
云数据仓库 for Apache Doris
云数据仓库 for Apache Doris的产品功能有哪些?
MySQL 协议兼容
Doris 提供兼容 MySQL 协议的连接接口,用户不必再单独部署新的客户端库或者工具,可以直接使用 MySQL 的相关库或者工具。
大查询高吞吐
利用 MPP 架构的优势,使得查询能够分布式的在多个节点并行执行,充分利用集群整体计算资源,提高大查询的吞吐能力。
高并发小查询
通过使用分区裁剪,预聚合,谓词下推,向量化执行,异步 RPC 等技术,Doris 可以支持高并发点查询场景。100台集群可达10w QPS。
支持数据更新和删除
Doris 支持按主键删除和更新数据。能够方便的从 MySQL 等事务数据库中同步实时更新的数据。
高可用和高可靠
Doris 中的数据和元数据都默认使用3副本存储。在少数节点宕机的情况下,依然可以保证数据的可靠性。Doris 会自动检查和修复损坏的数据,并将请求自动路由到健康的节点,7*24 小时保证数据的可用性。
水平扩展和数据均衡
FE 节点和 BE 节点都可以进行横向扩展。用户可以根据计算和存储需要,灵活的对节点进行扩展。其中 BE 节点在扩展后,Doris 会自动根据节点间的负载情况,进行数据分片的自动均衡,无需人工干预。
物化视图和预聚合引擎
Doris 支持通过物化视图或上卷表的形式对数据预聚合计算后的结果进行存储,从而加速部分聚合类场景的查询效率。同时,Doris 能够保证物化视图和基础表之间的数据一致性,从而使得物化视图会查询和导入完全透明。Doris 内部会自动根据用户的查询语句,选择合适的物化视图进行数据摄取。
丰富的数据导入功能和导入事务保证
Doris 支持多种导入方式。不仅支持近实时的流式导入,也支持大批量的数据导入。同时还可以直接订阅和消费 kafka 中的数据。Doris 自身提供导入事务支持,配合导入 Label 机制,可以保证导入数据的不重不丢和原子一致性。
高效的列式存储引擎和一级二级索引
Doris 采用自研的列式存储格式。存储采用字典、RLE 等多种编码方式,配合列式存储的特点,提供了非常高的数据压缩比,帮助用户节省存储空间。同时,存储格式上提供包括 Min/Max 智能索引、稀疏索引、布隆过滤器、bitmap 倒排索引等多种查询加速技术,进一步提升了查询效率。
在线表结构修改能力
支持在已导入数据的情况下修改表结构,包括增加列、删除列、修改列类型和改变列顺序等操作。变更操作不会影响当前数据 库的查询和写入操作。
生态支持和周边组件的兼容能力
Doris 可以方便的导入存储在对象存储、HDFS 或 Kafka 中的数据,也可以通过 Flink,Spark 直接将 ETL 后的数据写入 Doris 中。用户也可以通过 Spark 来直接查询 Doris 中存储的数据。而 Doris 也可以通过 ODBC 读取包括 MySQL、PostgreSQL、SQLServer、Oracle 等外部数据源的数据。同时,Doris 也可以读取 Elasticsearch 中存储的数据,为 Elasticsearch 提供强大的分布式 SQL 查询层。
云数据仓库 for Apache Doris有什么产品优势?
云上托管
云数据仓库 for Apache Doris 有通过与云上虚拟主机、云盘、对象存储、云上 MySQL 实例等无缝集成,实现了云原生数仓具有的弹性、扩展性和安全、高可用、高可靠保障。例如,可以将数据存储在云盘和对象存储系统,可以将元数据存储在云上 MySQL 实例。
运维监控
云数据仓库 for Apache Doris 有完善的集群管理功能,可以省去繁重的人工运维工作,通过在控制台的操作,即可实现几乎所有的运维操作,包括集群扩缩容、升降变配、参数配置等。另外云数据仓库 for Apache Doris 提供可视化监控功能,可以查看集群运行情况,帮助业务及时感知集群运行状态。
安全可靠
用户可对云数据仓库 Doris 集群进行独立部署,支持 VPC 私有网络隔离,提升数据访问信息安全能力。支持数据副本机制,实现用户无感的服务容灾转移和故障恢复。
MySQL 协议兼容
Doris 提供兼容 MySQL 协议的连接接口,用户无需单独部署新的客户端库或者工具,可直接使用 MySQL 的相关库或者工具。提供了 MySQL 接口,可便捷的与上层应用兼容。用户学习曲线降低,方便用户上手使用。
大查询高吞吐
利用 MPP 架构的优势,使得查询能够分布式的在多个节点并行执行,充分利用集群整体计算资源,提高大查询的吞吐能力。
高并发小查询
通过使用分区裁剪、预聚合、谓词下推、向量化执行、异步 RPC 等技术,Doris 可以支持高并发点查询场景。
数据更新
Doris 支持按主键删除和更新数据。能够方便的从 MySQL 等事务数据库中同步实时更新的数据。
高可用和高可靠
Doris 中的数据和元数据都默认使用3副本存储(BE 节点需大于等于3)。在少数节点宕机的情况下,依然可以保证数据的可靠性。Doris 会自动检查和修复损坏的数据,并将查询请求自动路由到健康的节点,7×24小时保证数据的可用性。
水平扩展和数据均衡
FE 节点和 BE 节点都可以进行横向扩展。用户可以根据计算和存储需要,灵活的对节点进行扩展。其中 BE 节点在扩展后,Doris 会自动根据节点间的负载情况,进行数据分片的自动均衡,无需人工干预。
物化视图和预聚合引擎
Doris 支持通过物化视图或上卷表的形式对数据预聚合计算后的结果进行存储,从而加速部分聚合类场景的查询效率。同时,Doris 能够保证物化视图和基础表之间的数据一致性,从而使得物化视图会查询和导入完全透明。Doris 内部会自动根据用户的查询语句,选择合适的物化视图进行数据摄取。
高效的列式存储引擎
Doris 采用自研的列式存储格式来提升 OLAP 领域的查询效率。存储采用字典编码、RLE 等多种编码方式,配合列式存储的特点,提供了非常高的数据压缩比,帮助用户节省存储空间。同时,存储格式上提供包括 Min/Max 智能索引、稀疏索引、布隆过滤器、bitmap 倒排索引等多种查询加速技术,进一步提升了查询效率。
在线表结构修改
支持在已导入数据的情况下修改表结构,包括增加列、删除列、修改列类型和改变列顺序等操作。变更操作不会影响当前数据库的查询和写入操作。
云数据仓库 for Apache Doris用什么应用场景?
OLAP 多维分析和报表——高维表上的高速随意探查能力
在关系数据库中,多维分析定义的对数据立方体(CUBE)上进行的钻取、上卷、切片、切块、旋转等操作是通过维度建模实现的。 维度建模最常见的模型是星型模型和雪花模型。 维度建模中,一个表中的列可以分为维度列和指标列,Doris 支持在建表的时候定义出维度列和指标列,如下图所示。

指标列上可以定义函数,Doris 可以做到在数据导入的时候,数据按照维度列进行分类,再按照指标列指定的函数进行聚合。这种预聚合能力大大减少了查询所扫描的数据量,从而加速了聚合查询的速度。 另外,Doris 还实现了物化视图、Rollup 索引和 CUBE 的语法,其中的 Rollup 对应上卷操作、通过 Grouping Set 语法可以建出 CUBE 立方体来。
实时数仓和数据分析——PB 级数据量上的实时增、删、改、查能力
下图展示的是一个 Doris 的建表语句,从这个语句中可以看出,数据可以分区(Partition),也可以分桶 (DISTRIBUTED BY),通过分区和分桶,Doris 可以将一个表 (Table) 的数据拆分成多个 Tablet。
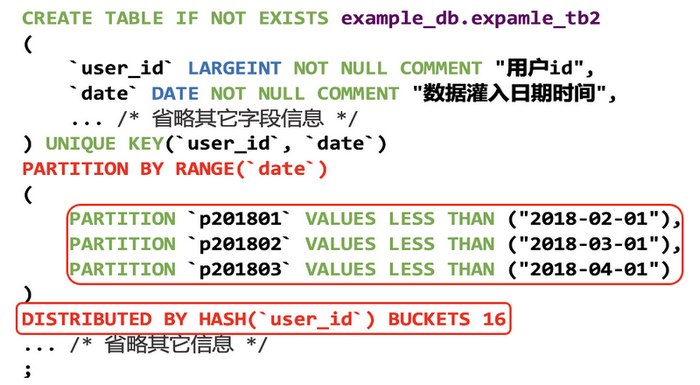
Doris 中每个 Tablet 可以设置多个副本,这些 Tablet 及其副本可以存储在不同的 BE 中,从而保证数据的高可用和高可靠。
物理上,Tablet 会按照一定大小(256M)拆分为多个 Segment 文件,Segment 是列存的 LSM-Tree 全称是Log Structured Merge Tree,是一种分层,有序,面向磁盘的数据结构。这种结构的理论基础是磁盘批量的顺序写要远比随机写性能高。
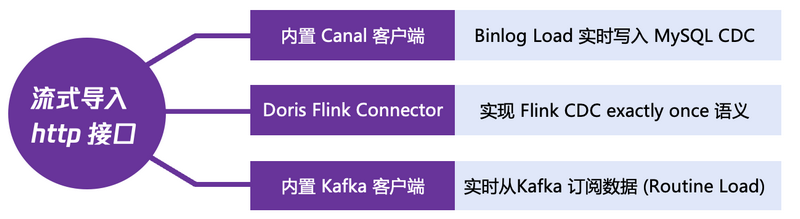
作为对实时数仓和数据分析的支持,数据的实时写入是非常关键的一个环节,为了实现数据的实时写入,Doris 开发了 Stream Load 实现了数据的实时写入能力。
在此基础上,又提供了三种常用的实时导入功能:也即通过内置的 Canal 客户端实时获取 MySQL 的 binlog;通过 Doris Flink Connector 对接 Flink 的 CDC 能力实现数据的精确导入; 通过内置的 Kafka 客户端订阅 Kafka 的 Topic, 从而实现数据的实时更新。
高并发场景——高并发下低延迟查询能力
Doris 拥有一个现代的MPP查询引擎,这个引擎完整实现了 Exchange 节点。有了 Exchange 节点,查询就能被分解到各个节点进行并行数据处理。 同时 Doris 由于FE和BE能很容易横向扩展,理论上就能应对并发增加的情况,从而满足高并发场景。
Doris 提供了丰富的索引结构来帮助加速数据的读取和过滤。索引的类型大体可以分为智能索引和二级索引两种。
其中智能索引是在 Doris 数据写入时自动生成的,无需用户干预。而二级索引是用户可以选择性的在某些列上添加的辅助索引。
智能索引包括前缀稀疏索引和MinMax索引两种。 前缀稀疏索引是建立在排序结构上的一种索引。Doris 存储在文件中的数据,是按照排序列有序存储的,Doris 会在排序数据上,每 1024 行创建一个稀疏索引项。
索引的 Key 即当前这1024行中,第一行的前缀排序列的值。当用户的查询条件包含这些排序列时,我们可以通过前缀稀疏索引快速的定位到起始行。 另外,Doris 也实现了动态分区裁剪和谓词下推技术,这些技术都能有效的降低最终从磁盘 scan 的数据量,从而加快查询的执行。
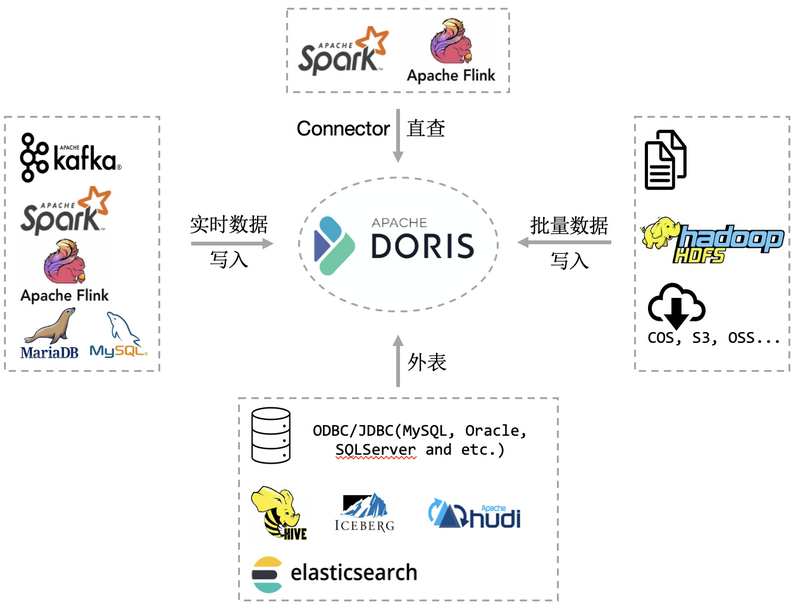
大数据和数据库统一分析——Hadoop 生态兼容和外表高性能查询能力
Doris 不依赖 Hadoop 组件,但是 Doris 本身对 Hadoop 生态进行了全面的支持。除了可以通过 Flink, Spark 写入 Doris ,我们还可以导入 HDFS 的数据,也可以通过建立 Hive 外表,直接查询 Hive 数据。 下图是 Doris 对 Hadoop 生态支持的一个全景图。
- Apache Doris 简介:下一代实时数据仓库
- Apache Doris 实时数据仓库的构建与技术选型方案
- Apache Kylin VS Apache Doris
- 抖音集团基于 Apache Doris 的实时数据仓库实践
- 腾讯云大数据“数智话”技术沙龙 第一期—云数据仓库 for Apache Doris 内容回顾
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号