
熊猫融化多索引数据集和重置指数-为什么这是工作的?
熊猫融化多索引数据集和重置指数-为什么这是工作的?
提问于 2018-12-24 20:03:11
我直接从熊猫文档中创建了这个数据集:
In [28]: columns = pd.MultiIndex.from_tuples([('A', 'cat'), ('B', 'dog'),
....: ('B', 'cat'), ('A', 'dog')],
....: names=['exp', 'animal'])
....:
In [29]: index = pd.MultiIndex.from_product([('one', 'two'),
('bar', 'baz', 'foo', 'qux')
....: ],
....: names=['first', 'second'])
....:
In [30]: df = pd.DataFrame(np.random.randn(8, 4), index=index, columns=columns)MultiIndex数据集(包括列和行)如下所示:
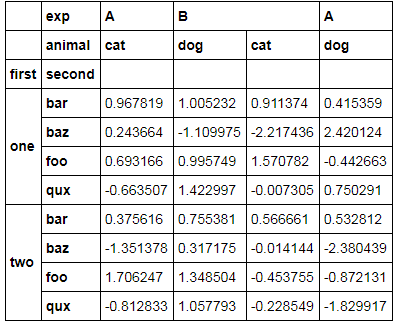
我想说到这样的东西--图像被截断了,但是你明白了
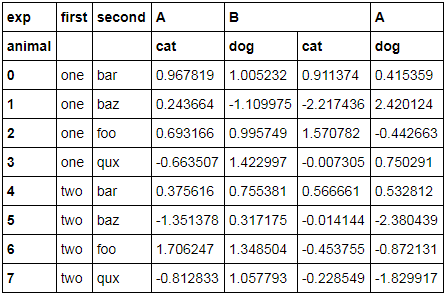
可能有无数种方法来重塑这个过程,但是我希望使用un堆栈()和melt()来完成它。
这是我想出的两种方法:
1. pd.melt(df.reset_index(),id_vars=['first','second'])
2. pd.melt(df.unstack().reset_index(),id_vars=['first'])这就是我被困在这里的地方:,为什么这样做?
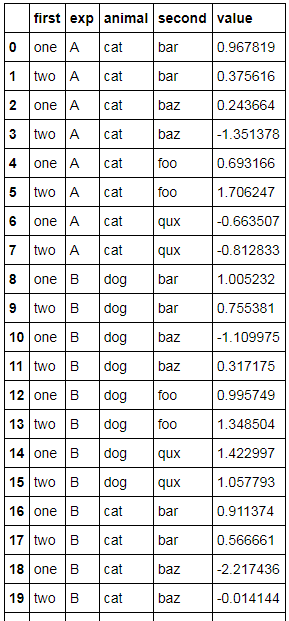
df.reset_index()给了我这个数据
用这些列

“第一”和“第二”不出现在列的名称中。它们实际上是列exp的级别。所以我想知道如果我在熔体中给id_vars增加更多的水平会发生什么
如果我把熔体换成
pd.melt(df.reset_index(),id_vars=['first','second','A'])我得到以下错误:
ValueError:数组必须都是相同的长度
如果我把熔体换成
pd.melt(df.reset_index(),id_vars=['first','second','dog'])我得到以下错误:
KeyError:“狗”
有人能解释一下reset_index()在引擎盖下发生了什么吗?为什么不接受其他级别呢?为什么“第一”和“第二”显示为级别而不是列?
回答 1
Stack Overflow用户
回答已采纳
发布于 2018-12-24 20:05:40
有一个叫做stack的函数
yourdf=df.stack([0,1]).reset_index(name='value')页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/53917303
复制相关文章
相似问题
腾讯云开发者
