
Softmax回归梯度
Softmax回归梯度
提问于 2018-10-08 07:15:05
在Ufldl软件最大回归中,成本函数的梯度是
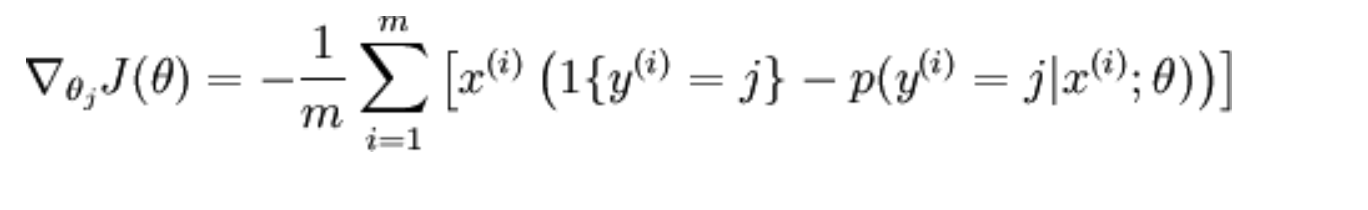
我试图用Python实现它,但我的损失几乎没有改变:
def update_theta(x, y, theta, learning_rate):
# 4 classes, 3 features
theta_gradients = np.zeros((4, 3)).astype(np.float)
for j in range(4):
for i in range(len(x)):
# p: softmax P(y = j|x, theta)
p = softmax(sm_input(x[i], theta))[y[i]]
# target function {y = j}
p -= 1 if y[i] == j else 0
x[i] = p * x[i]
# sum gradients
theta_gradients[j] += x[i]
theta_gradients[j] = theta_gradients[j] / len(x)
theta = theta.T - learning_rate * theta_gradients
return theta.T我的前10个时代失去了和acc:
1.3863767797767788
train acc cnt 3
1.386293406734411
train acc cnt 255
1.3862943723056675
train acc cnt 3
1.3862943609888068
train acc cnt 255
1.386294361121427
train acc cnt 3
1.3862943611198806
train acc cnt 254
1.386294361119894
train acc cnt 4
1.3862943611198937
train acc cnt 125
1.3862943611198937
train acc cnt 125
1.3862943611198937
train acc cnt 125我不知道我是否误解了等式,任何建议都会很感激!
回答 1
Stack Overflow用户
回答已采纳
发布于 2018-10-11 09:10:03
是否总是在theta_gradients函数中初始化您的update_theta?
通常情况下,梯度的每一步都应该从以前的θ中学习。
作为一个例子:
def step_gradient(theta_current, X, y, learning_rate):
preds = predict_abs(theta_current, X)
theta_gradient = -(2 / len(y)) * np.dot(X.T, (y - preds))
theta = theta_current - learning_rate * theta_gradient
return theta页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/52697182
复制相关文章
相似问题
腾讯云开发者
