
按列等于或空的连续行分组。
在Postgres 9.2中,我试图对连续行进行分组。它们必须至少有一个非空匹配,并且没有非空匹配。如果所有的值都为null,那么就不要分组。Null可以看作是通配符。
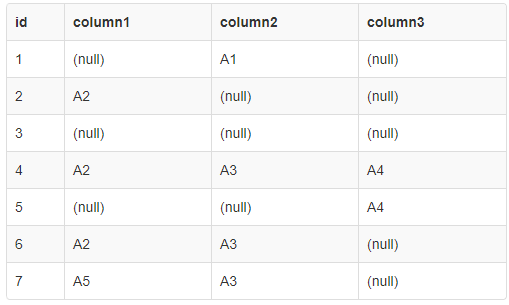
这是预期的结果:
2、4、5和6被分组是因为2和4共享column1 (3为空且跳过)、4和5共享列3、4和6共享column2和column1。

这是SQL小提琴。
回答 3
Stack Overflow用户
发布于 2018-08-10 16:38:03
对于固定的三列,这可能是一个可能的解决方案。
http://sqlfiddle.com/#!17/45dc7/137
免责声明:如果在不同的列中可能有相同的值,则将无法工作。例如,一行(42, NULL, "A42", NULL)和一行(23, "A42", NULL, NULL)将以不想要的结果结尾。修复方法是将具有唯一分隔符的列标识符连接到字符串,并在字符串拆分操作后将其删除。
WITH test_table as (
SELECT *,
array_remove(ARRAY[column1,column2,column3], null) as arr, -- A
cardinality(array_remove(ARRAY[column1,column2,column3], null))as arr_len
FROM test_table )
SELECT
s.array_agg as aggregates, -- G
MAX(tt.column1) as column1,
MAX(tt.column2) as column2,
MAX(tt.column3) as column3
FROM (
SELECT array_agg(id) FROM -- E
(SELECT DISTINCT ON (t1.id)
t1.id, CASE WHEN t1.arr_len >= t2.arr_len THEN t1.arr ELSE t2.arr END as arr -- C
FROM
test_table as t1
JOIN -- B
test_table as t2
ON t1.arr @> t2.arr AND COALESCE(t2.column1, t2.column2, t2.column3) IS NOT NULL
OR t2.arr @> t1.arr AND COALESCE(t1.column1, t1.column2, t1.column3) IS NOT NULL
ORDER BY t1.id, GREATEST(t1.arr_len, t2.arr_len) DESC -- D
) s
GROUP BY arr
UNION
SELECT
ARRAY[id]
FROM test_table tt
WHERE COALESCE(tt.column1, tt.column2, tt.column3) IS NULL) s -- F
JOIN test_table tt ON tt.id = ANY (s.array_agg)
GROUP BY s.array_aggA:聚合列值并移除NULL值。原因是我稍后会检查子集,这将不适用于NULL,这就是您应该添加列标识符的点,如上面的免责声明中所提到的。
B:把桌子对准它自己.在这里,我检查一个列聚合是否是另一个列的子集。只包含NULL值的行被忽略(这是COALESCE函数)
C:从第一个表或从第二个表获取长度最高的列数组。这取决于它的身份。
D:使用ORDER BY、最长数组和DISTINCT,可以确保每个id只给出最长的数组。
E:现在有许多ids具有相同的列数组集。数组集用于聚合ids。在这里,ids是放在一起的。
F:添加所有NULL行。
G:针对所有列的最后一个JOIN。行是来自(E)的id聚合的一部分。之后,MAX值将按列分组。
编辑:用于PostgreSQL 9.3 (array_length而不是cardinality函数)的 Fiddle,并添加了测试用例(8, 'A2', 'A3', 'A8')
http://sqlfiddle.com/#!15/8800d/2
Stack Overflow用户
发布于 2018-08-10 16:56:12
另一个想法出现在我的脑海中,它可以更动态地涉及列的数量。这只是一个想法,我不知道它是否有效。但值得一试。
也许您可以将您的表枢轴化,以便您的列成为您的行:
https://www.postgresql.org/docs/9.1/static/tablefunc.html
http://www.vertabelo.com/blog/technical-articles/creating-pivot-tables-in-postgresql-using-the-crosstab-function
在此之后,应该很容易进行分组,或者您可以使用一个窗口函数对列内容进行分区。
只是一张素描,以后再试。
Stack Overflow用户
发布于 2018-08-10 20:49:11
SQL是一种功能强大的声明性语言(4GL) --好的,主要是。声明式(基于集合的)解决方案通常是最快的。
但是,有些工作负载在定义上是非常“过程”的,很难实现。这是一种罕见的情况:一个过程解决方案可以通过一次顺序扫描来完成,并且应该是,而不是通过长时间的实现等效的纯SQL解决方案。
CREATE OR REPLACE FUNCTION f_my_grouping()
RETURNS SETOF int[] AS
$func$
DECLARE
r tbl; -- use table type as row variable
r0 tbl;
ids int[];
BEGIN
FOR r IN
SELECT * FROM tbl t ORDER BY t.id
LOOP
IF (r.column1, r.column2, r.column3) IS NULL THEN -- all NULL
RETURN NEXT ARRAY[r.id]; -- return and ignore
ELSIF (r.column1 <> r0.column1 OR -- continue
r.column2 <> r0.column2 OR
r.column3 <> r0.column3) IS NOT TRUE -- no mismatch
AND (r.column1 = r0.column1 OR
r.column2 = r0.column2 OR
r.column3 = r0.column3) THEN -- 1+ match
ids := ids || r.id; -- add to array
IF r0.column1 IS NULL AND r.column1 IS NOT NULL OR
r0.column2 IS NULL AND r.column2 IS NOT NULL OR
r0.column3 IS NULL AND r.column3 IS NOT NULL THEN
SELECT INTO r0.column1, r0.column2, r0.column3
COALESCE(r0.column1, r.column1)
, COALESCE(r0.column2, r.column2)
, COALESCE(r0.column3, r.column3);
END IF;
ELSE -- new grp
IF r0 IS NULL THEN -- skip 1st row
-- do nothing
ELSE
RETURN NEXT ids;
END IF;
ids := ARRAY[r.id]; -- start new array
r0 := r; -- remember last row
END IF;
END LOOP;
IF ids IS NOT NULL THEN -- all NULL
RETURN NEXT ids; -- output last iteration
END IF;
END
$func$ LANGUAGE plpgsql;呼叫:
SELECT * FROM f_my_grouping();如果需要排序输出:
SELECT * FROM f_my_grouping() ORDER BY 1;这里的https://dbfiddle.uk/?rdbms=postgres_9.4&fiddle=6d15a5d472da20fd11c5337801bac1df (运行Postgres 9.4)
将性能与EXPLAIN ANALYZE进行比较。
相关信息:
https://stackoverflow.com/questions/51761933
复制相似问题
腾讯云开发者
