
映射到错误的路易斯意图
我正面临一个问题,在这个问题上,不符合任何意图的话,它将认为它属于意图与标签最多的话语。
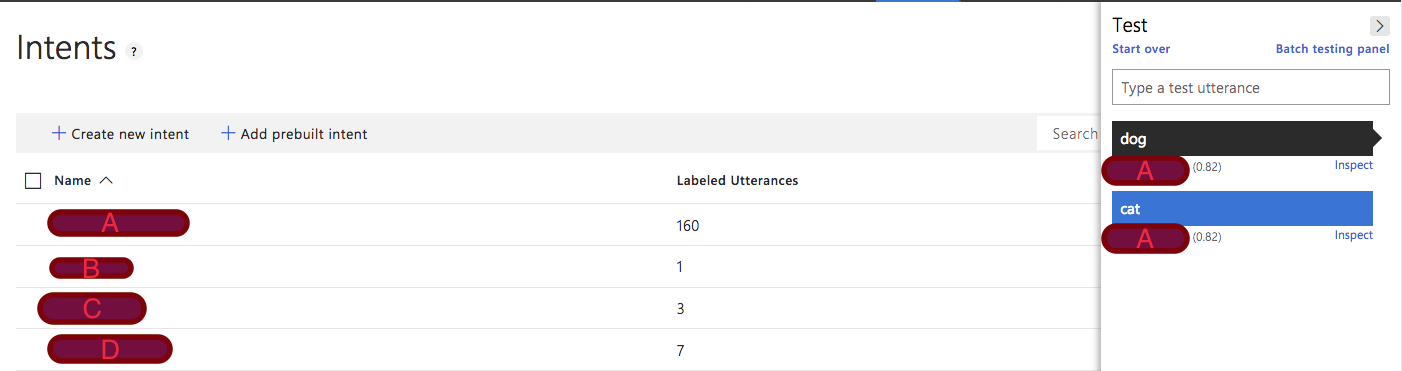
示例:如果
- 意图A由诸如动物之类的话语组成
- 意图B由诸如水果之类的话语组成。
- 意图C由诸如昆虫之类的话语组成
- 意图D由诸如人的名字之类的话语组成
理想的:如果随机词不符合任何路易斯意图,它将符合无路易斯意图。想要的例子:如果输入诸如“情感”或“衣服”这样的词,它将与“无”意图相匹配。
实际:当用户键入随机词时,它与luis匹配,标记的语句数量最多。如果输入了诸如“情感”这样的词,它将与"A“意图相匹配,因为意图A包含了数量最多的标记话语。
请就这个问题提出建议。
回答 2
Stack Overflow用户
发布于 2018-10-31 16:53:22
设置一个得分阈值,低于这个阈值,应用程序将不会显示对用户的任何响应(或者显示“对不起,我没有收到您”的消息)。这就避免了用LUIS不确定的内容来响应用户,这通常也会处理大量的“非主题”输入。
我建议将其设定为0.3至0.7之间,视主题的严重性而定。这不是LUIS中的配置选项,而是在您的代码中只需这样做:
if(result.score >=0.5) {
// show response based on intent.
} else {
// ask user to rephrase
}另外,你的意图似乎很不平衡。你想要尝试,并有大致相同的数量的每一个意图,在10到20之间,理想的。
Stack Overflow用户
发布于 2018-10-02 21:12:06
因此,如果没有更多关于你如何建立语言模型的细节,最基本的问题可能是,你要么在每个意图中没有足够的话语,而这些意图有足够的变化,显示出不同的表达方式可以用来表达特定的意图。
变体是指不同的话语长度(字数)、不同的语序、时态、语法正确性等(医生来了)。
记住,每个意图应该在上至少有15个话语,。
此外,正如最佳实践中所述,您是否也确保在您的“无意图”中包括示例语句?最佳实践声明,您应该在应用程序的其他部分中,每10个语句中就有一个无语句。
最终:构建你的应用程序,这样你的意图就足够清晰,你的意图中包含了不同的例子话语,这样当你测试其他的话语时,路易斯就更有可能与你的不同意图相匹配--如果你输入一个不遵循你不同意图的任何模式或上下文的话语,路易斯就会知道如何检测到你的“无”意图。
如果您需要更具体的帮助,请张贴您的语言模型的JSON。
https://stackoverflow.com/questions/52584529
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号