
芹菜工人运行tensorflow无法创建CUDA事件
芹菜工人运行tensorflow无法创建CUDA事件
提问于 2018-09-19 03:11:31
我正在向芹菜工人加载tensorflow模型,但是当我试图对该工人运行一个任务时,它会显示以下错误:
[2018-09-19 10:29:39,753: INFO/MainProcess] Received task: analyze_atom[f6bb76cc-aa16-4761-a7cf-0ed111886ff8]
[2018-09-19 10:29:41,198: WARNING/ForkPoolWorker-2] paper checkpoint1 takes 1.433300495147705 senconds
2018-09-19 10:29:41.318467: E tensorflow/core/grappler/clusters/utils.cc:81] Failed to get device properties, error code: 3
2018-09-19 10:29:42.650529: E tensorflow/stream_executor/event.cc:40] could not create CUDA event: CUDA_ERROR_NOT_INITIALIZED
[2018-09-19 10:29:42,673: ERROR/MainProcess] Process 'ForkPoolWorker-2' pid:3782 exited with 'signal 11 (SIGSEGV)'
[2018-09-19 10:29:42,704: ERROR/MainProcess] Task handler raised error: WorkerLostError('Worker exited prematurely: signal 11 (SIGSEGV).',)
Traceback (most recent call last):
File "/usr/local/lib/python3.6/site-packages/billiard/pool.py", line 1223, in mark_as_worker_lost
human_status(exitcode)),
billiard.exceptions.WorkerLostError: Worker exited prematurely: signal 11 (SIGSEGV).这是一个tensorflow模型,当芹菜启动时,模型在GPU上成功加载,下面是开始的工作日志:
totalMemory: 15.90GiB freeMemory: 15.61GiB
2018-09-19 10:35:38.431559: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1435] Adding visible gpu devices: 0
2018-09-19 10:35:38.793007: I tensorflow/core/common_runtime/gpu/gpu_device.cc:923] Device interconnect StreamExecutor with strength 1 edge matrix:
2018-09-19 10:35:38.793054: I tensorflow/core/common_runtime/gpu/gpu_device.cc:929] 0
2018-09-19 10:35:38.793063: I tensorflow/core/common_runtime/gpu/gpu_device.cc:942] 0: N
2018-09-19 10:35:38.793487: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1053] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 15131 MB memory) -> physical GPU (device: 0, name: Tesla P100-PCIE-16GB, pci bus id: 0000:00:08.0, compute capability: 6.0)
2018-09-19 10:35:40.552010: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1435] Adding visible gpu devices: 0
2018-09-19 10:35:40.552073: I tensorflow/core/common_runtime/gpu/gpu_device.cc:923] Device interconnect StreamExecutor with strength 1 edge matrix:
2018-09-19 10:35:40.552080: I tensorflow/core/common_runtime/gpu/gpu_device.cc:929] 0
2018-09-19 10:35:40.552085: I tensorflow/core/common_runtime/gpu/gpu_device.cc:942] 0: N
2018-09-19 10:35:40.552327: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1053] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 15131 MB memory) -> physical GPU (device: 0, name: Tesla P100-PCIE-16GB, pci bus id: 0000:00:08.0, compute capability: 6.0)
2018-09-19 10:35:41.304281: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1435] Adding visible gpu devices: 0
2018-09-19 10:35:41.304336: I tensorflow/core/common_runtime/gpu/gpu_device.cc:923] Device interconnect StreamExecutor with strength 1 edge matrix:
2018-09-19 10:35:41.304344: I tensorflow/core/common_runtime/gpu/gpu_device.cc:929] 0
2018-09-19 10:35:41.304348: I tensorflow/core/common_runtime/gpu/gpu_device.cc:942] 0: N
2018-09-19 10:35:41.304574: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1053] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 15131 MB memory) -> physical GPU (device: 0, name: Tesla P100-PCIE-16GB, pci bus id: 0000:00:08.0, compute capability: 6.0)
2018-09-19 10:35:43.013963: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1435] Adding visible gpu devices: 0
2018-09-19 10:35:43.014025: I tensorflow/core/common_runtime/gpu/gpu_device.cc:923] Device interconnect StreamExecutor with strength 1 edge matrix:
2018-09-19 10:35:43.014033: I tensorflow/core/common_runtime/gpu/gpu_device.cc:929] 0
2018-09-19 10:35:43.014038: I tensorflow/core/common_runtime/gpu/gpu_device.cc:942] 0: N
2018-09-19 10:35:43.037554: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1053] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 15131 MB memory) -> physical GPU (device: 0, name: Tesla P100-PCIE-16GB, pci bus id: 0000:00:08.0, compute capability: 6.0)
2018-09-19 10:35:43.916442: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1435] Adding visible gpu devices: 0
2018-09-19 10:35:43.916500: I tensorflow/core/common_runtime/gpu/gpu_device.cc:923] Device interconnect StreamExecutor with strength 1 edge matrix:
2018-09-19 10:35:43.916507: I tensorflow/core/common_runtime/gpu/gpu_device.cc:929] 0
2018-09-19 10:35:43.916512: I tensorflow/core/common_runtime/gpu/gpu_device.cc:942] 0: N
2018-09-19 10:35:43.916752: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1053] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 15131 MB memory) -> physical GPU (device: 0, name: Tesla P100-PCIE-16GB, pci bus id: 0000:00:08.0, compute capability: 6.0)
2018-09-19 10:35:44.137238: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1435] Adding visible gpu devices: 0
2018-09-19 10:35:44.137296: I tensorflow/core/common_runtime/gpu/gpu_device.cc:923] Device interconnect StreamExecutor with strength 1 edge matrix:
2018-09-19 10:35:44.137304: I tensorflow/core/common_runtime/gpu/gpu_device.cc:929] 0
2018-09-19 10:35:44.137308: I tensorflow/core/common_runtime/gpu/gpu_device.cc:942] 0: N
2018-09-19 10:35:44.137563: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1053] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 15131 MB memory) -> physical GPU (device: 0, name: Tesla P100-PCIE-16GB, pci bus id: 0000:00:08.0, compute capability: 6.0)
[2018-09-19 10:35:44,650: INFO/MainProcess] Connected to amqp://yjyx:**@118.178.129.156:5672/yjyx
[2018-09-19 10:35:44,667: INFO/MainProcess] mingle: searching for neighbors
[2018-09-19 10:35:45,716: INFO/MainProcess] mingle: sync with 1 nodes
[2018-09-19 10:35:45,717: INFO/MainProcess] mingle: sync complete
[2018-09-19 10:35:45,750: INFO/MainProcess] celery@yjyx-gpu-1 ready.我还看到分配了GPU内存:
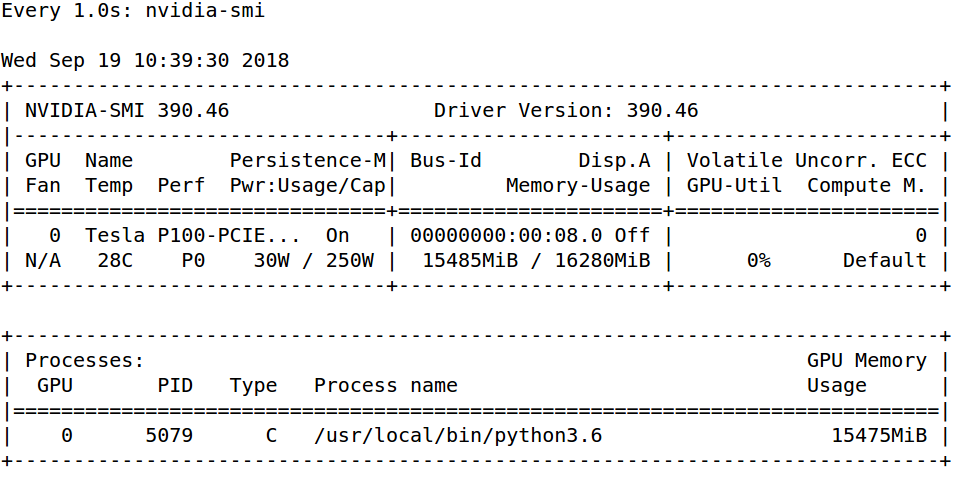
我使用主管来管理芹菜,下面是主管配置:
[program:celeryworker_paperanalyzer]
process_name=%(process_num)02d
directory=/home/yjyx/yijiao_src/yijiao_main
command=celery worker -A project.celerytasks.celery_worker_init -Q paperanalyzer -c 2 --loglevel=INFO
user=yjyx
numprocs=1
stdout_logfile=/home/yjyx/log/celeryworker_paperanalyzer0.log
stderr_logfile=/home/yjyx/log/celeryworker_paperanalyzer1.log
stdout_logfile_maxbytes=50MB ; maximum size of logfile before rotation
stderr_logfile_maxbytes=50MB
stderr_logfile_backups=10 ; number of backed up logfiles
stdout_logfile_backups=10
autostart=false
autorestart=false
startsecs=5
stopwaitsecs=8
killasgroup=true
priority=1000这里是芹菜任务代码片段:
@shared_task(name="analyze_atom", queue="paperanalyzer")
def analyze_atom(image_urls, targetdir=target_path, studentuid=None):
try:
if targetdir is not None and os.path.exists(targetdir):
os.chdir(targetdir)
paper = Paper(image_urls, studentuid)
for image_url in paper.image_urls:
if type(image_url) == str:
paper.analyze(image_url) # tensorflow inference get called within paper.analyze
elif type(image_url) == dict:
paper.analyze(image_url['url'], str(image_url['pn']), image_url.get('cormode', 0))
return paper.data
except Exception as e:
logger.log(40, traceback.print_exc())
logger.log(40, e)
return {}我确信整个过程应该是好的,实际上,我在paper.analyze中使用了opencv来处理这项工作,并且工作得很好,现在我只是将opencv更改为tensorflow。
环境: Python3.6.4;Tensorflow 1.8;芹菜4.0.2;OS: Centos 7.2
任何帮助都是非常感谢的。:-)
谢谢。
韦斯利
回答 1
Stack Overflow用户
发布于 2022-12-04 16:26:45
更改为单线程是一个简单的解决办法。可以通过将-P solo添加到芹菜命令中来解决此问题。
即:
celery -app APP worker -P solo --loglelvel=info注意:APP是您的应用程序名。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/52397450
复制相关文章
相似问题
腾讯云开发者
