
按日期累计
按日期累计
提问于 2019-07-03 11:57:02
我想知道一天有多少动物会出现。这张图表描述了人们预先注册动物的情况。
例如,在未来的7日子里,有人注册了他们的4猫在5/3/2019上出现;在未来的6天,另一个9猫被注册为5/3/2019。所以7+6=13猫会出现在5/3/2019上。
当days_ahead =0时,它只是指在事件日注册的人。例如,4狼在5/1/2019上注册了5/1/2019 (提前0天),那天会有4狼。
library(dplyr)
set.seed(0)
animal = c(rep('cat', 5), rep('dog', 6), rep('wolf', 3))
date = sample(seq(as.Date("2019/5/1"), as.Date('2019/5/10'), by='day'), 14, replace=TRUE)
days_ahead = sample(seq(0,14), 14, replace=FALSE)
number = sample.int(10, 14, replace=TRUE)
dt = data.frame(animal, date, days_ahead, number) %>% arrange(animal, date)预期的结果应该有与示例相同的1-3列,但是第四列应该是每个date的累加数,在days_ahead上累积。
我在这里添加了一个预期的结果。comments用于解释accumulated_number列。
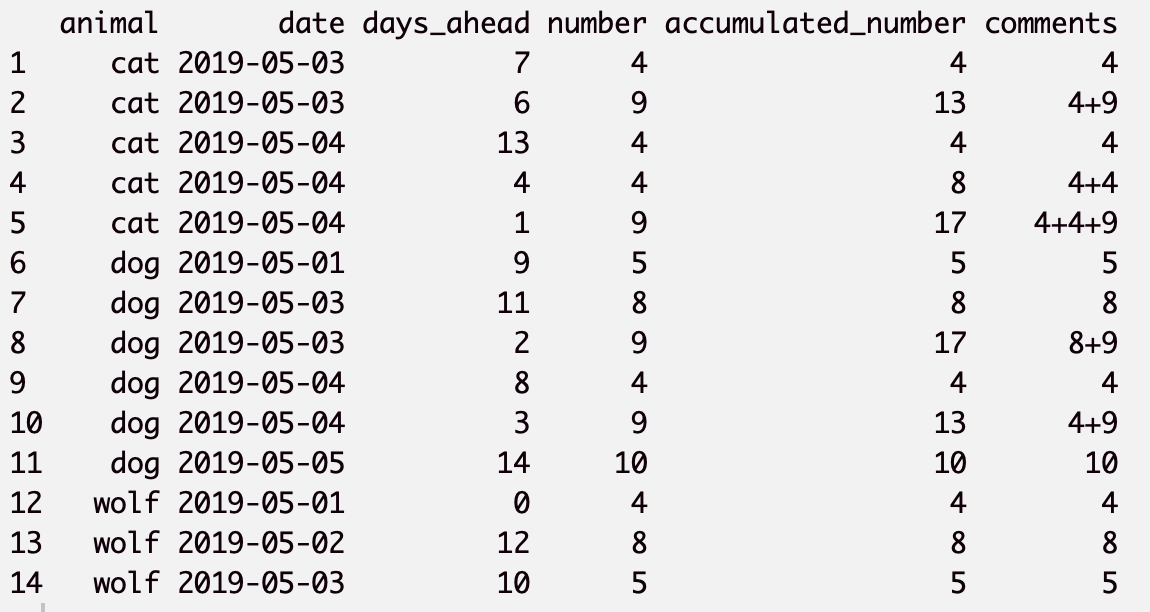
我考虑过loop函数,但不完全确定如何循环三个变量(cat、date和days_ahead)。如有任何建议,请见谅!!
回答 2
Stack Overflow用户
回答已采纳
发布于 2019-07-03 13:13:40
accumulated_number在cumsum()中有些简单。请参阅comments字段的链接:
Cumulatively paste (concatenate) values grouped by another variable
dt%>%
group_by(animal,date)%>%
mutate(accumulated_number = cumsum(number)
,comments = Reduce(function(x1, x2) paste(x1, x2, sep = '+'), as.character(number), accumulate = T)
)%>%
ungroup()而且,我的数据集与使用相同种子的数据集略有不同。尽管如此,这似乎是可行的。
# A tibble: 14 x 6
animal date days_ahead number accumulated_number comments
<fct> <date> <int> <int> <int> <chr>
1 cat 2019-05-03 10 9 9 9
2 cat 2019-05-04 6 4 4 4
3 cat 2019-05-06 8 5 5 5
4 cat 2019-05-09 5 4 4 4
5 cat 2019-05-10 13 6 6 6
6 dog 2019-05-01 0 2 2 2
7 dog 2019-05-03 3 5 5 5
8 dog 2019-05-07 1 7 7 7
9 dog 2019-05-07 9 8 15 7+8
10 dog 2019-05-09 12 2 2 2
11 dog 2019-05-10 7 9 9 9
12 wolf 2019-05-02 14 5 5 5
13 wolf 2019-05-03 11 8 8 8
14 wolf 2019-05-07 4 9 9 9 Stack Overflow用户
发布于 2019-07-03 12:08:04
我不太明白你的问题,这是你想要的吗?
我正在添加一个"animals_arriving“列,然后打开dt的其余部分
library(dplyr)
library(lubridate)
dt %>%
mutate(date_arrival = date + days(days_ahead)) %>%
group_by(date = date_arrival) %>%
summarise(animals_arriving = n()) %>%
full_join(dt,by="date")页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/56869627
复制相关文章
相似问题
腾讯云开发者
