
改进车牌识别
改进车牌识别
提问于 2018-08-20 15:22:27
我正在做一个基于车牌识别的学校项目。我正在简单的电影上测试它:一辆车,静态相机等。
如下所示:
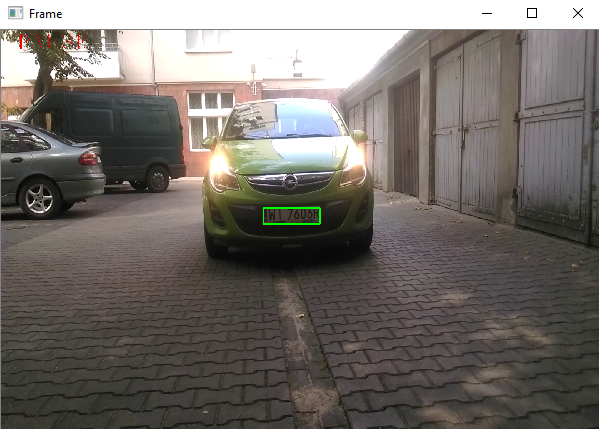
我的第一步是在这个框架上找到一辆车(我认为这将有助于更多的“困难”视频):

然后我搜索车牌号。这是我的代码:
std::vector<cv::Rect> boundRect;
cv::Mat img_gray, img_sobel, img_threshold, element;
cvtColor(detectedMats[i], img_gray, CV_BGR2GRAY);
cv::Sobel(img_gray, img_sobel, CV_8U, 1, 0, 3, 1, 0, cv::BORDER_DEFAULT);
cv::threshold(img_sobel, img_threshold, 0, 255, CV_THRESH_OTSU + CV_THRESH_BINARY);
element = getStructuringElement(cv::MORPH_RECT, cv::Size(30, 30));
//element = getStructuringElement(cv::MORPH_RECT, cv::Size(17, 3) );
cv::morphologyEx(img_threshold, img_threshold, CV_MOP_CLOSE, element);
std::vector< std::vector< cv::Point> > LP_contours;
cv::findContours(img_threshold, LP_contours, 0, 1);
std::vector<std::vector<cv::Point> > contours_poly(LP_contours.size());
for (int ii = 0; ii < LP_contours.size(); ii++)
if (LP_contours[ii].size() > 100 && contourArea(LP_contours[ii]) > 3000 && contourArea(LP_contours[ii]) < 10000) //można się pobawić parametrami
{
cv::approxPolyDP(cv::Mat(LP_contours[ii]), contours_poly[ii], 3, true);
cv::Rect appRect(boundingRect(cv::Mat(contours_poly[ii])));
if (appRect.width > appRect.height)
boundRect.push_back(appRect);
} 你可以在第二张图片上看到结果。
然后尝试得到较好的检测板轮廓。我做了几步。
- 鉴于亮度的急剧变化,通过直方图均衡化:

- 使用过滤器和阈值: 简历:Mat blur;cv::bilateralFilter(均衡化,模糊,9,75,75);cv:imshow(“Filter”,blur);/*阈值,用于二值化图像*/ cv::Mat thres;cv::adaptiveThreshold(blur,thres,255,cv::ADAPTIVE_THRESH_GAUSSIAN_C,cv::THRESH_BINARY,15,2);//15,2 cv::imshow(“阈值”,thres);


- 最后,我找到了轮廓,但它们不是很好。数字有点模糊: std::vector >等高线;cv::findContours(thres,等值线,cv::RETR_LIST,cv::CHAIN_APPROX_SIMPLE);//cv:findContours(thres,等高线,CV_RETR_TREE,CV_CHAIN_APPROX_SIMPLE,Point(0,0));双min_area = 50;double max_area = 2000;std::vector > good_contours;for (size_t i= 0;i< contours.size();( i++) { double area = cv::contourArea(contoursi);if (area > min_area &if;area < max_area) good_contours.push_back(contoursi);}

也许你对如何提高成绩有一些想法?我试着改变了一些参数,但效果还是不太好。
谢谢你的帮助
- 我安装vcpkg。
- 使用 .\vcpkg安装tesseract:x64-windows-静态 在安装结束时,我得到了一些错误:

- 但是当我检查的时候,它似乎很好:

- 在集成安装之后,我得到了以下信息:
- 将lib添加到项目中:

所以看起来不错,但是当我尝试运行示例时,VS没有看到库:
解决:
变化
.\vcpkg install tesseract:x64-windows-static转到
.\vcpkg install tesseract:x64-windows而且效果很好。
回答 1
Stack Overflow用户
回答已采纳
发布于 2018-08-21 14:35:07
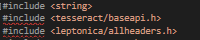
使用tesseract OCR检测文本。成功安装tesseract之后,在附加依赖项中添加tesseract305.lib和liptonica-1.74.4.lib。使用以下代码(来自教程):
#include "stdafx.h"
#include "winsock2.h"
#include <tesseract/baseapi.h>
#include <leptonica/allheaders.h>
#pragma comment(lib, "ws2_32.lib")
int main()
{
char *outText;
tesseract::TessBaseAPI *api = new tesseract::TessBaseAPI();
// Initialize tesseract-ocr with English, without specifying tessdata path
if (api->Init(NULL, "eng")) {
fprintf(stderr, "Could not initialize tesseract.\n");
exit(1);
}
// Open input image with leptonica library
Pix *image = pixRead("test.tif");
api->SetImage(image);
// Get OCR result
outText = api->GetUTF8Text();
printf("OCR output:\n%s", outText);
// Destroy used object and release memory
api->End();
delete[] outText;
pixDestroy(&image);
return 0;
}页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/51933928
复制相关文章
相似问题
腾讯云开发者
