
python、mysql和utf8mb4的编码问题
当我试图将一个简单的数据存储到mysql时,我会收到以下警告:
C:...\anaconda3\lib\site-packages\pymysql\cursors.py:170:警告:(1366,“不正确的字符串值:'\x92\xE9t\xE9)‘用于列'VARIABLE_VALUE’在第518行”)结果=self._query(查询)
和
C:...anaconda3\lib\site-packages\pymysql\cursors.py:170:警告:(3719,“utf8”目前是字符集UTF8MB3的别名,但在以后的版本中将是UTF8MB4的别名。请考虑使用UTF8MB4以使其明确。)结果=self._query(查询)
环境信息:我使用Mysql8,python3.6 (pymysql 0.9.2,sqlalchemy1.2.1)
我访问了类似链接的帖子,这些帖子似乎都没有给出如何避免这种警告的解决方案。
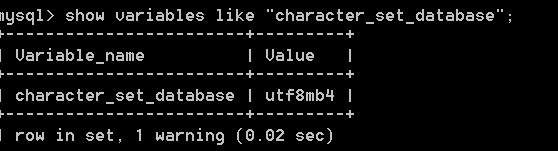
注: mysql中表中的排序规则似乎没有设置为我在create_db函数中在Connection类中指定的排序规则。
可执行代码:
import DataEngine.db.Connection as connection
import random
import pandas as pd
if __name__ == "__main__":
conn = connection.Connection(host="host_name", port="3306", user="username", password="password")
conn.create_db("raw_data")
conn.establish("raw_data")
l1 = []
for i in range(10):
l_nested = []
for j in range(10):
l_nested.append(random.randint(0, 100))
l1.append(l_nested)
df = pd.DataFrame(l1)
conn.save(df, "random_df")
df2 = conn.retrieve("random_df")
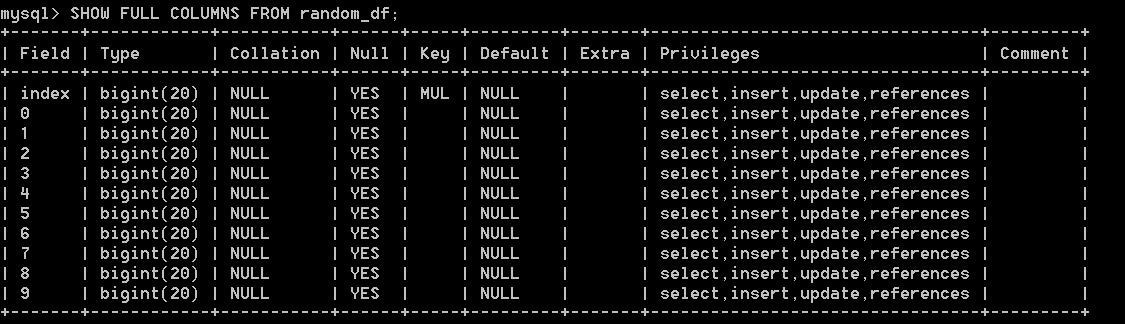
print(df2)因此,持久化在数据库中的数据文件是:
index 0 1 2 3 4 5 6 7 8 9
0 0 11 57 75 45 81 70 91 66 93 96
1 1 51 43 3 64 2 6 93 5 49 40
2 2 35 80 76 11 23 87 19 32 13 98
3 3 82 10 69 40 34 66 42 24 82 59
4 4 49 74 39 61 14 63 94 92 82 85
5 5 50 47 90 75 48 77 17 43 5 29
6 6 70 40 78 60 29 48 52 48 39 36
7 7 21 87 41 53 95 3 31 67 50 30
8 8 72 79 73 82 20 15 51 14 38 42
9 9 68 71 11 17 48 68 17 42 83 95我的Connection class
import sqlalchemy
import pymysql
import pandas as pd
class Connection:
def __init__(self: object, host: str, port: str, user: str, password: str):
self.host = host
self.port = port
self.user = user
self.password = password
self.conn = None
def create_db(self: object, db_name: str, charset: str = "utf8mb4", collate:str ="utf8mb4_unicode_ci",drop_if_exists: bool = True):
c = pymysql.connect(host=self.host, user=self.user, password=self.password)
if drop_if_exists:
c.cursor().execute("DROP DATABASE IF EXISTS " + db_name)
c.cursor().execute("CREATE DATABASE " + db_name + " CHARACTER SET=" + charset + " COLLATE=" + collate)
c.close()
print("Database %s created with a %s charset" % (db_name, charset))
def establish(self: object, db_name: str, charset: str = "utf8mb4"):
self.conn = sqlalchemy.create_engine(
"mysql+pymysql://" + self.user + ":" + self.password + "@" + self.host + ":" + self.port + "/" + db_name +
"?charset=" + charset)
print("Connection with database : %s has been established as %s at %s." % (db_name, self.user, self.host))
print("Charset : %s" % charset)
def retrieve(self, table):
df = pd.read_sql_table(table, self.conn)
return df
def save(self: object, df: "Pandas.DataFrame", table: str, if_exists: str = "replace", chunksize: int = 10000):
df.to_sql(name=table, con=self.conn, if_exists=if_exists, chunksize=chunksize)一些可能有帮助的要素:
回答 1
Stack Overflow用户
发布于 2018-08-21 00:55:00
那么,十六进制92和e9是无效的utf8mb4 (UTF-8).也许您期待的是’été,假设是CHARACTER SETs cp1250、cp1256、cp1257或latin1。
找出文本的来源,让我们决定它是否有效的latin1。然后我们就可以修正代码来声明客户机确实在使用latin1,而不是utf8mb4?或者我们可以修复客户端使用UTF-8,从长远来看,这可能会更好。
https://stackoverflow.com/questions/51844631
复制相似问题
腾讯云开发者
