业务应用场景中,常常需要实时捕获数据库的数据变更并将其同步至其他系统。该过程可通过 Debezium 实现, Debezium 用于监控数据库变化和捕捉数据变动事件,并以事件流的形式导出。
本文将说明如何使用 Debezium 采集云数据库 PostgreSQL 中的数据。
前提条件
准备处于同一 VPC 下的云数据库 PostgreSQL 实例和云服务器实例。
步骤1:部署环境
1.云服务器配置 java 环境
Debezium 属于 java 应用,需要在云服务器配置 java 环境,为其正常运行提供基础。
依次执行下方命令,下载 jdk18 安装包并解压。
#下载jdk8[root@VM-10-18-tencentos ~]# wget --no-check-certificate --header "Cookie: oraclelicense=accept-securebackup-cookie" \\https://download.oracle.com/java/18/archive/jdk-18.0.2_linux-x64_bin.tar.gz#解压安装包[root@VM-10-18-tencentos ~]# tar -zxvf jdk-18.0.2_linux-x64_bin.tar.gz -C /usr/local/#重命名目录[root@VM-10-18-tencentos ~]# sudo mv /usr/local/jdk-18.0.2 /usr/local/jdk18
执行下列命令,进入配置文件内容。
[root@VM-10-18-tencentos ~]# vim /etc/profile
按 i 键进入编辑模式,在文件末尾添加以下内容:
export JAVA_HOME=/usr/local/jdk18export PATH=$JAVA_HOME/bin:$PATHexport CLASSPATH=.:$JAVA_HOME/lib
添加完毕后,按 esc 键退出编辑模式,再输入 :wq 保存修改并退出文件内容。
执行以下命令使配置立即生效。
[root@VM-10-18-tencentos ~]# source /etc/profile
可通过以下命令检查 java 是否配置成功。
[root@VM-10-18-tencentos ~]# java -versionjava version "18.0.2" 2022-07-19Java(TM) SE Runtime Environment (build 18.0.2+9-61)Java HotSpot(TM) 64-Bit Server VM (build 18.0.2+9-61, mixed mode, sharing)
如果显示 java 版本信息,说明配置成功。
2.本地 Kafka 部署
您可选择手动在官网 Apache Kafka 下载自己需要的版本的二进制包( Binary download ),然后上传到 CVM 上。具体请参见 Linux 系统通过 FTP 上传文件到云服务器 。
也可直接执行以下命令下载,版本号可根据实际需要自行替换。
[root@VM-10-18-tencentos ~]# wget https://downloads.apache.org/kafka/3.7.2/kafka_2.13-3.7.2.tgz
将 kafka 安装包下载到 CVM 之后,依次执行以下命令完成安装。
#创建kafka的安装目录[root@VM-10-18-tencentos ~]# mkdir -p /data/zookeeper#解压kafka安装包[root@VM-10-18-tencentos ~]# tar -zxvf kafka_2.13-3.7.2.tgz -C /data/#重命名解压后的目录[root@VM-10-18-tencentos ~]# cd /data/[root@VM-10-18-tencentos data]# mv kafka_2.13-3.7.2 kafka_dev
执行下行命令,进入 Zookeeper 配置文件。
root@VM-10-18-tencentos data]# cd /data/kafka_dev/config[root@VM-10-18-tencentos config]# vim /data/kafka_dev/config/zookeeper.properties
进入文件内后,按i键进入编辑模式,找到 dataDir ,将其修改为 /data/zookeeper ,确保 dataDir 指向正确的存储路径。
dataDir =/data/zookeeper
修改完成后,按 esc 键退出编辑模式,再直接输入 :wq 保存修改并退出文件内容。
3.修改 Kafka 配置文件
执行以下命令,创建 kafka 日志目录。
[root@VM-10-18-tencentos config]# mkdir -p /data/kafka_dev/logs/
执行以下命令,进入 kafka 配置文件。
[root@VM-10-18-tencentos config]# vim connect-distributed.properties
进入文件后,按 i 键进入编辑模式,修改以下内容。若云服务器与云数据库处于同一 VPC 下,建议填写云服务器的内网 IP 地址。
listeners=PLAINTEXT://部署kafka所在机器的ip:9092 #若该项所在行首有#号,需将#删去并修改log.dirs=/data/kafka_dev/logs/connect.logzookeeper.connect=部署kafka所在机器的ip:2181
执行以下命令,进入 kafka connect 的配置文件 connect-distributed.properties 。
[root@VM-10-18-tencentos config]# vim connect-distributed.properties
进入文件后,按 i 键进入编辑模式,修改以下内容。若云服务器与云数据库处于同一 VPC 下,建议填写云服务器的内网 IP 地址。
group.id=connect-clusterbootstrap.servers=部署kafka所在机器的ip:9092# 定义插件路径plugin.path=/data/kafka_connect/plugins
4.启动 Zookeeper 和 Kafka
使用以下命令启动 zookeeper 。
[root@VM-10-18-tencentos config]# cd /data/kafka_dev[root@VM-10-18-tencentos kafka_dev]# nohup bin/zookeeper-server-start.sh config/zookeeper.properties &> zookeeper.log &
可输入以下命令确认 zookeeper 任务是否正常在后台运行。
[root@VM-10-18-tencentos kafka_dev]# jobs
若返回信息包含 zookeeper 和 running ,则正常运行。
再执行以下命令启动 kafka 。
[root@VM-10-18-tencentos kafka_dev]# nohup bin/kafka-server-start.sh config/server.properties &> kafka.log &
可输入以下命令确认 kafka 任务是否正常在后台运行。
[root@VM-10-18-tencentos kafka_dev]# jobs
若返回信息包含 kafka 和 running,则正常运行。
步骤2:在 PostgreSQL 中创建逻辑复制发布
逻辑发布( Publication )定义了哪些表的数据变更会被发布,Debezium 通过绑定到逻辑发布上的逻辑复制槽( Failover Slot )来捕获变更数据。对于逻辑复制槽的具体说明请参见 逻辑复制槽故障转移(Failover Slot)。因此,您需要创建 publication 和 failover slot ,才能实现数据的捕获和同步。
1.开启逻辑复制
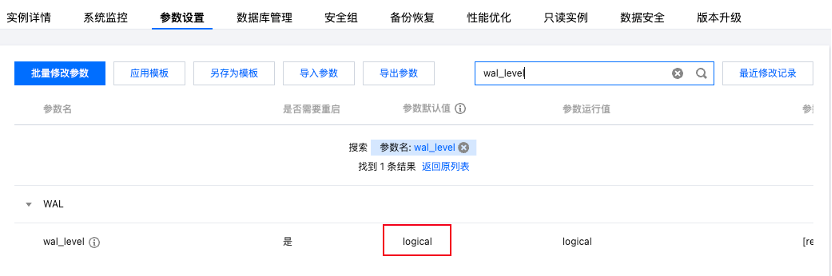
进入控制台,找到需要采集数据的实例,在实例详情页面点击参数设置,将 wal_level 参数默认值修改为为 logical ,参数值修改后需要重启实例才能生效。
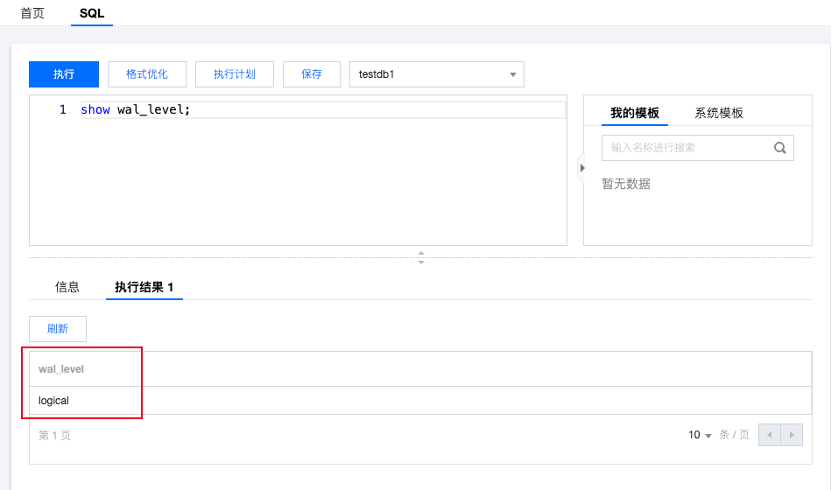
修改后,可登录实例,使用以下查询语句查看 wal_level 是否修改成功。
show wal_level;
2.创建 Publication (逻辑发布)
使用类型为 pg_tencentdb_superuser 的账号,登录需要发布的数据库控制台。执行以下命令创建 publication 。
CREATE PUBLICATION pg_demo_publication FOR ALL TABLES;
其中, pg_demo_publication 指该 publication 的名称,您可自行定义, FOR ALL TABLES 指将当前数据库中的全部表都进行发布。若您需要指定发布哪几张表,则可选择执行以下命令:
CREATE PUBLICATION pg_demo_publication FOR table_name1, table_name2;
您可执行以下命令查看刚刚创建的 publication ,确认要发布的表。
SELECT * FROM pg_publication_tables WHERE pubname = ‘pg_demo_publication’;
若希望确认有哪些操作会进行发布,可执行以下命令查看。
SELECT * FROM pg_publication WHERE pubname = ‘pg_demo_publication’;
pg_publication 表用于存储所有已创建的 publication 信息。其中, puballtables 列为 true ,则表示发布数据库中的所有表; pubinsert 列为 true ,表示发布表的 insert 操作,其他列相同。
执行以下命令,创建 tencentdb_failover_slot 插件。
CREATE EXTENSION tencentdb_failover_slot;
执行以下命令,创建 logical_failover_slot 。
SELECT pg_create_logical_failover_slot(‘failover_alot_name’,’pgoutput’);
创建完成后,可使用以下命令查看 Failover Slot 信息。
SELECT * FROM pg_failover_slots;
步骤3:开启 Debezium
1.安装 Debezium 插件
登录云服务器,依次执行以下命令下载 debezium-connector-postgresql 插件,并解压到指定路径。
[root@VM-10-18-tencentos ~]# mkdir -p /data/kafka_connect/plugins[root@VM-10-18-tencentos ~]# wget https://repo1.maven.org/maven2/io/debezium/debezium-connector-postgres/2.7.3.Final/debezium-connector-postgres-2.7.3.Final-plugin.tar.gz[root@VM-10-18-tencentos ~]# tar -zxvf debezium-connector-postgres-2.7.3.Final-plugin.tar.gz -C /data/kafka_connect/plugins
2.启动 kafka connect
执行以下命令启动 kafka connect 。
[root@VM-10-18-tencentos ~]# cd /data/kafka_dev[root@VM-10-18-tencentos kafka_dev]# nohup bin/connect-distributed.sh config/connect-distributed.properties &> connect.log &
3.创建 debezium connector
在云服务器执行下面的命令,进行 debezium connector 的创建。需要自行根据实际情况填写的项已为您标出。
说明:
若云服务器与云数据库 PostgreSQL 处于同一 VPC 下,建议填写云服务器机器、云数据库的内网 IP 。
curl -XPOST "http://部署kafka所在云服务器的ip:8083/connectors/" \\-H 'Content-Type: application/json' \\-d '{"name": "test_connector","config": {"connector.class": "io.debezium.connector.postgresql.PostgresConnector","database.hostname": "PostgreSQL数据库所在机器的IP","database.port": "5432","database.user": "有发布权限的PostgreSQL用户名","database.password": "发布用户的密码","database.dbname": "创建publication的数据库","database.server.name": "pg_demo","slot.name": "pg_demo_failover_slot","topic.prefix": "pg_demo","publication.name": "pg_demo_publication","publication.autocreate.mode": "all_tables","plugin.name": "pgoutput"}}'
需要您自行填写及可自定义的参数说明如下:
参数 | 说明 |
name | 连接器的名称,必须唯一。 |
database.hostname | 云数据库的 IP 地址。建议您填写内网 IP。 |
database.user | 用于连接云数据库的用户名。 该用户需要有足够权限完成发布。推荐使用类型为 pg_tecenten_superuser 的用户。 |
database.password | 用户的密码。 |
database.dbname | 创建 publication 的数据库名称。 |
slot.name | 逻辑复制槽的名称。 请填写之前创建的逻辑复制槽名称。 |
publication.name | 逻辑发布的名称。 请填写之前创建的逻辑发布名称。 |
您可登录控制台,使用以下命令查看 publication 。
SELECT * FROM pg_publication;
可使用以下命令查看 failover Slot 信息。
SELECT * FROM pg_failover_slots;
创建完毕后,您可通过在云服务器输入以下命令查看连接状态。
curl "http://部署kafka所在机器的ip:8083/connectors/pg_demo_connector/status"
返回的信息中包含 running 则为正常运行。
步骤4:测试数据变更
执行以下命令在 CVM 中登录云数据库。其中 -h 后填写为云数据库 IP。若云服务器与云数据库处于同一 VPC 下,建议填写为内网 IP。
[root@VM-10-18-tencentos kafka_dev]# su – postgres[postgres@VM-10-18-tencentos ~]$ /usr/local/pgsql/bin/psql -h *.*.*.* -p 5432 -U dbadmin -d postgresPassword for user dbadmin:psql (16.4, server 16.8)Type "help" for help.postgres=>
创建一张新表,插入数据进行测试。
postgres=> CREATE TABLE linktest (id SERIAL PRIMARY KEY);CREATE TABLEpostgres=> insert into linktest values(1);INSERT 0 1
观察 kafka 日志,若 kafka 正常,则连接建立成功。



