
如何优化多连接作业
如何优化多连接作业
提问于 2019-09-05 23:12:12
如何加速对CSV文件的连接?
我有一个连接8个文件的查询:
//please note this is the simplified query
DECLARE ... //summarizing here
FROM ...
USING Extractors.Text(delimiter : '|');
//8 more statements like the above ommitted
SELECT one.an_episode_id,
one.id2_enc_kgb_id,
one.suffix,
two.suffixa,
three.suffixThree,
four.suffixFour,
five.suffixFive,
six.suffixSix,
seven.suffixSeven,
eight.suffixEight,
nine.suffixNine,
ten.suffixTen
FROM @one_files AS one
JOIN @two_files AS two
ON one.id3_enc_kgb_id == two.id3_enc_kgb_id
JOIN @three_files AS three
ON three.id3_enc_kgb_id == one.id3_enc_kgb_id
JOIN @four_files AS four
ON four.id3_enc_kgb_id == one.id3_enc_kgb_id
JOIN @five_files AS five
ON five.id3_enc_kgb_id == one.id3_enc_kgb_id
JOIN @six_files AS six
ON six.id2_enc_kgb_id == one.id2_enc_kgb_id
JOIN @seven_files AS seven
ON seven.id2_enc_kgb_id == one.id2_enc_kgb_id
JOIN @eight_files AS eight
ON eight.id2_enc_kgb_id == one.id2_enc_kgb_id
JOIN @nine_files AS nine
ON nine.id2_enc_kgb_id == one.id2_enc_kgb_id
JOIN @ten_files AS ten
ON ten.id2_enc_kgb_id == one.id2_enc_kgb_id;我向Azure提交了这份工作,在花费了80美元和几个小时后不得不取消了它!
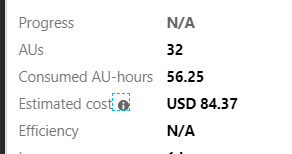
这是我的理解,数据湖正是为了这种类型的工作?!我总共有100个文件,总共可能有2000万个数据。
我怎样才能加速我的加入?
回答 1
Stack Overflow用户
回答已采纳
发布于 2019-09-10 07:46:42
您需要注意的是,在每个场景中,小文件都是次优。米哈尔·里斯建议的较小文件的解决方案是考虑将它们连接到大文件中的替代方案:
- 离线在Azure外面
- 事件中心捕获
- 流分析
- 或ADLA快速文件集来压缩最近的三角洲。
注意:fast file set允许您在一个EXTRACT中大量使用成千上万个这样的文件。
我将使用INNER JOIN而不是JOIN来确保您知道真正使用的是哪个连接。
了解如何从CSV文件中获得EXTRACTed信息非常重要。JOINed结果应该是OUTPUTed到tsv (制表符分隔值 -注意:TVF is 表值函数 for u-sql代码重用)文件。
TSV结构:
- TSV =Tab分离值
- 它没有标题行。
- 每一行都有相同的列数。
这种格式对于myself来说应该是非常有效的(我自己还没有度量它)。
要获得完整的信息,您可以有三种不同的内置输出类型.Text()、.Csv()、Tsv()。
您的示例缺少变量,所以我将尝试猜测它们。
USE DATABASE <your_database>;
USE SCHEMA <your_schema>;
DECLARE @FirstCsvFile string = "/<path>/first.csv";
@firstFile = EXTRACT an_episode_id string, id2_enc_kgb_id string, suffix string
FROM @FirstCsvFile USING Extractors.Text(delimiter : '|');
// probably 8 more statements which where omitted in the OP
@encode = SELECT one.an_episode_id,
one.id2_enc_kgb_id,
one.suffix,
two.suffixa,
three.suffixThree,
four.suffixFour,
five.suffixFive,
six.suffixSix,
seven.suffixSeven,
eight.suffixEight,
nine.suffixNine,
ten.suffixTen
FROM @firstFile AS one
INNER JOIN @two_files AS two
ON one.id3_enc_kgb_id == two.id3_enc_kgb_id
INNER JOIN @three_files AS three
ON three.id3_enc_kgb_id == one.id3_enc_kgb_id
INNER JOIN @four_files AS four
ON four.id3_enc_kgb_id == one.id3_enc_kgb_id
INNER JOIN @five_files AS five
ON five.id3_enc_kgb_id == one.id3_enc_kgb_id
INNER JOIN @six_files AS six
ON six.id2_enc_kgb_id == one.id2_enc_kgb_id
INNER JOIN @seven_files AS seven
ON seven.id2_enc_kgb_id == one.id2_enc_kgb_id
INNER JOIN @eight_files AS eight
ON eight.id2_enc_kgb_id == one.id2_enc_kgb_id
INNER JOIN @nine_files AS nine
ON nine.id2_enc_kgb_id == one.id2_enc_kgb_id
INNER JOIN @ten_files AS ten
ON ten.id2_enc_kgb_id == one.id2_enc_kgb_id;
OUTPUT @encode TO "/outputs/encode_joins.tsv" USING Outputters.Tsv();页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/57813955
复制相关文章
相似问题
腾讯云开发者
