
弹性 MapReduce
弹性 MapReduce的主要功能有哪些?
弹性伸缩
- 分钟级集群创建 :通过控制台数分钟就可创建一个安全、稳定的云端托管 Hadoop 集群。
- 分钟级集群扩缩容 :仅需数分钟即可对现有弹性 MapReduce集群进行平滑扩缩容,以适应互联网业务需求的快速变化。
- API 支持 :支持通过 API 方式便捷的在程序中创建、扩/缩容、销毁弹性 MapReduce集群。
存储计算分离
- 集群内存储计算分离 :集群内支持按照存储节点、计算节点的模式来规划云端 Hadoop 集群,以支持客户对计算节点的随意伸缩来降低硬件成本。
- 基于 COS 的存储计算分离:支持把待分析海量数据存放于 COS,在通过 COS 规模化效应降低存储成本的同时,您还可以创建不同弹性 MapReduce 版本分析同一份数据,这将为您带来极度的架构灵活性。
运维支撑
- 监控与多渠道告警 :提供完善的监控运维体系,对包含 Spark、Hive、Presto 等在内的组件异常和任务异常的秒级感知,以保障大数据集群的稳健运行。
- 技术服务支持:在提供完善技术文档之外,还支持包含邮件、QQ、微信等渠道在内的技术服务体系,为客户提供完备的技术支持。
安全
弹性 MapReduce创建的 CVM 子机同时会创建安全组来限制外网访问。各组件 Web UI 均通过其中一台有外网 IP 的子机进行访问,并且通过用户名和密码进行验证,有外网 IP 的子机安全组只开放 SSH 端口和代理访问端口。
与自建 Hadoop 集群相比,弹性 MapReduce有什么优势?
灵活
- 只需几分钟即可获得一个安全可靠的 Hadoop 集群,以运行 Hive、Spark、Presto 、Impala、ClickHouse、Druid、Flink 等主流开源大数据计算框架,覆盖用户交互式 BI、数仓场景、实时计算等场景的需求。
- 提供对现有弹性 MapReduce 集群进行快速弹性伸缩的能力,实时调配云端计算资源以应对业务数据的快速波动,节省高昂的预留 IT 硬件成本。
可靠
- Master 节点容灾设计,备节点秒级拉起,保障大数据服务可用性。
- 完善的监控体系建设,您可以通过短信渠道秒级感知集群组件及任务的运行异常状况。
- 支持将 Hive 元数据存放于 MetaDB,元数据可靠性达99.9996%。
- 支持分析存放于 COS 的高存储耐久性的 PB 级数据。
- 集群默认开启回收站功能,提供误删除设备的找回机制。
安全
- 可通过便捷的 VPC 网络安全隔离手段规划托管 Hadoop 集群网络策略,支持网络 ACL 和安全组,可从子网和节点维度筛选流量,全方位满足网络安全需求。
- 腾讯云品质的安全加固服务为 EMR 集群提供一体化的安全服务,涵盖网络防护、入侵检测、漏洞防护等。
- 提供集群级别的 Kerberos 认证,保障集群访问安全。
易用
- 可以响应业务需求创建不同版本的集群分析 COS 上的同一份数据。
- 可以借助开箱即用的 Hue、Oozie 等社区组件随心分析位于数据节点或 COS 上的 PB 级数据,无需担心产生任何知识迁移成本。
- 近千项集群级、组件级监控指标,搭配监控概览页面,提供丰富且清晰易用的监控系统。
- 灵活支撑云端多机型集群,实现对异构配置集群在扩容、配置下发等场景下的轻松应对,以更优硬件配置应对业务分析挑战。
节约成本
- 通过弹性 MapReduce服务,可以按业务曲线随心伸缩托管 Hadoop 集群,缩减高昂的硬件成本。
- 丰富的运维工具支持,大幅提升运维工作效率,让工程师更专注于业务本身的商业价值,摆脱重复搭建监控、安全、运维工具等基础设施。
- 支持温冷数据的对象存储 COS/CHDFS 存储,成本有效降低28% - 50%。
- 结合统一 Hive 元数据库以及统一对象存储,实现跨集群的同数据集分析架构,集群按需创建或销毁,节省集群柔性成本。
弹性 MapReduce有什么应用场景?
离线数据分析
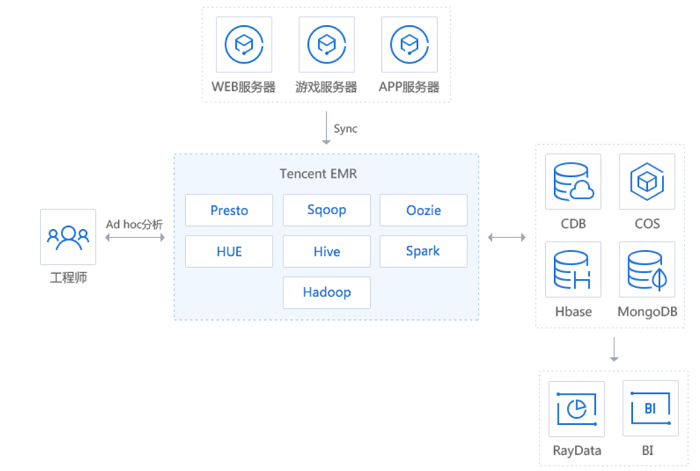
把游戏、Web 应用、手机 App 等业务服务器上的海量日志同步到弹性 MapReduce的数据节点或 COS 后,可借助于 Hue 等工具,使用 Hive、Spark、Presto 等主流计算框架快速获取数据洞察力。可使用 Sqoop 等工具加载分散于各 TencentDB 或其他存储引擎的数据,并把分析后的数据同步到 TencentDB,为 RayData 这样的数据可视化产品提供数据支撑。
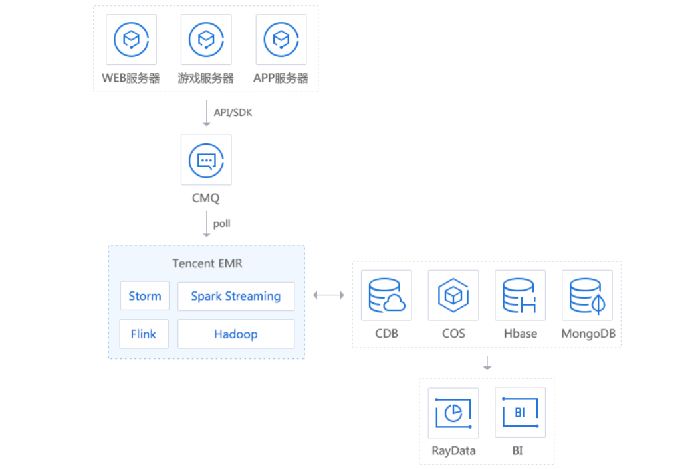
流式数据处理
在程序/工具中通过 API、SDK 把位于业务服务器上实时产生的数据 Push 到 CMQ 消息中间件之后,可在 EMR 产品中选择合适的流式数据处理引擎来分析数据,以实现对业务变动的实时告警;还可以把分析结果实时同步到 TencentDB 等存储引擎,以便于通过 RayData 等数据可视化产品对业务状态进行实时可视化检测。
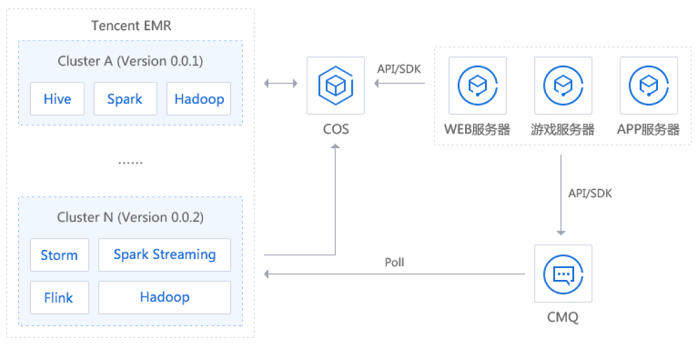
分析 COS 数据
可通过弹性 MapReduce产品快速分析存储于 COS 上的海量数据,以实现彻底的存储计算分离。通过这样的设计,可充分利用 COS 提供的丰富数据同步工具,同时还可以让多个不同版本 Hadoop 集群分析同一份数据,以满足数据一致性及历史原因导致的多版本 Hadoop 集群共存的问题。
- EMR(弹性MapReduce)入门之计算引擎Spark、Tez、MapReduce区别(八)
- EMR(弹性MapReduce)入门之组件Hue(十三)
- EMR(弹性MapReduce)入门之初识EMR(一)
- EMR(弹性MapReduce)入门之kafka实战(十五)
- 如何为Hadoop选择最佳弹性MapReduce框架
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号