,然后手动删除第2行。
例如,下面是一个示例Excel文件的屏幕截图
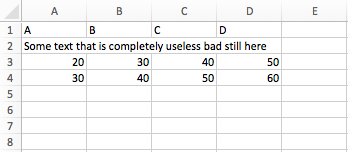
我们读取完整的文件,并删除第1行(它对应于Excel表中的第二行)
library(readxl)
library(tidyverse)
df <- read_excel("Workbook1.xlsx")[-1, ] %>%
map_df(~parse_guess(.))
df
## A tibble: 2 x 4
# A B C D
# <int> <int> <int> <int>
#1 20 30 40 50
#2 30 40 50 60Stack Overflow用户
发布于 2018-12-06 11:14:22
以下是另一个解决方案:
首先,使用readxl读取第一行并将其保存为数组(因为它只导入第一行,所以速度很快):
col_names <- array(read_excel('C:/spreadsheet.xlsx', sheet = 'Sheet1', n_max = 1, col_names = FALSE))第二,阅读相同的电子表格,但从数据开始:
df <- data.frame(read_excel('C:/spreadsheet.xlsx', sheet = 'Sheet1', skip = 2, col_names = FALSE))最后,使用第一步重命名dataframe列:
colnames(df) <- col_names页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/51673418
复制相关文章
相似问题
腾讯云开发者
