购买腾讯云数据仓库 TCHouse-D 集群
购买方式一:进入腾讯云官网,登录后在官网首页单击立即选购。
购买方式二:登录腾讯云数据仓库 TCHouse-D 控制台,在集群列表页新建集群。

进入集群购买页面,按需选购 FE、BE 的集群资源规格,详细操作步骤可参见 新建集群。
注意:
建议生产集群配置如下:
FE:开启高可用,3节点,每个节点16核64G。
BE:3节点,每个节点16核64G。
购买腾讯云数据仓库 TCHouse-D 集群时,建议配置 MySQL、腾讯云数据仓库 TCHouse-D 处于同一个 VPC 内。
创建账户并赋权
1. 集群购买完毕后,可进入 腾讯云数据仓库 TCHouse-D 控制台 集群列表,单击集群 ID/名称进行集群管理。

2. 可在集群详情页中查看集群具体信息、管理 BE/FE 监控指标、配置备份恢复策略等,详细操作说明可参见 通过控制台使用腾讯云数据仓库 TCHouse-D。
3. 为更方便的进行库表操作,需进入集群详情页,单击账户管理,对库表并进行用户授权。单击新增账户,输入账户名、密码、主机后即可完成账号创建。
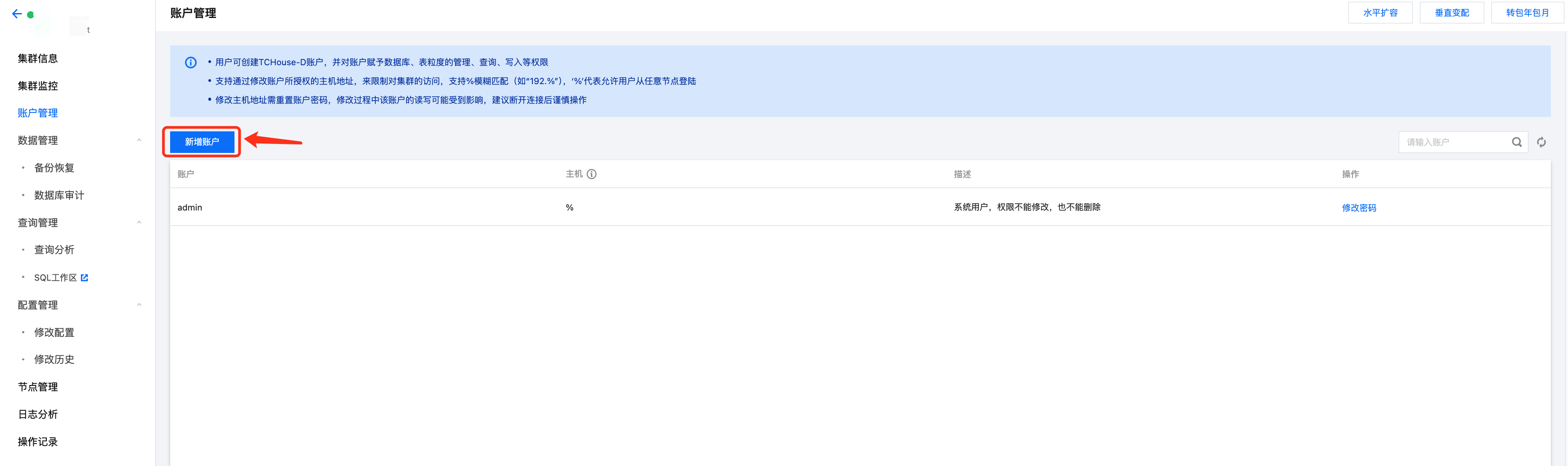
4. 账号创建完毕后,在账户列表单击修改权限按钮,即可为账号赋予相应的数据权限,支持为账户授予全部或指定库表权限,详见 控制台权限管理。
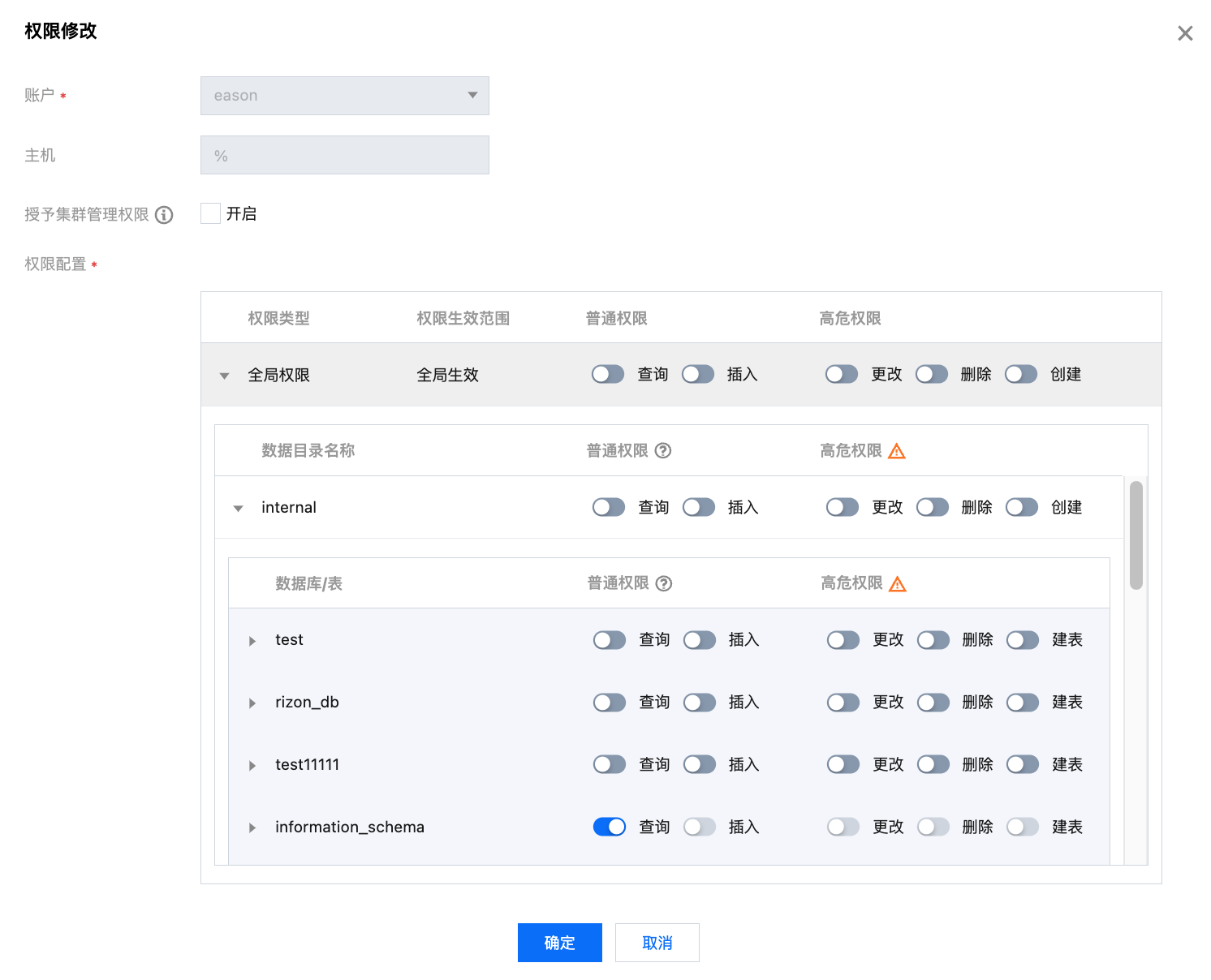
注意:
授权集群管理权限后,也将获取外部数据源的权限,但外部数据源仅支持查询,不支持插入、增删库表等。
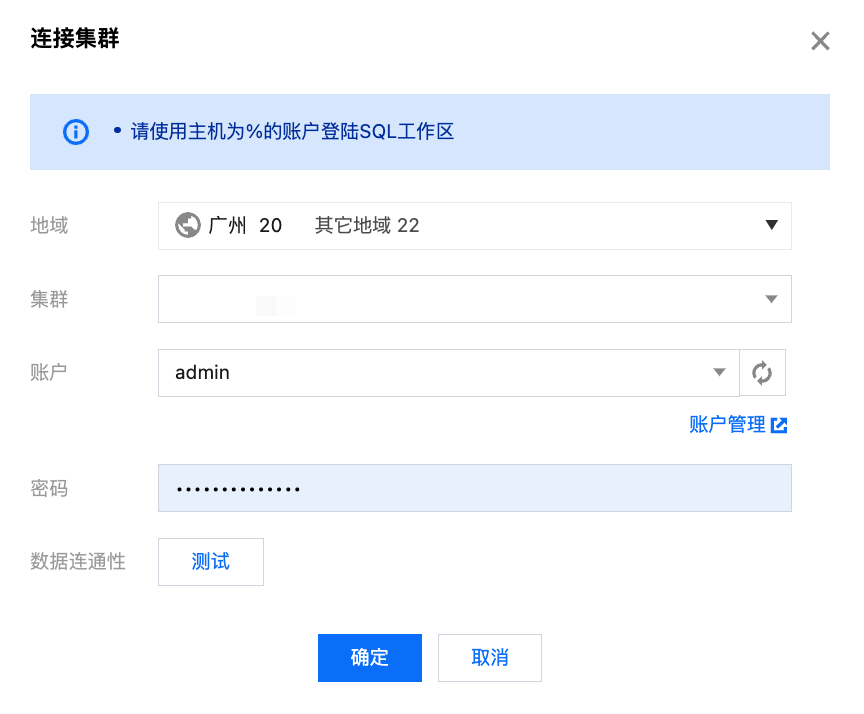
进入 SQL 工作区

进入 SQL 工作区 时,需指定集群和登录账号。
Admin 账户及具有集群管理权限的账户登录后,默认有所有库表的权限。
其他账户登录后,只能操作有权限的库表。
创建腾讯云数据仓库 TCHouse-D 数据库
注意:
集群创建成功后,会初始化内置catalog(Internal)和2个系统数据库,请勿对系统数据库进行增删改等操作:
1. 系统库 doris_audit_db__:审计日志数据库,用于记录 Doris 系统的操作日志和安全事件。通过审计日志,可以追踪系统的操作历史和安全事件,保证系统的安全性和可靠性。
2. 系统库 information_schema:即腾讯云数据仓库 TCHouse-D 的元数据数据库,可通过查询 information_schema 来获取系统的元数据信息,了解系统的结构和属性,方便进行数据管理和查询操作。
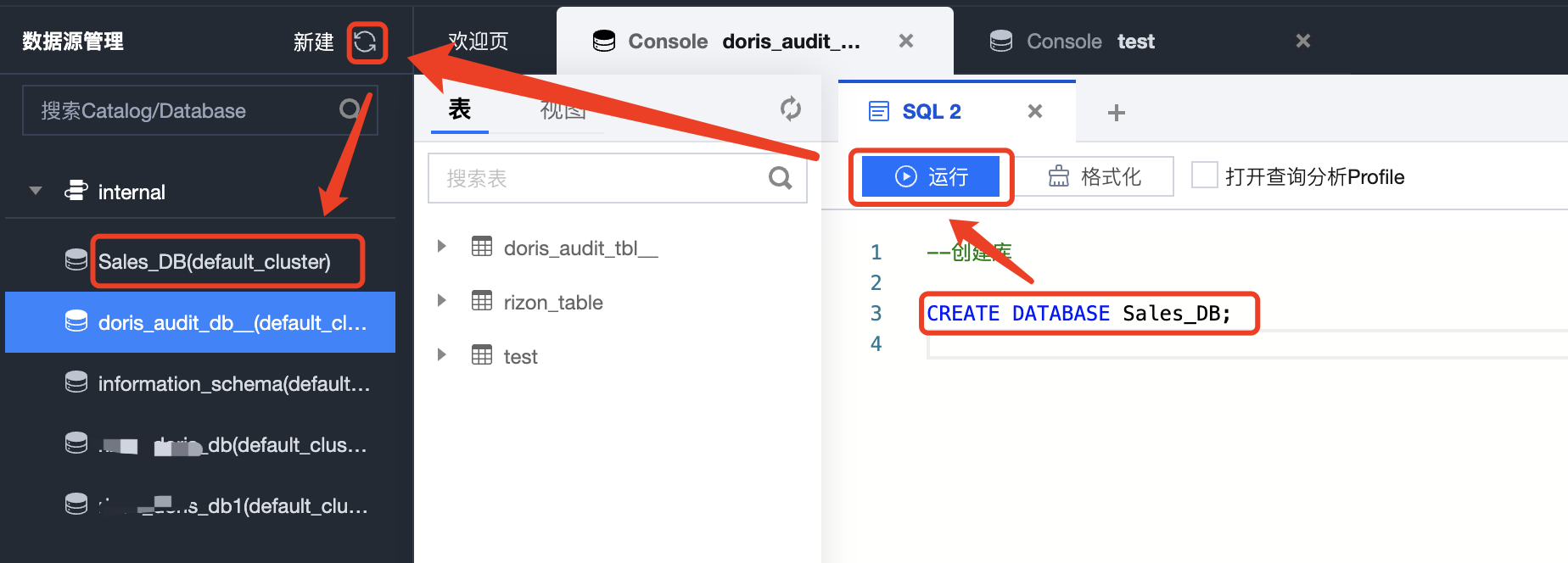
在任意库下的 SQL 编译框中输入建库的 SQL 语句,并单击运行后即可完成建库操作:
CREATE DATABASE Sales_DB;
建库完成后,单击数据源管理中的刷新,即可在目录树中回显新建的数据库。
创建腾讯云数据仓库 TCHouse-D 数据表
双击左侧库名,即可切换至此数据库下,然后可在弹出的 SQL 编译框中进行建表操作。
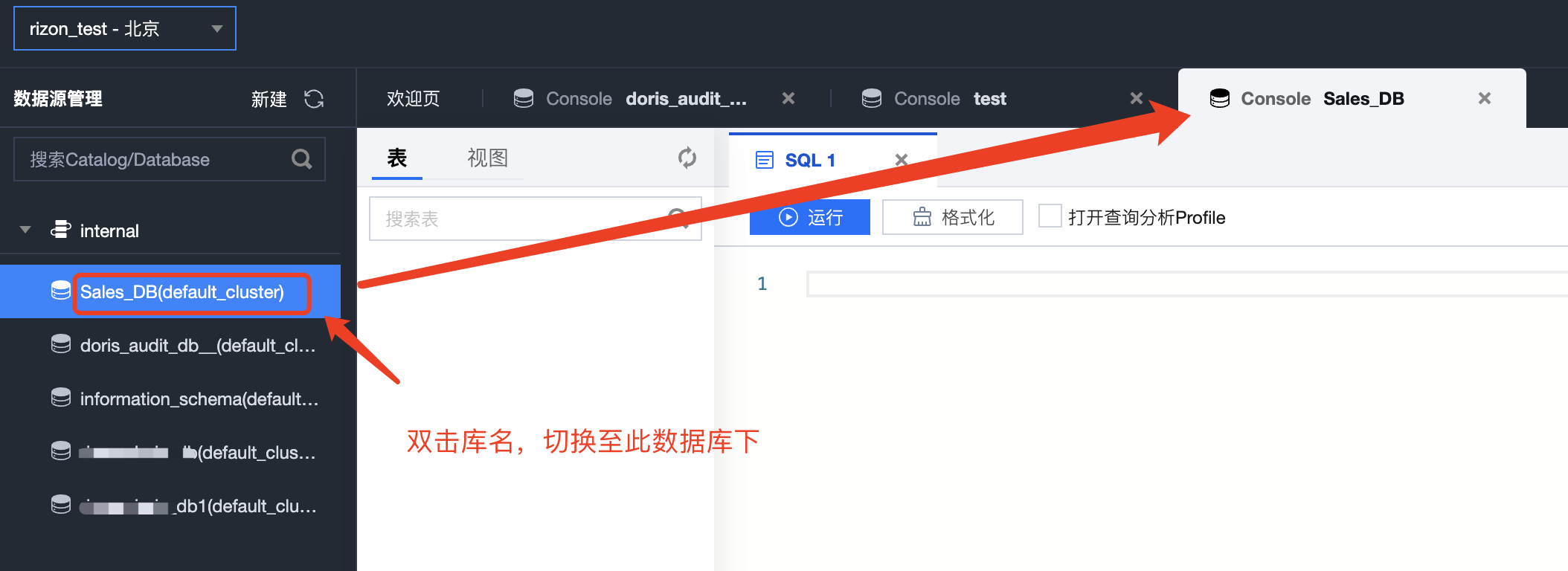
表模型选择
腾讯云数据仓库 TCHouse-D 支持 Aggregate、Unique 和 Duplicate三种表模型,数据模型在建表时就已经确定,且无法修改。所以,选择一个合适的数据模型非常重要。
说明:
源端有主键的:建议创建 Unique 表模型接入数据。
源端没有主键的:建议创建 Duplicate 表模型接入数据。
注意:
key 列在表中的顺序需要和在 key 定义的顺序保持一致。
String/text 类型的列不适合作为 key 列,可以转为 varchar 类型。
1. Aggregate 模型:可以通过预聚合,极大地降低聚合查询时所需扫描的数据量和查询的计算量,非常适合有固定模式的报表类查询场景,但该模型对 count( * ) 查询很不友好。
建表 Demo 如下:
CREATE TABLE site_visit(siteid INT,city SMALLINT,username VARCHAR(32),pv BIGINT SUM DEFAULT '0')AGGREGATE KEY(siteid, city, username)DISTRIBUTED BY HASH(siteid) BUCKETS 10;
2. Unique 模型:针对需要唯一主键约束的场景,Unique key 相同时,新记录覆盖旧记录,可以保证主键唯一性约束,适用于有更新需求的分析业务。
建表 Demo 如下:
CREATE TABLE sales_order(orderid BIGINT,status TINYINT,username VARCHAR(32),amount BIGINT DEFAULT '0')UNIQUE KEY(orderid)DISTRIBUTED BY HASH(orderid) BUCKETS 10;
3. Duplicate 模型:相同的行不会合并,适合任意维度的 Ad-hoc 查询。虽然无法利用预聚合的特性,但是不受聚合模型的约束,可以发挥列存模型的优势(列裁剪、向量执行等)。
建表 Demo 如下:
CREATE TABLE session_data(visitorid SMALLINT,sessionid BIGINT,visittime DATETIME,city CHAR(20),province CHAR(20),ip varchar(32),brower CHAR(20),url VARCHAR(1024))DUPLICATE KEY(visitorid, sessionid)DISTRIBUTED BY HASH(sessionid, visitorid) BUCKETS 10;
腾讯云数据仓库 TCHouse-D 表分区分桶建议
腾讯云数据仓库 TCHouse-D 支持两层的数据划分,第一层是 Partition(分区),支持 Range 和 List 的划分方式。第二层是 Bucket(分桶),仅支持 Hash 的划分方式。一个表可以不分区,但必须分桶。
说明:
数据量较小的场景:推荐使用一级分片表(即指不分区的分桶表)。
数据量较大或数据有明确日期归属的场景(如事实表):推荐使用两级分片表,即既分区又分桶的表。
1. 创建一级分片表的示例:
Create Table `user_login_new`(`loginId` bigint NOT NULL COMMENT '登录Id',`userAcount` varchar(255)NOT NULL COMMENT '用户账号',`onlineTime` decimal(10, 2) NOT NULL DEFAULT '0.00' COMMENT '玩家在线时长,单位:小时',`androidVersion` varchar)UNIQUE KEY (`loginid`)COMMENT '用户归因登录表'DISTRIBUTED BY HASH(`loginid`) buckets 8;
注意:
创建分桶的语法:DISTRIBUTED BY HASH(`loginid`) buckets 8;
其中两个关键点:
1. 分桶列:分桶列有一定要求:必须是key列,类型不能是string,text。
2. 分桶数量:根据数据大小确定,最好保证分桶后每个桶的大小在1-10G。
2. 创建两级分片表的示例
Create Table `user_login_beifen`(`loginId` bigint NOT NULL COMMENT '登录Id',`loginTime` date NOT NULL COMMENT '登录时间',`loginIp` varchar(255)NOT NULL COMMENT '登录ip',`loginProvince` varchar(255)COMMENT '登录地区',`onlineTime` decimal(10, 2) NOT NULL DEFAULT '0.00' COMMENT '玩家在线时长,单位:小时')UNIQUE KEY (`loginId`,`loginTime`)COMMENT '用户归因登录表'PARTITION BY RANGE(`loginTime`)(PARTITION `p201701` VALUES LESS THAN ("2017-02-01"),PARTITION `p201702` VALUES LESS THAN ("2017-03-01"),PARTITION `p201703` VALUES LESS THAN ("2017-04-01"))DISTRIBUTED BY HASH(`loginId`) buckets 8;
注意:
上为创建 Range 类型分区的语法示例,有几个关键点:
1. 分区列可以是一列或多列,但都需要是key列。
2. 创建分区时不可添加范围重叠的分区。
3. 数据写入前数据归属的分区要提前创建好。
也支持预先创建分区、自动创建分区,即动态分区特性:例子如下:
Create Tableuser_login_beifen2(loginIdbigint NOT NULL COMMENT '登录Id',loginTimedate NOT NULL COMMENT '登录时间',loginIpvarchar(255)NOT NULL COMMENT '登录ip',loginProvincevarchar(255)COMMENT '登录地区',onlineTimedecimal(10, 2) NOT NULL DEFAULT '0.00' COMMENT '玩家在线时长,单位:小时' ) UNIQUE KEY (loginId,loginTime) COMMENT '用户归因登录表' PARTITION BY RANGE(loginTime)() DISTRIBUTED BY HASH(loginId) buckets 8 PROPERTIES ("dynamic_partition.time_unit" = "DAY","dynamic_partition.start" = "-10","dynamic_partition.end" = "3","dynamic_partition.buckets" = "8","dynamic_partition.create_history_partition" = "true","dynamic_partition.prefix" = "p" );--上述建表demo预先创建好今天之前10天至后3天的分区表,按loginTime列分区,分区名以'p'开头,每个分区内分成8个桶。
腾讯云数据仓库 TCHouse-D 索引使用建议
如果经常对某列进行精确匹配过滤并且列的基数比较高,建议在此列上创建 bloom filter 索引。
注意:
1.2.4及前序版本上,不建议使用 “Merge-on-Write” 功能。
1.2.4及前序版本上,不建议使用 “auto bucket” 功能。
1.2.4及前序版本上,不建议使用 “动态Schema表” 功能。
集群配置建议
创建集群时,会初始化以下5个配置文件,说明如下:
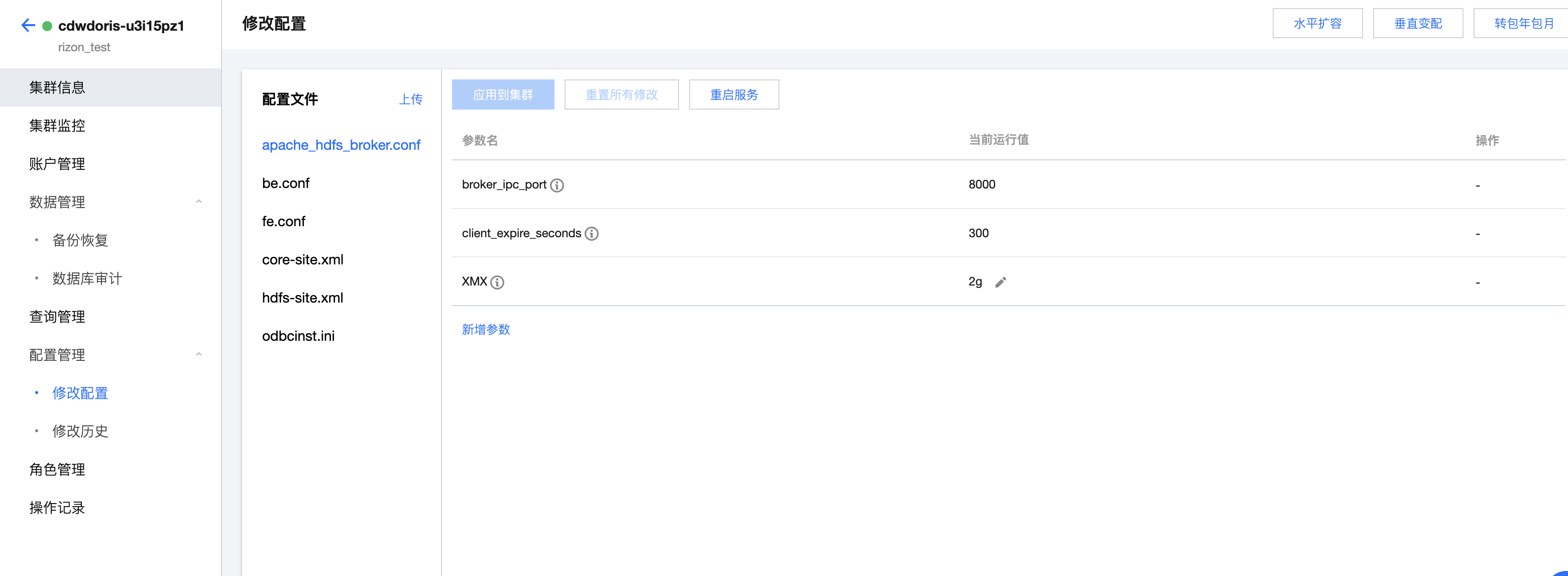
配置文件 | 配置建议 |
apache_hdfs_broker.conf | 建议保持默认配置不变 |
be.conf | 大多数配置保持默认配置不变,需特殊注意的参数如下: compaction_task_num_per_disk:每个磁盘可并发执行的 compaction 任务数量,默认值是2,如果想要提高导入速度可适当调大。具体可参考社区文档 BE 配置项 。 disable_auto_compaction=true:建议不要调整。 |
fe.conf | 大多数配置保持默认配置不变,需特殊注意的参数如下: max_running_txn_num_per_db: 控制同一个 DB 的并发导入个数,默认值100,当集群中有过多的导入任务正在运行时,可适当调大。 |
core-site.xml | 建议保持默认配置不变。 |
hdfs-site.xml | 建议保持默认配置不变。 |
odbcinst.ini | 建议保持默认配置不变。 |



