为具有柔性形状的CoreML 2模型指定输入/输出尺寸
我设法创建了一个具有灵活输入/输出形状大小的CoreML 2.0模型:
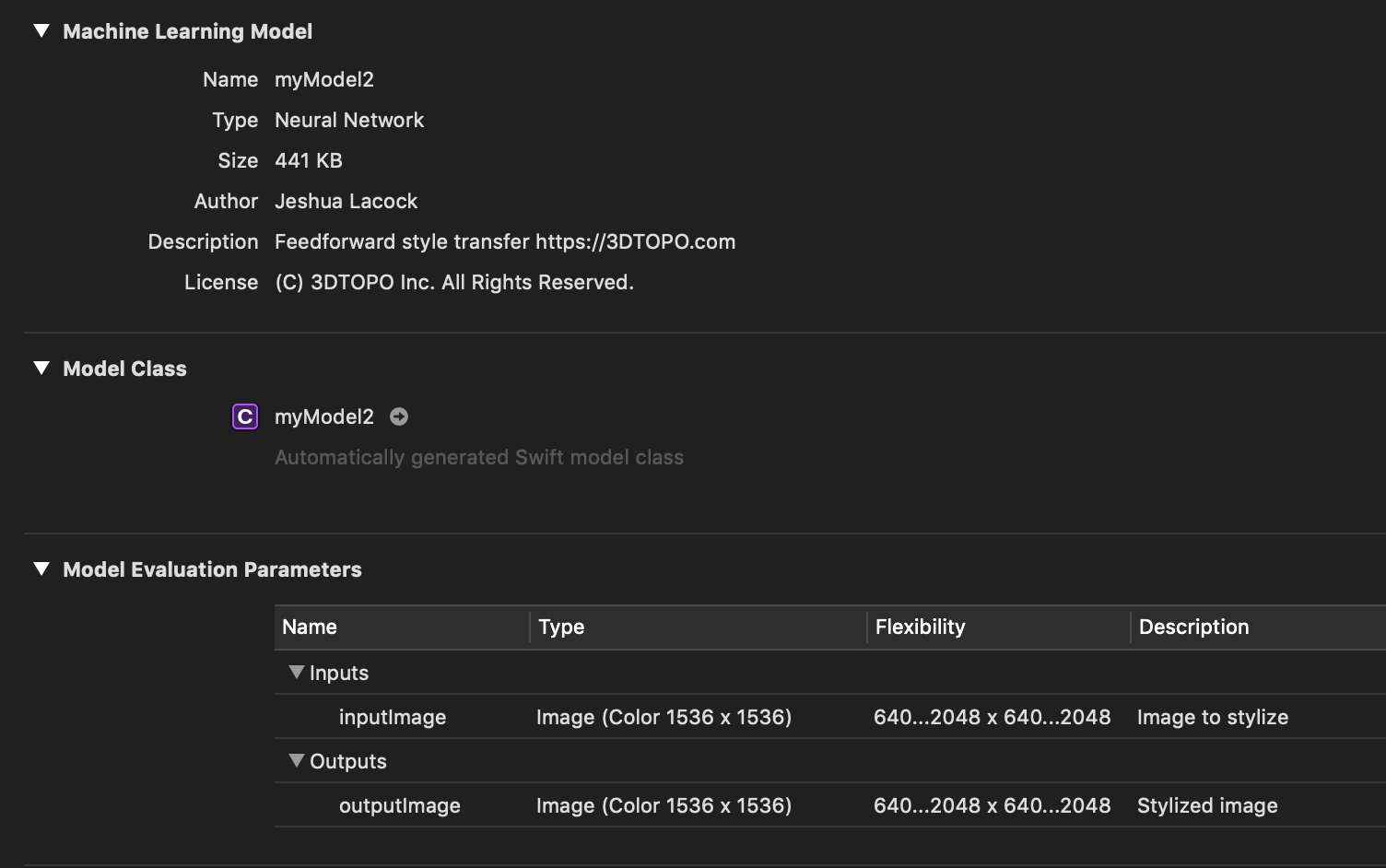
但是,我不知道如何在我的Xcode项目中设置大小。如果设置输入像素缓冲区大小2048x2048,则输出像素缓冲区仍为1536x1536。如果将其设置为768x768,则结果像素缓冲区仍为1536x1536,但在768x768区域外为空白。
我检查了自动生成的Swift模型类,没有看到任何线索。
我在任何地方都找不到一个例子,说明如何使用“灵活性”大小。
在WWDC 2018年会议708“核心ML中的新内容”中,第1部分指出:
这意味着,现在您必须交付一个单一的模式。你不必有任何多余的代码。如果您需要在标准定义和高清晰度之间切换,您可以更快地完成它,因为我们不需要从头开始重新加载模型;我们只需要调整它的大小。您有两个选项来指定模型的灵活性。可以为其维度定义范围,因此可以定义最小宽度和高度以及最大宽度和高度。然后在推理中选择介于两者之间的任何值。但还有另外一种方法。您可以枚举要使用的所有形状。例如,所有不同的高宽比,所有不同的分辨率,这是更好的性能。核心ML更早地了解您的用例,所以它可以--它有机会执行更多的优化。
他们说“我们只需要调整它的大小”。这太让人沮丧了,因为他们不告诉你怎么调整尺寸!他们还说,“然后在推断之间挑选任何价值”,但没有提供任何线索,如何在两者之间选择价值!
下面是我如何添加灵活的形状大小:
import coremltools
from coremltools.models.neural_network import flexible_shape_utils
spec = coremltools.utils.load_spec('mymodel_fxedShape.mlmodel')
img_size_ranges = flexible_shape_utils.NeuralNetworkImageSizeRange()
img_size_ranges.add_height_range(640, 2048)
img_size_ranges.add_width_range(640, 2048)
flexible_shape_utils.update_image_size_range(spec, feature_name='inputImage', size_range=img_size_ranges)
flexible_shape_utils.update_image_size_range(spec, feature_name='outputImage', size_range=img_size_ranges)
coremltools.utils.save_spec(spec, 'myModel.mlmodel')下面是模型的描述:
description {
input {
name: "inputImage"
shortDescription: "Image to stylize"
type {
imageType {
width: 1536
height: 1536
colorSpace: BGR
imageSizeRange {
widthRange {
lowerBound: 640
upperBound: 2048
}
heightRange {
lowerBound: 640
upperBound: 2048
}
}
}
}
}
output {
name: "outputImage"
shortDescription: "Stylized image"
type {
imageType {
width: 1536
height: 1536
colorSpace: BGR
imageSizeRange {
widthRange {
lowerBound: 640
upperBound: 2048
}
heightRange {
lowerBound: 640
upperBound: 2048
}
}
}
}
}
}有两个使用“outputShape”的层:
layers {
name: "SpatialFullConvolution_63"
input: "Sequential_53"
output: "SpatialFullConvolution_63_output"
convolution {
outputChannels: 16
kernelChannels: 32
nGroups: 1
kernelSize: 3
kernelSize: 3
stride: 2
stride: 2
dilationFactor: 1
dilationFactor: 1
valid {
paddingAmounts {
borderAmounts {
}
borderAmounts {
}
}
}
isDeconvolution: true
hasBias: true
weights {
}
bias {
}
outputShape: 770
outputShape: 770
}
}
...relu layer...
layers {
name: "SpatialFullConvolution_67"
input: "ReLU_66"
output: "SpatialFullConvolution_67_output"
convolution {
outputChannels: 8
kernelChannels: 16
nGroups: 1
kernelSize: 3
kernelSize: 3
stride: 2
stride: 2
dilationFactor: 1
dilationFactor: 1
valid {
paddingAmounts {
borderAmounts {
}
borderAmounts {
}
}
}
isDeconvolution: true
hasBias: true
weights {
}
bias {
}
outputShape: 1538
outputShape: 1538
}
}我现在正试图弄清楚如何从这两个层中删除outputShape。
>>> layer = spec.neuralNetwork.layers[49]
>>> layer.convolution.outputShape
[1538L, 1538L]我试着把它设置为[]:
layer.convolution.outputShape = []以一种形状:
layer.convolution.outputShape = flexible_shape_utils.Shape(())无论我尝试什么,我都会犯错误:
TypeError: Can't set composite field我是否必须创建一个新的层,然后将其链接到输出到它的层和它输出到的层?
回答 1
Stack Overflow用户
发布于 2022-08-01 23:40:52
本例中的问题是,模型中存在一些层,它们的outputShapes使用固定的形状。例如:
>>> layer = spec.neuralNetwork.layers[49]
>>> layer.convolution.outputShape
[1538L, 1538L]所讨论的模型确实是完全卷积的,因此在转换到CoreML之前,它可以处理任何输入和输出形状。
我能够使用以下命令删除固定的outputShape:
layer = spec.neuralNetwork.layers[49]
del layer.convolution.outputShape[:]在此之后,模型具有灵活的输入和输出形状。
这个答案的所有功劳都归功于马蒂杰斯·霍勒曼人。
https://stackoverflow.com/questions/53096060
复制相似问题
腾讯云开发者
