
使用管道将多个文件读入单个列表
使用管道将多个文件读入单个列表
提问于 2018-11-16 14:09:43
我有一个数字简单的文件,每行只有一个条目,我想把这些文件读入一个列表中,文件的内容作为向量。
> list(file_one = c(1,2,3,4), file_two = c(9,99,999))
$file_one
[1] 1 2 3 4
$file_two
[1] 9 99 999
...这基本上是我想要的结果格式。到目前为止,我得到的是一个类似的结果,但不正确:
> list.files("/home/x/y/z", pattern="^rep.*List$", full.names=TRUE) %>% lapply(read.table)
[[1]]
V1
1 a
2 b
3 c
4 d如何以正确的格式读取数据或从这里转换数据?-最好有一个“管道”来读取数据:
- 列表文件
- 以正确的格式读取文件或
- 将读取的数据格式化为命名向量列表。
回答 2
Stack Overflow用户
回答已采纳
发布于 2018-11-16 16:02:55
也许你需要这样的东西
library(tidyverse)
list.files("xyz/", full.names = TRUE) %>%
set_names(basename(.)) %>%
map(read_lines)
#> $`rep1List`
#> [1] "a" "b" "c" "d" "e" "f"
#>
#> $rep2List
#> [1] "e" "f" "g" "h" "i" "j" "k"
#>
#> $rep3List
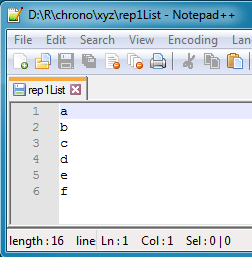
#> [1] "l" "m" "m" "o" "p" "q" "r" "s"其中的每个文件如下所示:
Stack Overflow用户
发布于 2018-11-16 15:47:48
根据您提供的信息,我将使用purrr包尝试如下所示:
list.files("/home/x/y/z", pattern="^rep.*List$", full.names = TRUE) %>%
purrr::map_df(., read.table, ADD YOUR ARGUMENTS HERE)对我来说,这是一个真实的例子。它在你虚构的文件中失败。我本想评论一下,但我太低了。^^
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/53339488
复制相关文章
相似问题
腾讯云开发者
