
Gensim Word2Vec模型在相同环境和平台下的两个编辑器中的不同结果
我正在尝试应用Windows10机器python3.7中的gensim 3.6库中实现的word2vec模型。在执行预处理后,我有一个句子列表(每个句子都是一个单词列表)作为模型的输入。
我在Anaconda's Spyder中计算了结果(使用Anaconda's Spyder获得了一个给定输入词的10个最相似的单词),然后是Sublime Text编辑器。
但是,对于在两个编辑器中执行的相同源代码,我得到了不同的结果。
我需要选择的结果是什么以及为什么选择
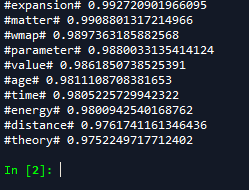
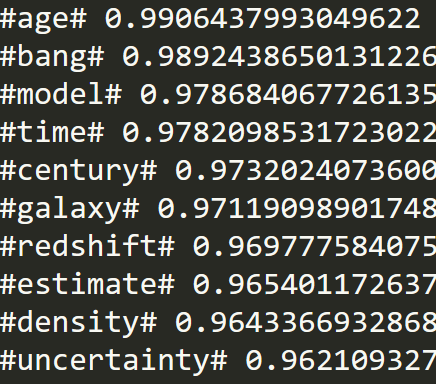
我正在指定通过在spyder和崇高文本中运行相同的代码获得的结果的屏幕截图。我需要获得10个最相似的单词的输入单词是#universe#
我真的很困惑如何选择结果,是基于什么呢?另外,我最近开始学习Word2Vec。
如有任何建议,将不胜感激。
在Spyder获得的结果:
使用崇高文本获得的结果:
回答 1
Stack Overflow用户
发布于 2018-12-04 20:39:17
Word2Vec算法在内部利用随机化。此外,当(与通常的效率训练一样)训练分散在多个线程上时,引入了一些额外的表示顺序随机化。这意味着,即使在完全相同的环境中,两次运行也会有不同的结果。
如果培训是有效的--足够的数据、适当的参数、足够的培训通行证--所有这些模型在做类似于单词相似的事情时都应该具有相似的质量,即使实际的单词会在不同的地方。在单词的相对排名中会有一些抖动,但结果应该大致相似。
您的结果与'universe'有着模糊的联系,但并不令人印象深刻,而且在不同的运行中差异很大,这表明您的数据、参数或培训数量可能存在问题。(我们预计结果会略有变化,但不会有那么多变化。)
你有多少数据?(Word2Vec从许多不同的词汇用法示例中获益。)
您是否保留了罕见的单词,使min_count低于它的缺省值5?(这些词往往得不到好的向量,也会干扰附近单词向量的改进。)
你想做很大的向量吗?(较小的数据集和较小的词汇表只能支持较小的向量。过大的向量允许“过度拟合”,在这里,数据的特性是记忆的,而不是学习到的广义模式。或者,它们允许模型在许多不同的非竞争性方向上继续改进,因此模型的结束任务/相似结果在运行到运行时可能有很大的不同,即使每个模型在其内部单词预测任务上都做得很好。)
您是否使用默认的epochs=5,即使使用一个小的数据集?(大的、多样的数据集需要更少的培训通行证-因为所有的单词都会多次出现,至少在整个数据集中都会出现。如果你试图从更薄的数据中提取结果,那么更多的epochs可能帮助不大--但不如更多样化的数据那么多。)
https://stackoverflow.com/questions/53618906
复制相似问题
腾讯云开发者
