
如何将torchvision.datasets在GPU中创建的数据集放在一个操作中?
如何将torchvision.datasets在GPU中创建的数据集放在一个操作中?
提问于 2019-01-14 01:38:57
我正在处理CIFAR10,我使用torchvision.datasets来创建它。我需要GPU加速计算,但我无法同时将整个数据集放入GPU。我的模型需要使用迷你批次,而且单独处理每一批都很费时。
我试着把每一小批单独的GPU,但这似乎真的很费时。
回答 2
Stack Overflow用户
发布于 2019-01-14 12:34:59
TL;DR
一次移动整个数据集不会节省时间。
我不认为您一定要这样做,即使您有GPU内存来处理整个数据集(当然,按照今天的标准,CIFAR10是很小的)。
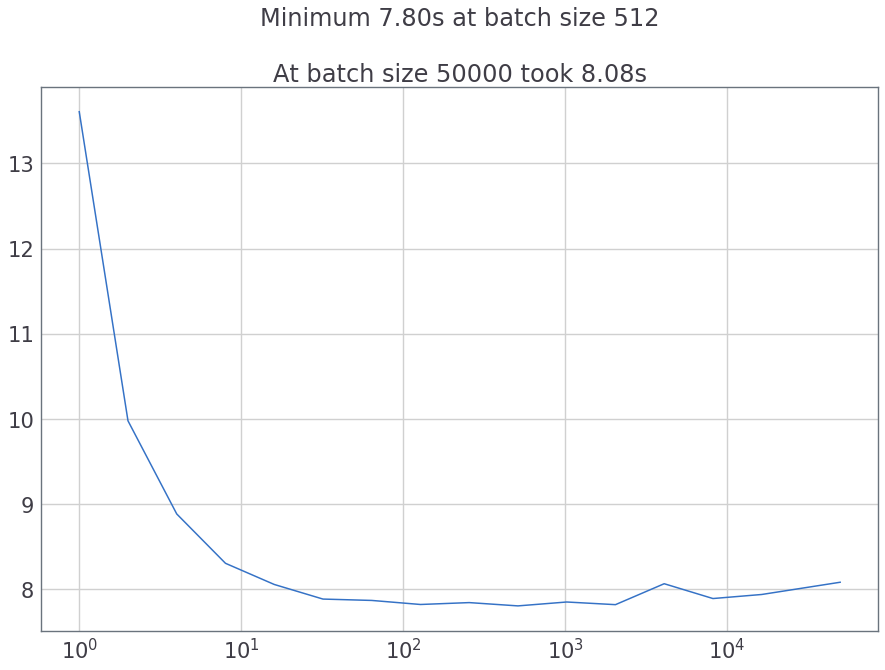
我尝试了不同的批处理大小,并按以下方式对传输到GPU的时间进行了计时:
num_workers = 1 # Set this as needed
def time_gpu_cast(batch_size=1):
start_time = time()
for x, y in DataLoader(dataset, batch_size, num_workers=num_workers):
x.cuda(); y.cuda()
return time() - start_time
# Try various batch sizes
cast_times = [(2 ** bs, time_gpu_cast(2 ** bs)) for bs in range(15)]
# Try the entire dataset like you want to do
cast_times.append((len(dataset), time_gpu_cast(len(dataset))))
plot(*zip(*cast_times)) # Plot the time taken对于num_workers = 1来说,这就是我得到的:
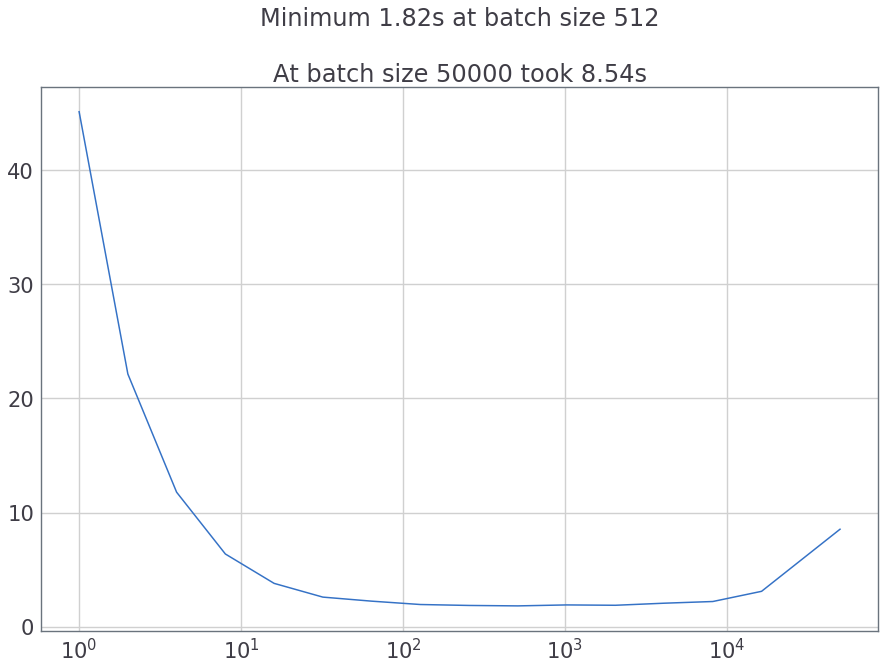
如果我们尝试并行加载(num_workers = 8),它将变得更加清晰:
Stack Overflow用户
发布于 2019-01-14 01:50:46
我有个答案,以后再试。看上去很有希望。
您可以编写dataset类,其中在init函数中红色整个数据集并应用所需的所有转换,并将它们转换为张量格式。然后,将这个张量发送到GPU (假设有足够的内存)。然后,在getitem函数中,您可以简单地使用索引检索已经在GPU上的张量的元素。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/54174854
复制相关文章
相似问题
腾讯云开发者
