
为什么在运行时添加两个值会有如此高的可变性?
我编写了一个计时函数,它记录一个函数的运行时间,并计算多次运行的平均偏差和标准差。我惊讶地发现非常高的标准差,甚至对于看似简单的任务,比如增加两个双倍。我分析了python中的数据(见图)。使用以下方法编译时,c++输出为19.6171 ns +/- 21.9653ns (82799807 runs):
gcc version 8.3.0 (Debian 8.3.0-19)
/usr/bin/c++ -O3 -DNDEBUG -std=gnu++17整个测试是在我的个人计算机上完成的,它不是空闲的,而是运行DE、浏览器、IDE和其他进程的。不过,在测试期间有可用的空闲RAM。我使用HT的双核CPU空转率低于10%。
在这种情况下,从20 ns的平均值到50 ns的峰值是预期的吗?
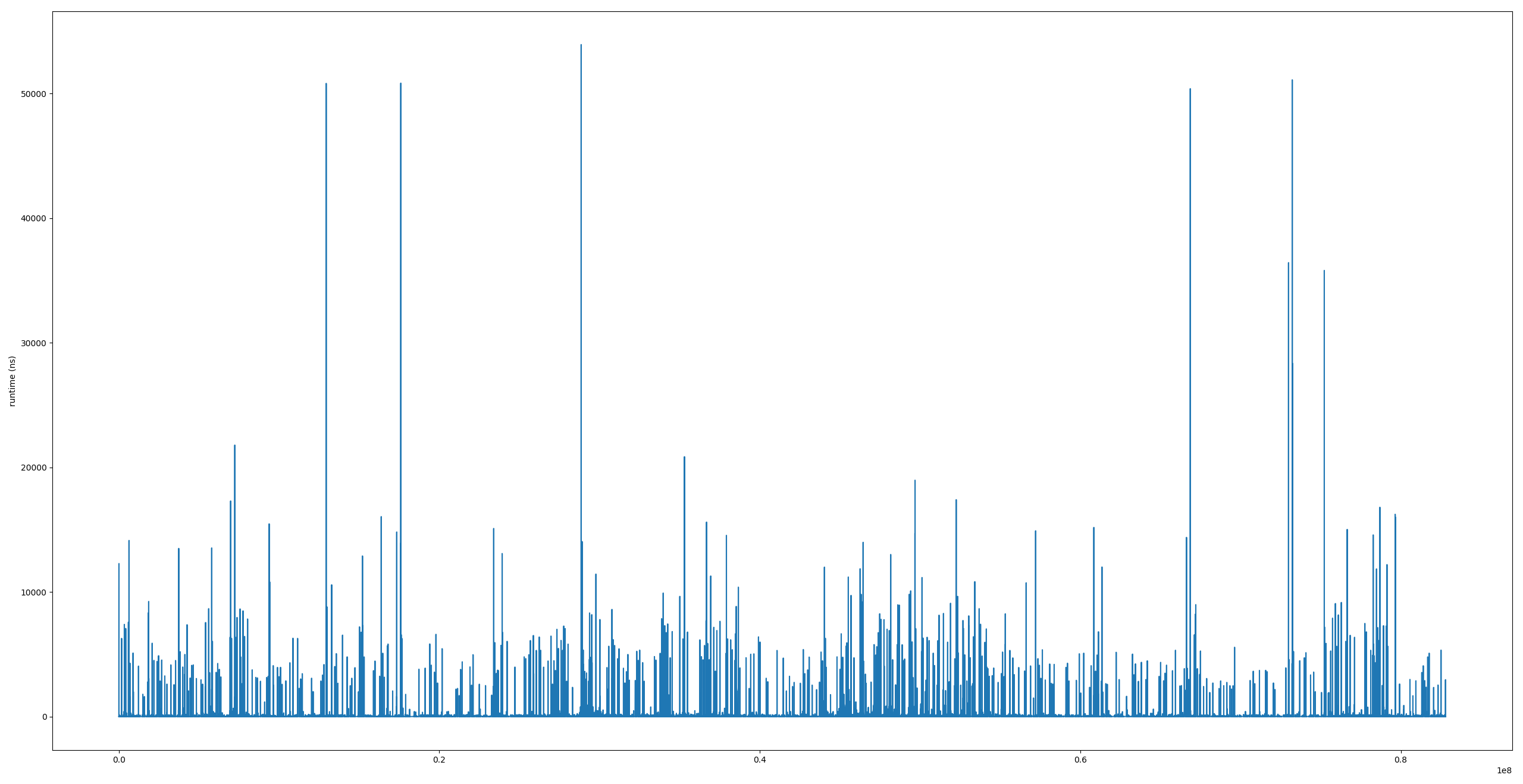
运行时的图
这是std::vector<double> run_times的内容。我看不出有什么模式。
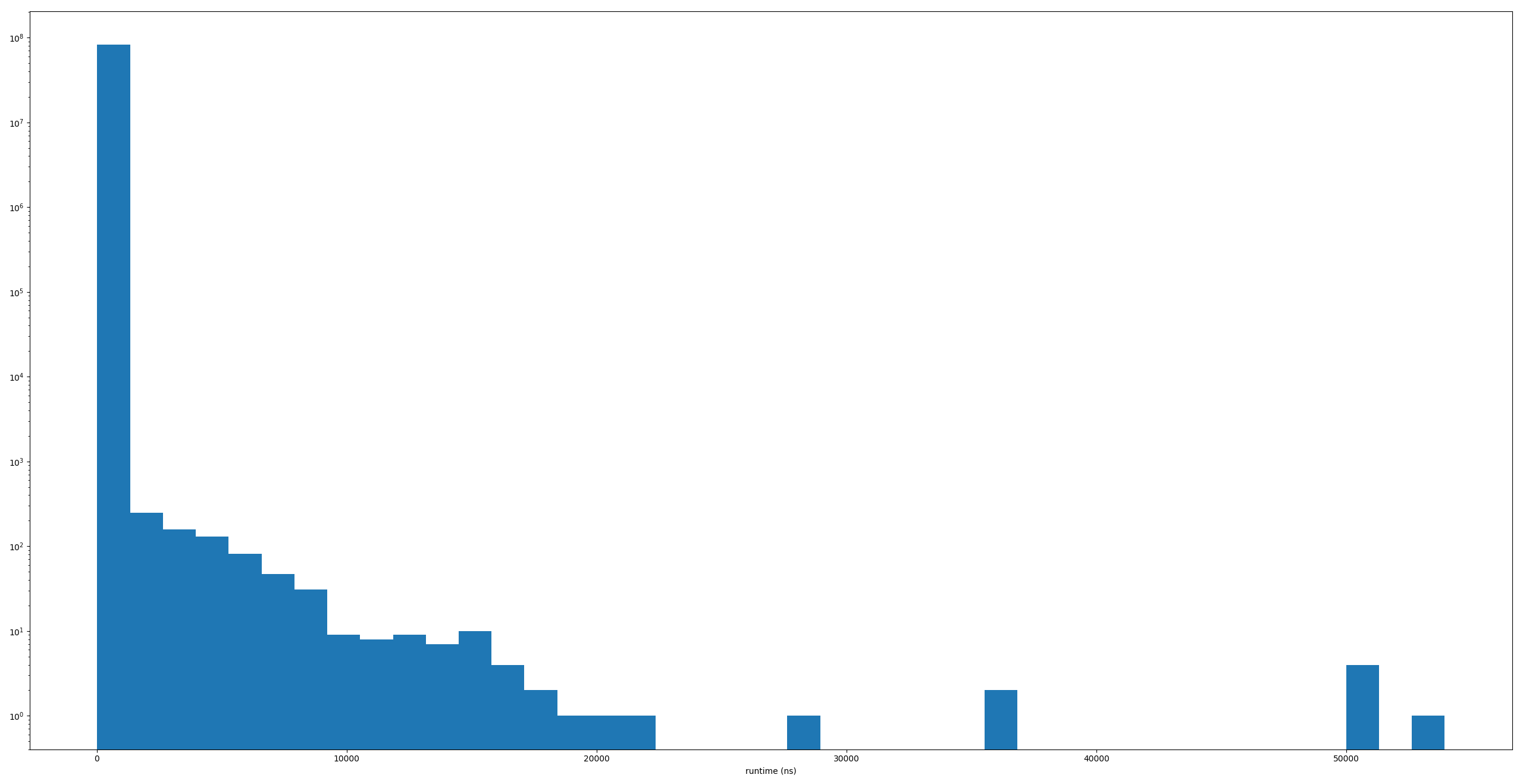
运行时间直方图
注意日志y轴(这个垃圾箱中的样本数)。
timing.h
#include <cstdint>
#include <ostream>
#include <cmath>
#include <algorithm>
#include <vector>
#include <chrono>
#include <numeric>
#include <fstream>
struct TimingResults{
// all time results are in nanoseconds
double mean;
double standard_deviation;
uint64_t number_of_runs;
};
std::ostream& operator<<(std::ostream& os, const TimingResults& results);
template <typename InputIterator>
std::pair<typename InputIterator::value_type, typename InputIterator::value_type>
calculate_mean_and_standard_deviation(InputIterator first, InputIterator last){
double mean = std::accumulate(first, last, 0.) / std::distance(first, last);
double sum = 0;
std::for_each(first, last, [&](double x){sum += (x - mean) * (x - mean);});
return {mean, std::sqrt(sum / (std::distance(first, last) - 1))};
}
template<uint64_t RunTimeMilliSeconds = 4000, typename F, typename... Args>
TimingResults measure_runtime(F func, Args&&... args){
std::vector<double> runtimes;
std::chrono::system_clock::time_point b;
auto start_time = std::chrono::high_resolution_clock::now();
do {
auto a = std::chrono::high_resolution_clock::now();
func(std::forward<Args>(args)...);
b = std::chrono::high_resolution_clock::now();
runtimes.push_back(std::chrono::duration_cast<std::chrono::nanoseconds>(b - a).count());
} while (std::chrono::duration_cast<std::chrono::milliseconds>(b-start_time).count() <= RunTimeMilliSeconds);
auto [mean, std_deviation] = calculate_mean_and_standard_deviation(runtimes.begin(), runtimes.end());
return {mean, std_deviation, runtimes.size()};
}timing.cpp
#include <iostream>
#include "timing.h"
std::ostream& operator<<(std::ostream& os, const TimingResults& results){
return os << results.mean << " ns" << " +/- " << results.standard_deviation << "ns ("
<< results.number_of_runs << " runs)";
}main.cpp
#include "src/timing/timing.h"
#include <iostream>
int main(){
auto res = measure_runtime([](double x, double y){return x * y;}, 6.9, 9.6);
std::cout << res;
}回答 2
Stack Overflow用户
发布于 2019-08-28 12:14:13
现代CPU容易执行数个10^9次失败的顺序,即一次操作的预期时间小于1ns。然而,这指的是峰值性能。对于大多数真实世界的工作负载,由于内存和缓存的影响,性能将大大降低。
基准测试的问题是,--您正在对单个操作进行计时,。获取时间点的开销( a和b )很可能只是超过了实际要测量的时间。此外,即使是std::chrono::high_resolution_clock也不会给您提供微微秒的精度(尽管这是原则上的实现和硬件的依赖)。最明显的解决方法是执行N次数的操作,然后再将总时间除以N。在某种程度上,您将看到您的结果变得一致。(可以随意发布结果。)
医生:你在用怀表计时闪电。
Stack Overflow用户
发布于 2019-08-28 12:51:03
TL:您的整个方法过于简单,无法告诉您任何有用的东西。即使你的乘法没有被优化掉,计时开销也会占主导地位。
即使在手工编写的asm中,微基准测试也是不平凡的。如果您不了解您的C++如何为您的目标平台编译C++,对于像x * y这样简单/廉价的操作,在C++中是不可能的。
您没有使用结果,所以您可能试图测量吞吐量(而不是延迟)。但是,在时间间隔内只有一个乘法,就不可能发生超标量/流水线执行。
更根本的是,您没有使用结果,所以编译器根本不需要计算它。即使这样,在从C++头插入后,操作数是编译时常量,所以编译器将在编译时执行一次,而不是在运行时使用mulsd指令。即使您使main中的arg来自于atof(argv[1])或其他什么东西,编译器也可以将计算从循环中提升出来。
这3个微基准测试缺陷中的任何一个都将导致计时一个空的间隔,除了将第一个now()结果保存到不同的寄存器之外,这两个函数之间没有工作。你有三个问题。
您实际上是在计时一个空的间隔,但是由于偶尔的中断,以及封装在clock_gettime周围的库函数的相对较高的开销(最终运行rdtsc指令并使用内核导出的值对其进行缩放),仍然会产生如此大的抖动。幸运的是,它可以在用户空间中这样做,而无需实际使用syscall指令进入内核。( Linux内核在VDSO页面中导出代码+数据。)
在紧循环中直接使用rdtsc确实提供了相当可重复的时间,但相对于mulsd,仍然有相当高的开销。(64 from C++?)。
在这个细节层次上,你的执行成本的心理模型可能是错误的。你不能只对单个业务进行计时,然后再把它们的成本相加。超标量流水线无序执行意味着您必须考虑吞吐量与延迟,以及依赖链的长度。(以及前端瓶颈与任何一种指令或执行端口的吞吐量相比)。
- Modern x86 cost model
- How many CPU cycles are needed for each assembly instruction?
- What considerations go into predicting latency for operations on modern superscalar processors and how can I calculate them by hand?
和no,禁用优化是没用的,会通过嵌套C++函数将其转化为调用/ret的微基准,可能还会存储转发延迟。
禁用优化的基准测试是无用的。通常,您需要使用内联asm来强制编译器在循环中反复在寄存器中物化一个值,并且/或忘记它对变量值的了解,从而使它重做计算而不是吊起它。例如,请参见"Escape" and "Clobber" equivalent in MSVC (不是MSVC部分,只是问题中显示有用的GNU内联asm的部分)。
https://stackoverflow.com/questions/57691672
复制相似问题
腾讯云开发者
