
断裂棒模型的发展趋势
断裂棒模型的发展趋势
提问于 2019-08-20 18:19:17
我正在拟合断棒模型,并希望使用emtrends()来提取断点前后的斜率值。这里的代码是一个简化的玩具版本的数据和分析。我不太清楚如何得到斜率-似乎得到了断点前后的相同值。我做错了什么?
library(ggplot2)
library(emmeans)
## toy data
df <- structure(list(Year = c(11, 11, 13, 13, 15, 15, 16, 16, 17,
17, 18, 18, 14, 14), YearFac = structure(c(1L, 1L, 2L, 2L,
4L, 4L, 5L, 5L, 6L, 6L, 7L, 7L, 3L, 3L), .Label = c("11",
"13", "14", "15", "16", "17", "18"), class = "factor"), Class = c("A", "B", "A",
"B", "A", "B", "A", "B", "A", "B", "A", "B", "A", "B"), Mean = c(3.5, 3.7, 3.7, 4.2, 3.7,
4.5, 3.3, 4.9, 3.2, 5.8, 3.2, 6.3, NA, NA), YearPostTest = c(0, 0, 0,
0, 1, 1, 2, 2, 3, 3, 4, 4, 0, 0)), row.names = c(3L, 4L, 5L, 7L, 8L,
10L, 11L, 13L, 14L, 16L, 17L, 19L, 20L, 21L), class = "data.frame")
# breakpoint model
mod <- lm(Mean ~ Year + YearPostTest + Year:Class +
YearPostTest:Class, data = df)
df$Pred <- predict(mod, newdata = df)
# plot data and predictions
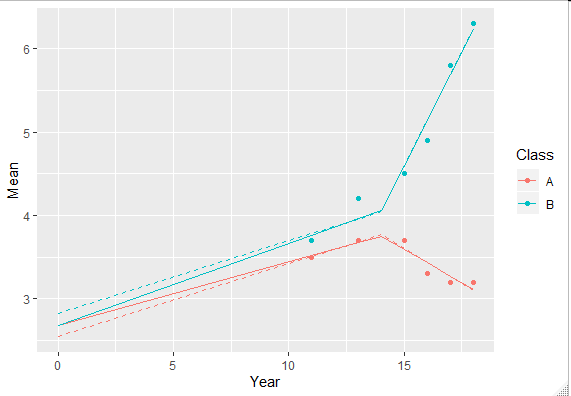
ggplot(df) +
geom_point(aes(x = Year, y = Mean, colour = Class)) +
geom_line(aes(x = Year, y = Pred, colour = Class))
# make a new dataset with a few values - specifically, want to see slopes for A and for B
# classes before and after breakpoint
new <- data.frame(YearPostTest = c(0, 1, 0, 1),
Year = c(13, 18, 13, 18), Class = c("A", "A", "B", "B"))
emtrends(mod, ~Class|YearPostTest, var = "Year", data = new,
covnest = TRUE, cov.reduce = FALSE)回答 1
Stack Overflow用户
回答已采纳
发布于 2019-08-21 02:35:14
您的方法不起作用,因为斜率依赖于Year和YearPostTest,而后者在计算差值商时保持不变。
最简单的方法是编写一个创建折线的函数:
> brok.line = function(x, knot)
+ cbind(x, (x > knot) * (x - knot))
> modmod = lm(Mean ~ brok.line(Year, 14) * Class, data = df)
> emtrends(modmod, ~ Class | Year, var = "Year", data = new, cov.reduce = FALSE)
Year = 13:
Class Year.trend SE df lower.CL upper.CL
A 0.0875 0.0893 6 -0.131 0.30593
B 0.0875 0.0893 6 -0.131 0.30593
Year = 18:
Class Year.trend SE df lower.CL upper.CL
A -0.1663 0.0662 6 -0.328 -0.00426
B 0.5487 0.0662 6 0.387 0.71074
Confidence level used: 0.95附录
另一件需要知道的是,指定data并不能替代at规范。我们可以得到与上面相同的结果
> emtrends(modmod, ~ Class | Year, var = "Year",
+ at = list(Year = c(13, 18)))它在您的示例中工作的唯一原因是因为cov.reduce = FALSE产生了相同的协变量值集。但是,请注意,对于原始模型mod
> summary(ref_grid(mod, data = new, cov.reduce = FALSE, nesting = NULL))
Year YearPostTest Class prediction SE df
13 0 A 3.68 0.1073 7
18 0 A 4.06 0.3458 7
13 1 A 3.44 0.0916 7
18 1 A 3.82 0.2512 7
13 0 B 3.96 0.1073 7
18 0 B 4.45 0.3458 7
13 1 B 4.41 0.0916 7
18 1 B 4.90 0.2512 7new数据集生成了8种情况,尽管new只有4行。这是因为参考网格包含所有可能的预测器级别组合--而不仅仅是出现在data中的那些级别。
还有一件事
我注意到mod和modmod并不完全相同,因为mod排除了Class的主要影响。在这个特定的例子中,这种效果非常小;但是通常,您应该在模型中包括Class,否则假设两个类具有相同的截获:
> year0 = data.frame(Year = c(0,0), YearPostTest = c(0,0), Class = c("A","B"))
> predict(mod, newdata = year0)
1 2
2.68125 2.68125
> predict(modmod, newdata = year0)
1 2
2.54375 2.81875
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/57579479
复制相关文章
相似问题
腾讯云开发者
