一个国家的天气,地点bs4
一个国家的天气,地点bs4
提问于 2019-03-09 12:08:18
我试图使用这个网站https://www.timeanddate.com/weather/,使用BeautifulSoup4通过打开一个URL来抓取天气数据:
quote_page=r"https://www.timeanddate.com/weather/%s/%s/ext" %(country, place)我对网络抓取方法和BS4还不熟悉,我可以在页面的来源中找到我需要的信息(例如,我们把国家作为印度,在搜索中把城市作为孟买)链接为:https://www.timeanddate.com/weather/india/mumbai/ext
如果您看到页面的源代码,就不难使用CTRL+F并找到诸如“湿度”、“露点”和当前天气状况(如果天气晴朗、多雨等)等信息的属性,唯一阻碍我获取这些数据的是我对BS4的了解。
您能检查页面源并编写BS4方法来获取诸如“感觉”、“可见性”、“露点”、“湿度”、“风”和“预测”之类的信息吗?
注意:我以前做过一个数据抓取练习,在这里我必须使用‘<tag class="someclass">value</tag>’这样的HTML标记获取值。
a=BeautifulSoup.find(tag, attrs={'class':'someclass'})
a=a.text.strip()`回答 1
Stack Overflow用户
回答已采纳
发布于 2019-03-09 12:56:10
您可以熟悉css选择器。
import requests
from bs4 import BeautifulSoup as bs
country = 'india'
place = 'mumbai'
headers = {'User-Agent' : 'Mozilla/5.0',
'Host' : 'www.timeanddate.com'}
quote_page= 'https://www.timeanddate.com/weather/{0}/{1}'.format(country, place)
res = requests.get(quote_page)
soup = bs(res.content, 'lxml')
firstItem = soup.select_one('#qlook p:nth-of-type(2)')
strings = [string for string in firstItem.stripped_strings]
feelsLike = strings[0]
print(feelsLike)
quickFacts = [item.text for item in soup.select('#qfacts p')]
for fact in quickFacts:
print(fact)第一个选择器#qlook p:nth-of-type(2)使用id选择器来指定父元素,然后使用:nth-of type CSS伪类来选择其中的第二段类型元素(p标记)。
该选择器匹配:
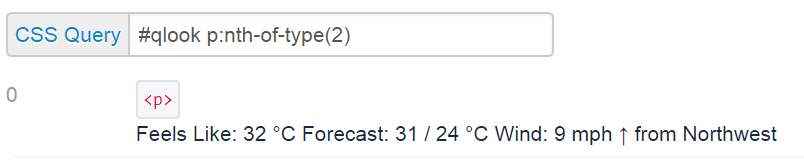
我使用stripped_strings来分离各个行,并按索引访问所需的信息。
第二个选择器#qfacts p对父元素使用id选择器,然后使用带有p 类型选择器的后代组合子指定子p标记元素。该组合与以下内容相匹配:
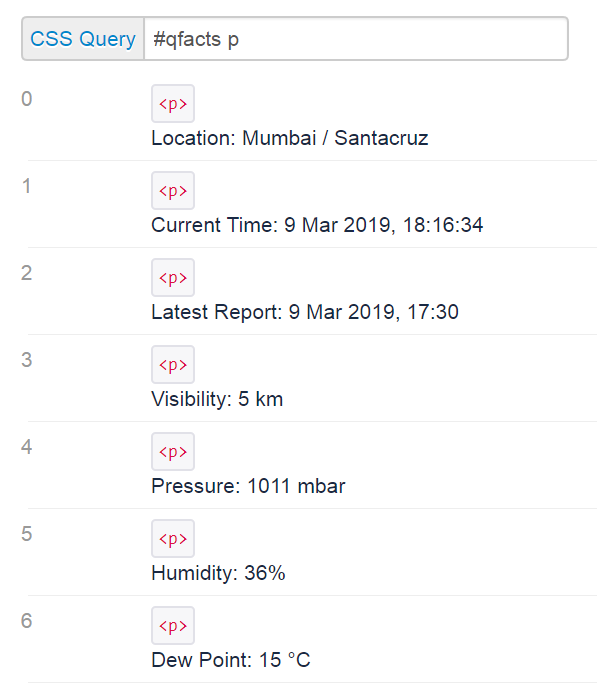
quickFacts表示这些匹配的列表。可以按索引访问项。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/55077185
复制相关文章
相似问题
腾讯云开发者
