
回忆录在硬币兑换问题中的应用
回忆录在硬币兑换问题中的应用
提问于 2018-10-22 18:23:15
我正在尝试解决以下问题(来自CodeRust 3.0):
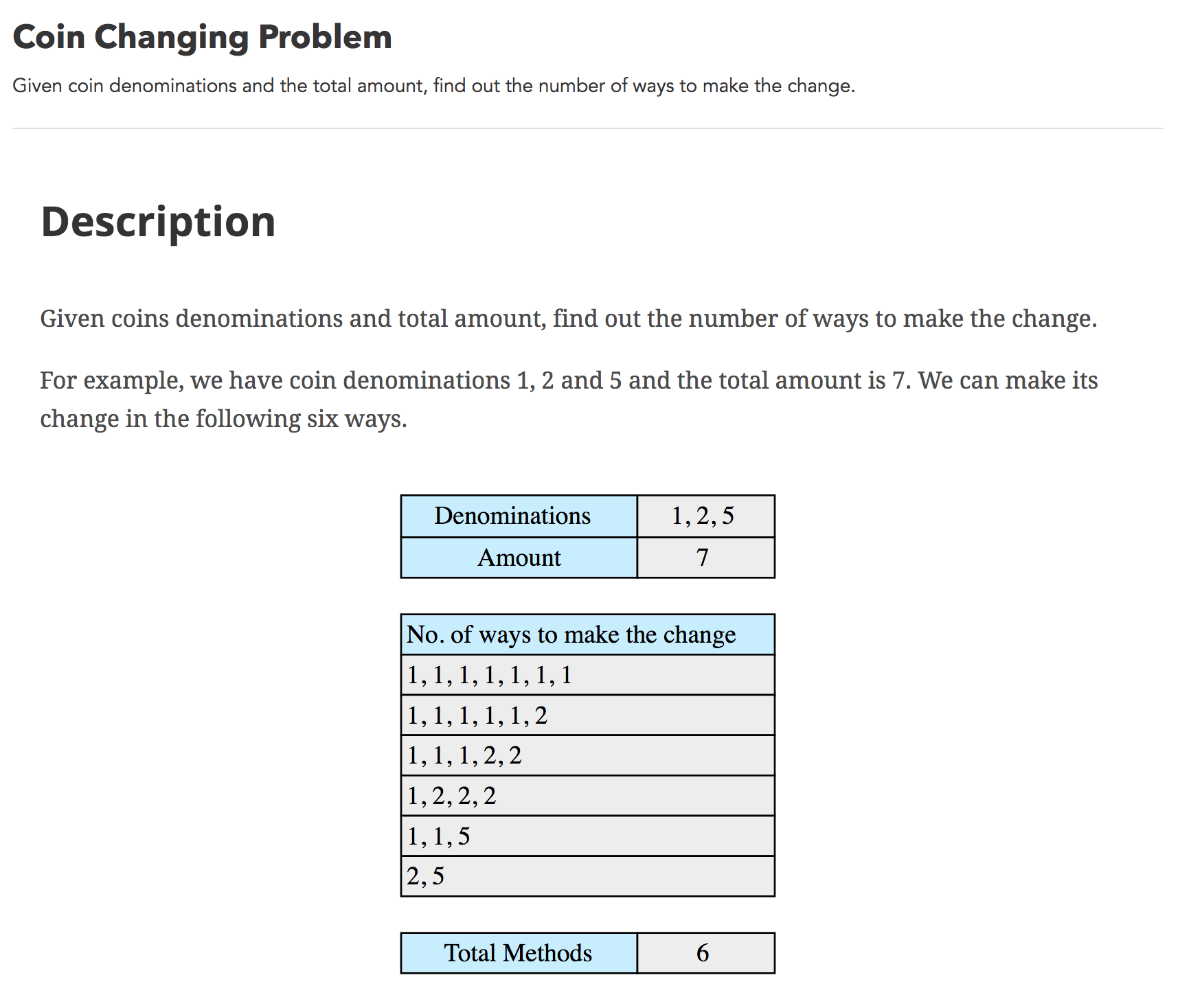
我想我应该使用以下递归关系:在这个例子中,使用(1, 2, 5)生成7的方法的数量是使0, 1, ..., 7与面额(2, 5)的方法的数目之和(也就是说,对于第一枚硬币的数量,1的每一个选择,对一组较小的面额进行递归调用)。
为了应用回忆录,我想我应该使用functools.lru_cache()。到目前为止,这是我的解决方案(包括pytest单元测试):
import pytest
import functools
@functools.lru_cache()
def solve_coin_change_dp(denominations, amount):
if amount == 0:
return 1
if amount < 0:
return 0
if not denominations:
return 0
return sum(
solve_coin_change_dp(
denominations[1:],
amount - i * denominations[0])
for i in range(amount // denominations[0] + 1))
@pytest.fixture
def denominations():
return (1, 2, 5)
def test_trivial():
assert solve_coin_change_dp((1,), 1) == 1
def test_1(denominations):
assert solve_coin_change_dp(denominations, 1) == 1
def test_2(denominations):
assert solve_coin_change_dp(denominations, 2) == 2
def test_3(denominations):
assert solve_coin_change_dp(denominations, 3) == 2
def test_4(denominations):
assert solve_coin_change_dp(denominations, 4) == 3
def test_5(denominations):
assert solve_coin_change_dp(denominations, 5) == 4
def test_7(denominations):
assert solve_coin_change_dp(denominations, 7) == 6
def test_big_amount(denominations):
solve_coin_change_dp(denominations, 1000)
if __name__ == "__main__":
pytest.main([__file__, '--duration', '1'])问题是,lru_cache似乎根本没有帮助快速实现。对于1000的输入,程序仍然需要10s才能运行:
coin_changing.py ........ [100%]
=========================== slowest 1 test durations ===========================
10.31s call coin_changing.py::test_big_amount
========================== 8 passed in 10.35 seconds ===========================然而,如果我考虑函数调用,我会认为回忆录会产生“节约”。例如,带有参数(1, 2, 5), 5的调用将导致(2, 5), 5、(2, 5), 4、(2, 5), 3、(2, 5), 2、(2, 5), 1和(2, 5), 0。其中的第一个和第三个应该在某个时候导致(5,), 3,其中一个点可以使用缓存的结果。
总之,为什么这个回忆录的应用不起作用?
回答 1
Stack Overflow用户
回答已采纳
发布于 2018-10-22 18:27:52
lru_cache是一个LRU缓存。与前面一样,当缓存已满且需要插入新元素时,它会驱逐最近使用最少的元素。默认的缓存大小是128。你的回忆录结果被逐出了。
将maxsize=None设置为使用无限制的、非LRU缓存:
@lru_cache(maxsize=None)
def ...页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/52935521
复制相关文章
相似问题
腾讯云开发者
