
在更改一行值时保持sum约束行的相称性
我有一个由组合数据组成的数据集。每一列表示混合物整体中某一组分的百分比(十进制值)。每一行之和为1。
如果混合物中的某一组分发生变化,则其馀部分必须相应地改变,以满足和约束。
我正在对这些数据执行多元线性回归,它需要一些转换,以便回归系数是有意义的和可解释的。dataset包含零值,这是我试图实现的特定类型转换的一个问题。
在执行此转换之前,建议的操作是将所有零值替换为一个小数字,并调整其余组件,使sum约束仍然满足。
在下面的虚拟df中,可以看到一行中有超过1 0值的情况。
data = {'X1': [0.21, 0.08, 0.57, 0.03],
'X2': [0.27, 0.56, 0.0, 0.02],
'X3': [0.0, 0.14, 0.0, 0.45],
'X4': [0.13, 0.02, 0.26, 0.37],
'X5': [0.39, 0.2, 0.17, 0.13]}
df = pd.DataFrame(data)
print(df)让我们只考虑一行,这样做的公式如下:
将原始值设为r_i。对于组件r_i of delta_i的更改,我们得到了新的值x_i。
所以,x_i = r_i + delta_i
为了保持其余部件之间的相对比例,
将r_j设为剩余组件的原始值,
然后jth组件x_j的新值是,
x_j = r_j - ((r_j / (1 - r_i) * delta_i) and i != j
我很难为这个问题编写一个适当的循环,该循环将搜索数据集中的零值,然后向包含零值的索引和列中添加一个小数字,然后继续用我前面描述的公式调整整行。
编辑:
对不起,数学公式的表示法很差。
对于虚拟df中的第一行,公式的应用是直接的,因为该行中只有一个零:

重要的是,其余组件之间的相对比例保持不变,您可以在这里看到,当我将零值更新为一个小值时。

对于虚拟df中的第三行,事情变得更复杂了。我通过添加一个小数字来更新第一个(X2)零值。第二个(X3)零值保持为零,因为公式是乘以零并除以零。因此,我进行了第二次更新,使X2和X3现在是小的非零值,这显示在下表的第三行。

对于行上存在多个零的情况,保持剩余组件之间的相对比例也是一样的。

对于第一个问题,我想不出一个循环,更别提第二个了!另外,不要担心通过除以相对比例表中的一个小数字而产生的大数字,我稍后会讨论这个问题。
回答 2
Stack Overflow用户
发布于 2019-08-11 10:02:14
以下是编辑后的答案:
import pandas as pd
# To show 10 decimal points.
pd.options.display.float_format = '{:.10f}'.format
data = {'X1': [0.21, 0.08, 0.57, 0.03],
'X2': [0.27, 0.56, 0.0, 0.02],
'X3': [0.0, 0.14, 0.0, 0.45],
'X4': [0.13, 0.02, 0.26, 0.37],
'X5': [0.39, 0.2, 0.17, 0.13]}
df = pd.DataFrame(data)
delta_i = 0.000001
r_i = 0.0
# Provided formula.
def adjust_proportion(r_j, r_i, delta_i):
return r_j - ((r_j / (1 - r_i)) * delta_i)
# For row-wise application.
def adjust_row(row, r_i, delta_i):
# Get all zeros and their count in the row.
zero_mask = (row == 0)
zero_count = row[zero_mask].shape[0] # Get only x.
# For every zero, adjust proportions for "cells" not in mask.
for i in range(zero_count):
row[~zero_mask] = row[~zero_mask].apply(lambda x: adjust_proportion(x, r_i, delta_i))
# Increase the mask by delta_i across the board.
row[zero_mask] += delta_i
return row
# Apply ROW-WISE using axis=1.
df.apply(lambda x: adjust_row(x, r_i, delta_i), axis=1)
print(df)
# Check sums.
print(df.apply(lambda x: x.sum(), axis=1))这将产生以下结果:
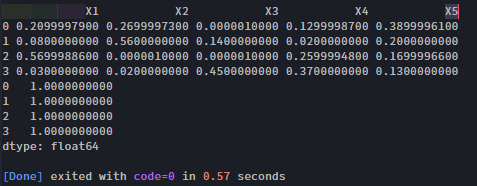
有更多的最佳方式,但这应该考虑到一般的逻辑。
Stack Overflow用户
发布于 2019-08-11 10:53:44
您可以使用:
def exclude_zero(e, delta_i):
"""Replace zeros with a delta_i value by keeping the other non zeros value in the same distribution and total sum to 1"""
zero_count = e.count(0)
extra_amount = zero_count * delta_i
for index, value in enumerate(e):
if value == 0 :
e[index] = delta_i
else:
e[index] = value * (1 - extra_amount)
return e
data = {'X1': [0.21, 0.08, 0.57, 0.03],
'X2': [0.27, 0.56, 0.0, 0.02],
'X3': [0.0, 0.14, 0.0, 0.45],
'X4': [0.13, 0.02, 0.26, 0.37],
'X5': [0.39, 0.2, 0.17, 0.13]}
df = pd.DataFrame(data)
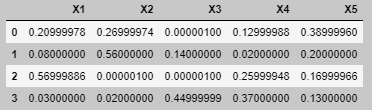
for index in range(len(df)):
df.iloc[index] = exclude_zero(df.iloc[index].values.tolist(), 0.000001)
pd.options.display.precision = 8
df
https://stackoverflow.com/questions/57448777
复制相似问题
腾讯云开发者
