
没有在BeautifulSoup中显示的表元素
没有在BeautifulSoup中显示的表元素
提问于 2018-08-17 14:39:57
我正在尝试从本网站中提取表数据
以下是代码--
import requests
from bs4 import BeautifulSoup as bs
page = requests.get('https://www.vitalityservicing.com/serviceapi/Monitoring/QueueDepth?tenantId=1')
soup = bs(page.text, "html.parser")
#None of the following method works
tb = soup.table
#tb = soup.body.table
#tb = soup.find_all('table')当我试图打印tb及其None时
因此,我试图查看下载的HTML的body
print(soup.body.prettify())我没有看到table元素或它的子元素。只存在<body>和<script>元素:
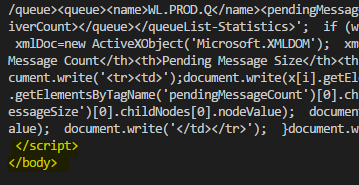
但是,当我用铬检查页面时,我会看到所有的元素:

我不明白为什么当我在chrome上加载页面时,table元素不是用requests.get下载的
回答 1
Stack Overflow用户
回答已采纳
发布于 2018-08-20 09:13:48
您没有获得该内容,因为当您执行请求时,它不在页面中。目前还没有。
如果您检查脚本标记之间的javascript代码,您可以看到它正在动态地生成表。因此,在发生这种情况之前,您将收到html代码,因为requests不是浏览器,不会执行js,也不会看到表。
现在您已经知道了为什么看不到表,接下来的问题是如何在javascript执行之后生成HTML。不要晕倒,这是可行的。您可能会发现这个问题中的解决方案很有趣。
祝好运
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/51897756
复制相关文章
相似问题
腾讯云开发者
