
SSD盗梦空间v2。VGG16特性提取器是否被v2所取代?
SSD盗梦空间v2。VGG16特性提取器是否被v2所取代?
提问于 2019-05-28 11:30:19
回答 1
Stack Overflow用户
回答已采纳
发布于 2019-05-28 15:02:12
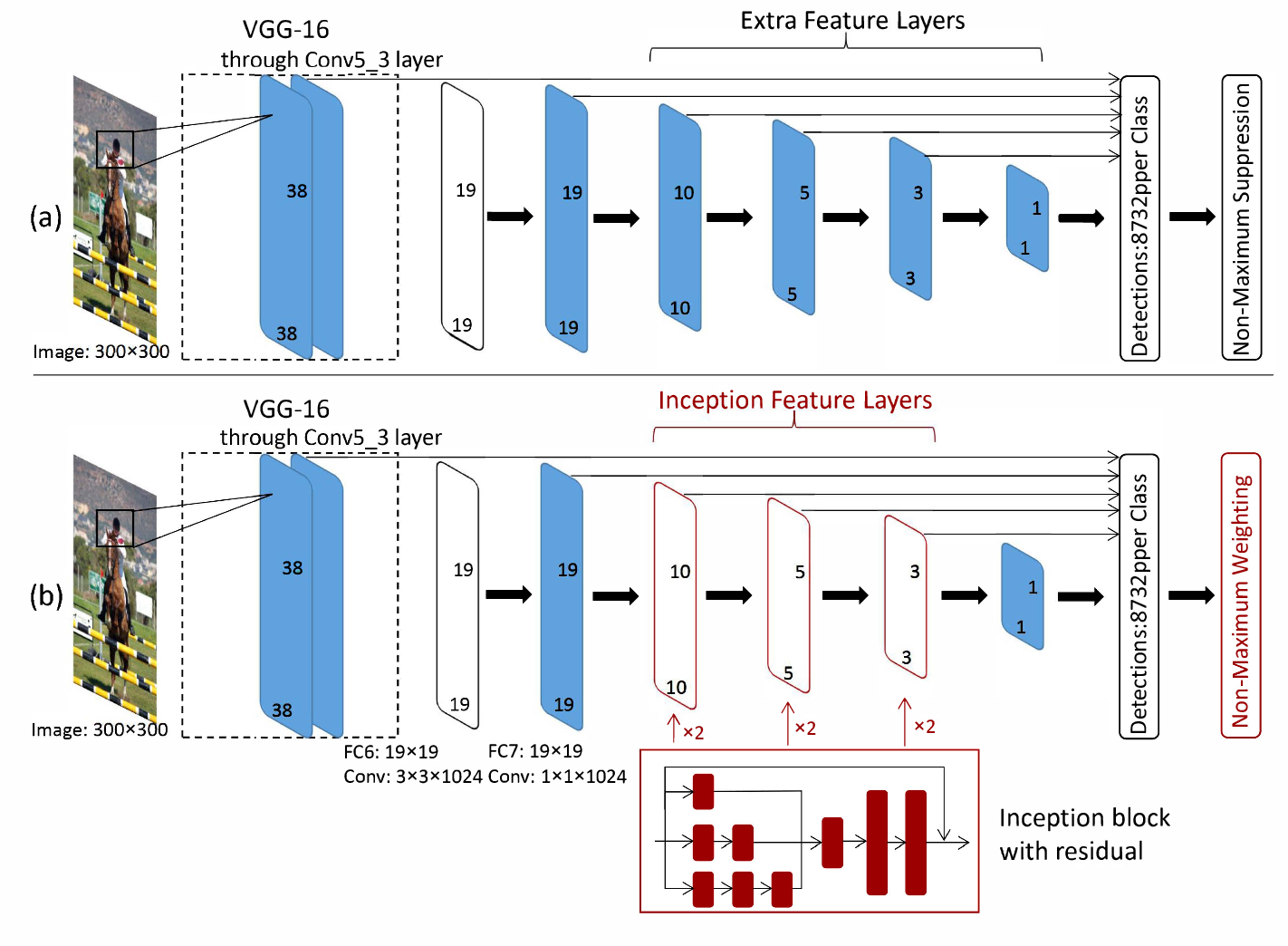
在tensorflow对象检测api中,ssd_inception_v2模型使用inception_v2作为特征提取器,即将第一个图形中的vgg16部分(图(a))替换为inception_v2。
在ssd模型中,feature extractor提取的特征层(即vgg16、inception_v2、mobilenet)将被进一步处理以产生不同分辨率的额外特征层。在上面的图(a)中,有6个输出特性层,前两个(19x19)直接取自feature extractor。其他4个层(10x10,5x5,3x3,1x1)是如何生成的?
它们是由额外的卷积运算生成的(这些conv操作有点像使用非常浅的特征提取器,不是吗?)实现细节为这里提供了良好的文档。在文件里写着
Note that the current implementation only supports generating new layers
using convolutions of stride 2 (resulting in a spatial resolution reduction
by a factor of 2)这样,额外的特征映射就会减少2倍,如果您读取函数multi_resolution_feature_maps,您将发现使用了slim.conv2d操作,这表明这些额外的层是通过额外的卷积层获得的(每个层只有一个层!)。
现在我们可以在你所链接的文件中解释什么是改进的。他们建议用启动块代替额外的特性层。这里没有inception_v2模型,而只是一个初始块。本文报道了利用起始块提高分类精度的方法。
现在应该清楚的是,vgg16、inceptioin_v2或mobilenet的ssd模型都很好,但是本文中的初始仅仅是指一个起始块,而不是初始网络。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/56341240
复制相关文章
相似问题
腾讯云开发者
