
为什么我的深Q网和双深Q网不稳定?
我正在尝试实现DQN和DDQN(都有经验的答复)来解决OpenAI AI-GymCart极地环境.这两种方法有时都能够学习和解决这个问题,但并非总是如此。
我的网络只是一个前馈网络(我尝试使用1和2个隐藏层)。在DDQN中,我在DQN中创建了一个网络,在DDQN中创建了两个网络,一个评估Q值的目标网络和一个选择最佳动作的主网络,训练主网络,并在一些事件发生后将其复制到目标网络。
DQN的问题是:
- 有时它能在100集内达到完美的200分,但有时它被卡住了,不管训练多长时间,它只能达到10分。
- 此外,在成功学习的情况下,学习速度不同。
DDQN的问题是:
- 它可以学会达到200分,但它似乎忘记了所学到的,分数急剧下降。
我试过调整批处理大小、学习速度、隐藏层中神经元的数量、隐藏层的数量、探测速率,但是不稳定仍然存在。
关于网络的大小和批处理的大小有什么经验法则吗?我认为合理的更大的网络和更大的批量将增加稳定性。
是否有可能使学习稳定?如有任何评论或参考,敬请见谅!
回答 4
Stack Overflow用户
发布于 2018-10-19 12:36:00
这种问题经常发生,你不应该放弃。首先,当然,您应该再检查一到两次代码是否正常--尝试将您的代码与其他实现进行比较,查看丢失函数的行为等等。如果您非常确定您的代码都很好--而且,正如您说的那样,模型可以不时地学习该任务,很可能--您应该开始对超参数进行实验。
你的问题似乎与超参数有关,如探索技术、学习速度、更新目标网络的方式以及经验回放记忆。我不会玩弄隐藏的图层大小--找到模型学习过一次的值,并将它们固定下来。
- 探索技术:,我想你使用的是贪婪策略。我的建议是从一个高epsilon值开始(我通常从1.0开始),并在每一步或每一集之后对其进行衰减,但也定义一个epsilon_min。从低感受器值开始,可能是学习速度和成功率不同的问题--如果你完全随机,你总是在开始时用类似的转换填充你的记忆。随着较低的epsilon率在开始,有一个更大的机会,您的模型没有充分探索之前,开发阶段开始。
- 学习率:确保它不太大。较小的学习速度可能会降低学习速度,但有助于学习模型避免从全局最小值返回到一些局部的、更差的模型。此外,像用亚当计算的这些自适应学习率可能会帮助您。当然,批量大小也有影响,但我会保持它的固定和担心,只有当其他的超参数改变将无法工作。
- 目标网络更新(速率和价值):--这也是一个重要的问题。您必须进行一些实验--不仅要多久执行更新一次,还要尝试将多少主值复制到目标值中。人们通常每一集都会做一次硬更新,但如果第一项技术不起作用,则尝试进行软更新。
- 体验重放:你使用它吗?你应该这样做。你的内存有多大?这是非常重要的因素,内存大小会影响稳定性和成功率(更深层次的体验回放)。基本上,如果你注意到算法的不稳定性,尝试一个更大的内存大小,如果它对你的学习曲线有很大的影响,那就试试上面提到的技术。
Stack Overflow用户
发布于 2018-10-16 19:28:20
也许这能帮你解决你在这个环境中的问题。
Stack Overflow用户
发布于 2020-03-26 19:30:42
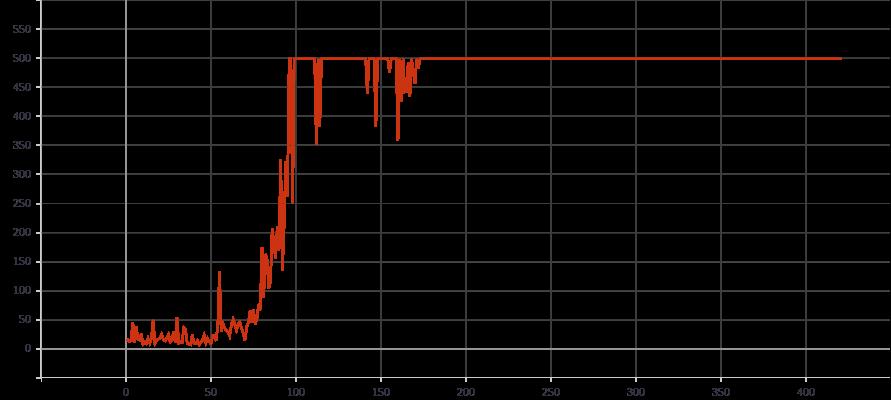
我还认为问题是不稳定的(D)DQN,或者"CartPole“是被窃听的,或者是”不稳定的可解决的“!
在搜索了几个星期之后,我检查了我的代码好几次,除了一个.
- 折扣因素,把它设置为1.0 (真的),使我的训练更加稳定了在卡波尔-v1的500多个步骤。
- 在一个简单的q-学习者(将min-alpha和min-epsilon减少到0.001)的训练中,Cartpold-v1是稳定的:https://github.com/sanjitjain2/q-learning-for-cartpole/blob/master/qlearning.py。
- 创建者的Gamma在1.0 (我在reddit上读到过),所以我从这里用一个简单的DQN (double_q = False)测试了它:tensorflow2.py
我还删除了一行:# reward = np.random.normal(1.0, RANDOM_REWARD_STD)
这样,它得到了正常的+1每步奖励和“稳定”7的10分。
其结果是:
https://stackoverflow.com/questions/52770780
复制相似问题
腾讯云开发者
