
如何监测抓取蜘蛛的健康状况
我有一个Scrapy项目,分析周围的30+上市网站,我试图找到一个方法,如何维护和监测的一致性刮刀,如果任何一个网站的底层网络结构被更新。
我已经用了两种方法来尝试实现这个目标:
- 我有一套规则,如果没有几个核心字段(产品标题、价格和其他经常出现的其他字段),则使用
DropItem。这在某种程度上是有帮助的,但它假设,如果这3/4字段是正常的,那么结构的其余部分也是可以的。对于上下文,我不能使所有其他字段都是必需的,因为它们本质上是可选的(如colour、size等) - 我有一个单元,通过在一组本地保存的HTML主体上为每个蜘蛛运行刮刀来工作。这对整个代码质量都有好处,但并不能解决确定由于DOM更改而破坏蜘蛛的问题。
有几件事,我想做的路线;
- 可能计算每个爬行填充字段的平均频率。如果
size平均出现在当时的30%上,返回90%或1%的作业可能会发出警报。然而,我可以想出许多情况,要么这会触发许多假阳性,要么甚至不会触发一件事情,但仍然会被打破。 - 另一个想法是,我有一个服务,以某种方式监视HTML结构,这可以在刮擦作业之前运行,并在检测到更改时暂停。对我来说,这似乎是最有弹性的选择,但我不知道如何实现这一点。
TL;博士
如何监视HTML页面结构的更改,以避免运行导致数据损坏的Scrapy作业?
还有哪些其他选项可以检测到刮取作业是否已损坏、启发式或其他?DropItem已在任何可能的情况下使用。
回答 4
Stack Overflow用户
发布于 2019-08-12 11:08:34
检查蜘蛛侠
蜘蛛侠是刮除蜘蛛的扩展。该包为数据验证、统计监视和通知消息提供了有用的工具。这样,您可以将监视任务留给Spidermon,只需检查报告/通知。
Stack Overflow用户
发布于 2019-08-12 21:02:54
我亲自用普罗米修斯监控我的蜘蛛队。Prometheus是一种监测数字数据的解决方案,它从web服务收集度量。也就是说,您的服务必须在HTTP端点上公开度量,Prometheus将从那里收集它们。
这是不可行的,因为刮除蜘蛛会在一段时间后完成。对我来说,它起了作用,因为我为自己开发了一个调度刮擦蜘蛛的Python项目。然而,其他方法是可能的:
- 如果您的蜘蛛运行了几分钟,普罗米修斯仍然建议在一段时间后停止的过程中直接公开度量指标(并每分钟使用普罗米修斯一次)。
- 普罗米修斯也有一个所谓的推送网关。你的蜘蛛可以发送他们的指标到这个推网关和普罗米修斯将从那里收集它。注意:据我所知,推送网关上的度量永远不会过期,也就是说,您需要一些概念来检查数据的新鲜度,或者确保数据的新鲜度不重要(例如,使用不断增加的计数器,这在Prometheus用例中很常见)
在大多数情况下,我建议使用Push方法,因为它可以与标准的刮伤蜘蛛一起使用,而无需做进一步的工作。
我个人将这两项指标传递给普罗米修斯:
- 计划蜘蛛的次数
- 成功生产的项目数。
我目前无法用Prometheus监控蜘蛛内部发生的事情,因为我在进程之外运行蜘蛛,但是在现有的Python进程中运行刮取是可能的(使用Push Gateway方法,您将直接从蜘蛛进程发送数据,因此您可以从您的刮伤进程中访问所有数据)。
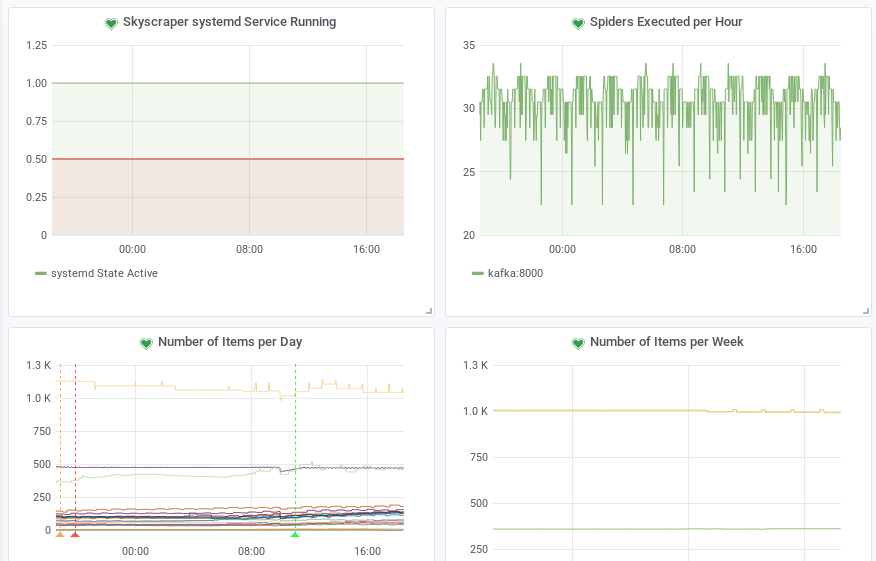
屏幕截图
这是我的活动监视器的截图。“每天的物品数量”图表中的每一行都是一个蜘蛛,而我当前的触发器是“1以下”。也就是说,如果蜘蛛完全失败了,我会收到一封电子邮件。由于有些蜘蛛可能有数天没有数据,我有另一个触发器“每周的物品数量”。
当然,如果您有更详细的数据,那么更精细的过滤器是可能的。
Stack Overflow用户
发布于 2019-08-13 10:50:20
我编写了一个测试框架,用于测试爬虫和实时缓存的数据,称为scrapy-test。该框架的重点是测试、解析和爬行覆盖率。
您可以为字段定义测试:
from scrapytest.tests import Match, Equal, Type, MoreThan, Map, Len, Required
from myspider.items import PostItem
class TestPost(ItemSpec):
# defining item that is being covered
item_cls = PostItem
# defining field tests
title_test = Match('.{5,}')
points_test = Type(int), MoreThan(0)
author_test = Type(str), Match('.{3}')
# every item should have title - 100%
title_cov = 100以及统计数据:
class TestStats(StatsSpec):
# stat pattern: test functions
validate = {
'log_count/ERROR$': LessThan(1),
'item_scraped_count': MoreThan(1),
'finish_reason': Match('finished'),
}因此,使用scrapy-test的一般工作流程是每天/半小时运行测试,以确保蜘蛛的健康。
https://stackoverflow.com/questions/57459905
复制相似问题
腾讯云开发者
