
数据标准化与规范化与稳健扩展
我正在进行数据预处理,并希望将数据标准化与规范化与健壮的Scaler的优点进行实际比较。
理论上,准则是:
优势:
- 标准化:标度特性使分布集中于0,标准差为1。
- 归一化:缩小范围,使范围现在介于0到1之间(如果有负值,则为-1到1)。
- 稳健Scaler:类似于规范化,但它使用了四分位数范围,因此它对离群值是健壮的。
Disadvantages:
- 标准化:如果数据不是正态分布(即没有高斯分布),则不太好。
- 归一化:受到异常值(即极值)的严重影响。
- 健壮的Scaler:不考虑中值,只关注批量数据所在的部分。
我创建了20个随机数字输入,并尝试了上述方法(红色数字表示异常值):
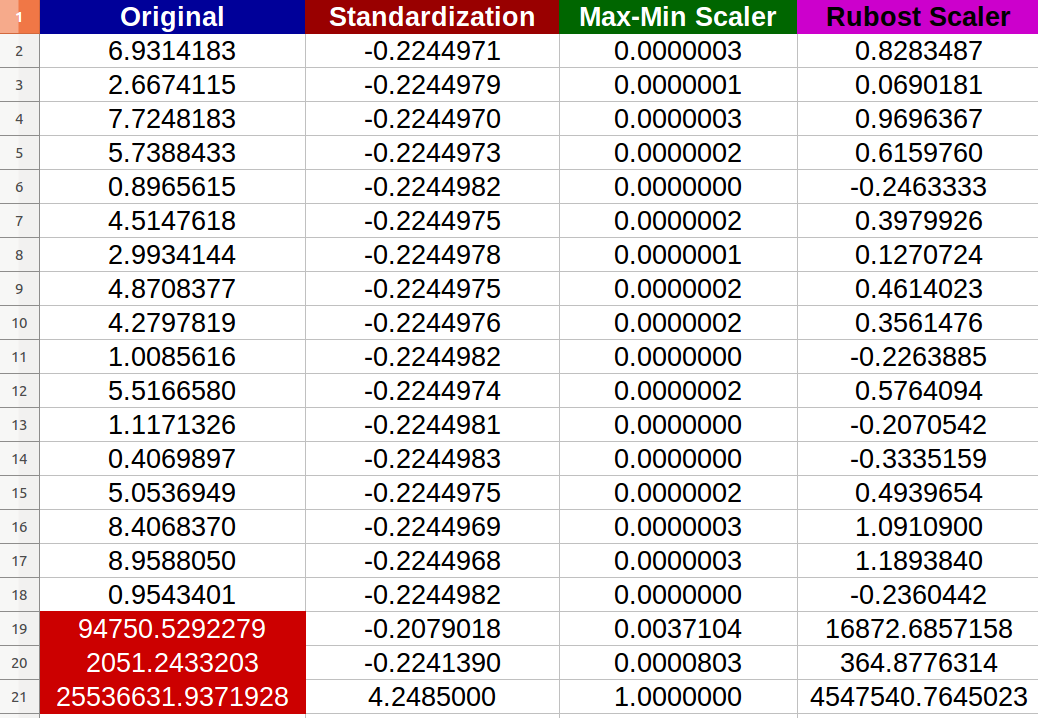
我注意到--实际上--标准化受到了异常值的负面影响,新值之间的变化比例变得很小(所有值几乎相同--小数点后的6位数-- 0.000000x),即使原始输入之间有明显的差异!
我的问题是:
- 我说得对吗?标准化也会受到极端价值观的负面影响吗?若否,为何会根据所提供的结果?
- 我真的看不出健壮的Scaler是如何改进数据的,因为结果数据集中还有极值值吗?有什么简单的完整解释吗?
回答 2
Stack Overflow用户
发布于 2019-09-25 21:43:39
它们中没有一个是稳健的,因为缩放会照顾到离群值,并将其置于一个有限的尺度上,也就是说,不会出现极值。
您可以考虑这样的选项:
- 在缩放之前裁剪序列/数组(例如,在5%到95 %之间)
- 如果剪裁不理想,则采用平方根或对数之类的转换。
- 显然,添加另一列“是剪裁”/“对数剪裁量”将减少信息损失。
Stack Overflow用户
发布于 2018-08-14 13:22:10
我说得对吗?标准化也会受到极端价值观的负面影响吗?
的确是这样;对于这种情况,学习科学知识的文档自己清楚地发出警告:
然而,当数据包含异常值时,
StandardScaler经常会被误导。在这种情况下,最好使用对异常值具有鲁棒性的标度器。
或多或少,MinMaxScaler也是如此。
我真的看不出健壮的Scaler是如何改进数据的,因为结果数据集中还有极值吗?有没有简单的-complete解释?
稳健并不意味着immune,或 invulnerable,,而缩放的目的不是“移除”异常值和极值--这是一个单独的任务,有它自己的方法;在相关的科学知识-学习文档中再次明确提到了这一点。
RobustScaler ..。注意,异常值本身仍然存在于转换后的数据中。如果需要单独的孤立点裁剪,则需要进行非线性转换(见下文)。
其中“查看下面”指的是QuantileTransformer和quantile_transform。
https://stackoverflow.com/questions/51841506
复制相似问题
腾讯云开发者
