
根据列值的非模式特定序列检索未知值
根据列值的非模式特定序列检索未知值
提问于 2019-05-31 13:13:29
我希望根据它们的相关事件值返回和操作时间值,但只有在发生特定事件序列时才能这样做。下面是一个简化的示例表:
+--------+------------+-------+-------------+-------+-------------+-------+-------------+-------+-------------+-------+
| id | event1 | time1 | event2 | time2 | event3 | time3 | event4 | time4 | event5 | time5 |
+--------+------------+-------+-------------+-------+-------------+-------+-------------+-------+-------------+-------+
| abc123 | firstevent | 10:00 | secondevent | 10:01 | thirdevent | 10:02 | fourthevent | 10:03 | fifthevent | 10:04 |
| abc123 | thirdevent | 10:10 | secondevent | 10:11 | thirdevent | 10:12 | firstevent | 10:13 | secondevent | 10:14 |
| def456 | thirdevent | 10:20 | firstevent | 10:21 | secondevent | 10:22 | thirdevent | 10:24 | fifthevent | 10:25 |
+--------+------------+-------+-------------+-------+-------------+-------+-------------+-------+-------------+-------+对于此表,我们希望在发生特定事件序列时检索时间:firstevent、secondevent、thirdevent和任何非零值的最终事件。这意味着返回的相关条目如下:
+--------+------------+-------+-------------+-------+-------------+-------+-------------+-------+------------+-------+
| id | event1 | time1 | event2 | time2 | event3 | time3 | event4 | time4 | event5 | time5 |
+--------+------------+-------+-------------+-------+-------------+-------+-------------+-------+------------+-------+
| abc123 | firstevent | 10:00 | secondevent | 10:01 | thirdevent | 10:02 | fourthevent | 10:03 | null | null |
| null | null | null | null | null | null | null | null | null | null | null |
| def456 | null | null | firstevent | 10:21 | secondevent | 10:22 | thirdevent | 10:24 | fifthevent | 10:26 |
+--------+------------+-------+-------------+-------+-------------+-------+-------------+-------+------------+-------+如上面所示,列与序列的出现无关,从event1和event2列开始返回两个结果,因此解决方案应该是独立的,并且支持n个列。然后,这些值可以由三个固定变量之后发生的最终非零事件进行聚合,得到如下所示:
+-------------+-------------------------------+
| FinalEvent | AverageTimeBetweenFinalEvents |
+-------------+-------------------------------+
| fourthevent | 1:00 |
| fifthevent | 2:00 |
+-------------+-------------------------------+回答 1
Stack Overflow用户
回答已采纳
发布于 2019-05-31 19:51:33
下面是用于BigQuery标准SQL的
#standardSQL
WITH search_events AS (
SELECT ['firstevent', 'secondevent', 'thirdevent'] search
), temp AS (
SELECT *, REGEXP_EXTRACT(events, CONCAT(search, r',(\w*)')) FinalEvent
FROM (
SELECT id, [time1, time2, time3, time4, time5] times,
(SELECT STRING_AGG(event) FROM UNNEST([event1, event2, event3, event4, event5]) event) events,
(SELECT STRING_AGG(search) FROM UNNEST(search) search) search
FROM `project.dataset.table`, search_events
)
)
SELECT FinalEvent,
times[SAFE_OFFSET(ARRAY_LENGTH(REGEXP_EXTRACT_ALL(REGEXP_EXTRACT(events, CONCAT(r'(.*?)', search, ',', FinalEvent )), ',')) + 3)] time
FROM temp
WHERE IFNULL(FinalEvent, '') != '' 如果要应用于您的问题中的数据样本-结果是
Row FinalEvent time
1 fourthevent 10:03
2 fifthevent 10:25 因此,正如您所看到的,所有的最终事件都会随着各自的时间被提取出来。
现在,你可以在这里做任何你需要的分析--我不确定AverageTimeBetweenFinalEvents背后的逻辑,所以我把这个留给你们--特别是我认为问题的主要焦点是提取那些最后的事件。
你能提供这份声明背后的逻辑吗?
times[SAFE_OFFSET(ARRAY_LENGTH(REGEXP_EXTRACT_ALL(REGEXP_EXTRACT(events, CONCAT(r'(.*?)', search, ',', FinalEvent )), ',')) + 3)] time
当然,下面的希望有助于获得该表达式背后的逻辑。
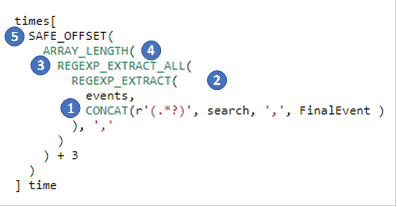
- 组装正则表达式以提取匹配事件之前发生的事件列表
- 提取这些事件
- 将所有逗号提取到数组中。
- 通过在上面的数组+3中取逗号来计算最终事件的位置(三是反映搜索序列中的位置数)
- 提取各自的时间作为时间数组的元素。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/56395798
复制相关文章
相似问题
腾讯云开发者
