
DataFrame持久化()错误java.lang.OutOfMemoryError:超过GC开销限制
DataFrame持久化()错误java.lang.OutOfMemoryError:超过GC开销限制
提问于 2019-02-14 05:43:19
当我试图持久化在大小为270 on的表上创建的带有错误的DataFrame时,Pyspark作业失败。
线程“纱线-调度程序-问号-am-线程池-9”中的异常: GC开销超出限制
只有当我尝试持久化时,才会发生此问题。下面是配置,我试着使用执行器/驱动程序内存、洗牌分区、动态分配执行器和持久化存储级别(DISK_ONLY、MEMORY_AND_DISK)。我的意图是在一个键上对数据进行分区并持久化,这样我的连续连接就会更快。任何建议都会有很大帮助。
火花版本: 1.6.1(MapR发行版)
数据大小:~270
Configuration:
spark.executor.instances - 300 spark.executor.memory - 10g spark.executor.cores - 3 spark.driver.memory - 10g spark.yarn.executor.memoryOverhead - 2048 spark.io.compression.codec - lz4 正常查询
query = "select * from tableA"
df = sqlctx.sql(query)
df.count()成功运行,没有持久化()
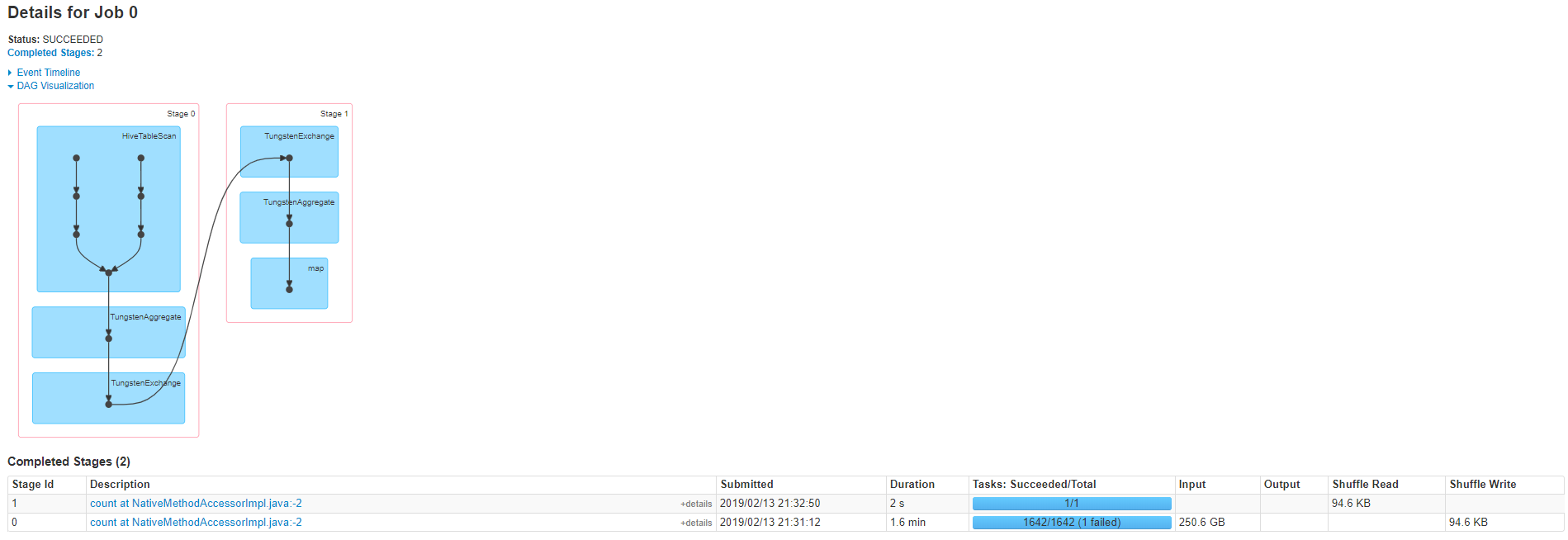
重新分区&持久化
记住洗牌块,选择2001年作为分区,这样每个分区将有大约128米的数据。
test = df.repartition(2001, "key")
test.persist(StorageLevel.DISK_ONLY)
test.count()GC错误- on持久化()
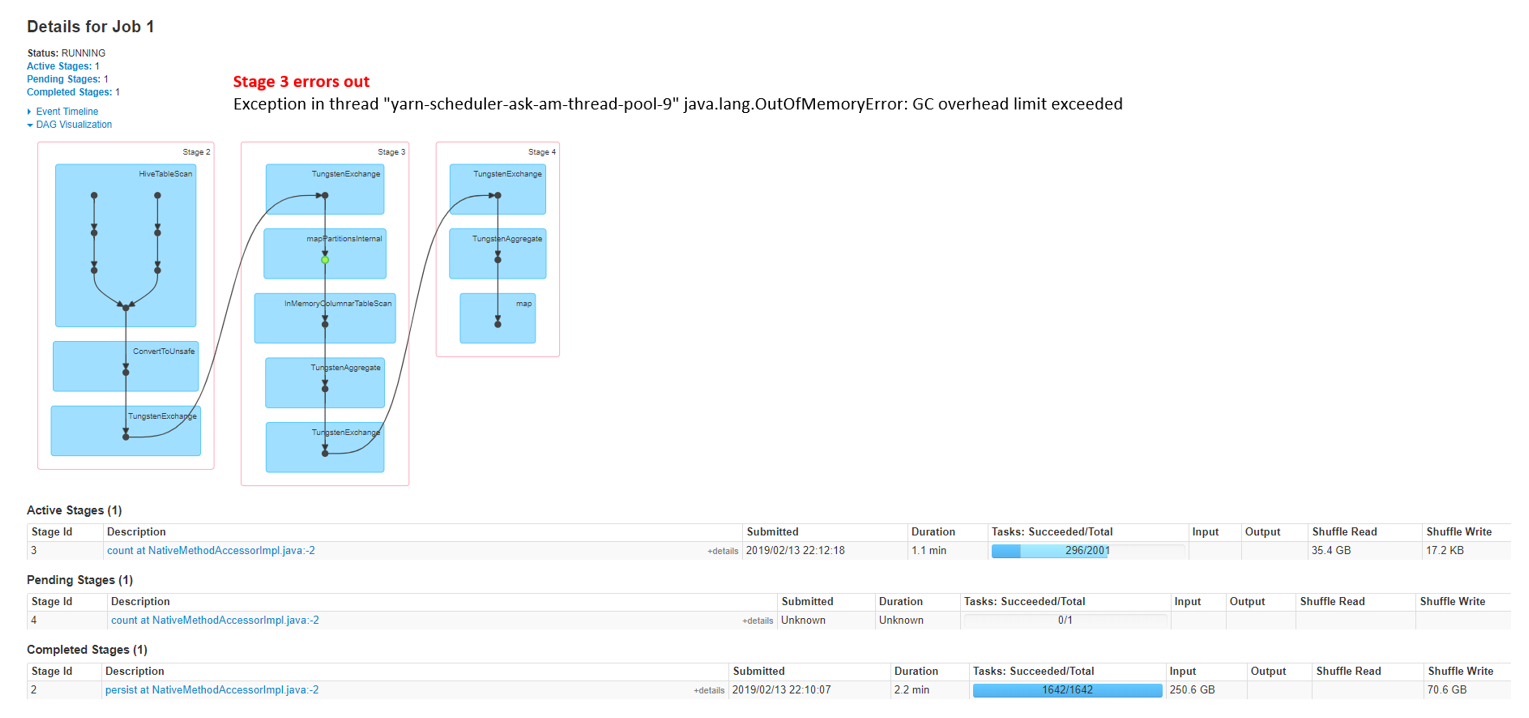
回答 1
Stack Overflow用户
发布于 2019-02-14 07:45:06
- 你试着把spark.executor.memory提高到最大值了吗?(如果集群有足够的内存)
- 您是否试图增加分区数以增加并行性?从而减小分区本身的大小。
还要分析垃圾收集发生的频率和GC花费的时间的统计数据。这文章对于分析和配置GC的工作将是非常有用的。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/54683895
复制相关文章
相似问题
腾讯云开发者
