本实践详细介绍了在 EMR 科学计算集群中使用 RayDP、Spark、PyTorch 和 MLflow 构建分布式深度学习训练流程的实践教程,并对原有实践进行了优化和补充。我们以 MNIST 手写数字识别任务为例,通过 Spark 完成数据预处理,再利用 Ray 进行分布式训练,并通过 MLflow 记录模型及训练过程。
一、背景
随着深度学习模型规模和数据量的增长,单机训练的计算能力已无法满足需求。尤其是当涉及到大规模数据集时,单机训练不仅需要耗费长时间,还会面临计算资源的限制。分布式训练可以通过并行处理多个任务,充分利用集群资源,从而显著缩短训练时间、提高训练效率,并且提升模型的性能。Ray 作为一种高性能的分布式执行框架,为分布式训练提供了一个高效、灵活且易用的解决方案。
Ray 的核心是通过简洁的 API 来将函数或类转换为远程任务或有状态 actor,支持任务并行化,任务间的调度和通信。Ray 的设计强调灵活性和异构性,能够动态地在不同硬件环境中调度任务,特别适合在集群中运行高负载的训练任务。Ray 不仅支持细粒度并行的任务调度,还能进行状态管理和自定义的通信策略,从而提高整体并行效率。同时,Ray 的调度器和对象存储服务通过在集群中管理资源并缓存数据,进一步增强了分布式训练的效率。
在本实践中,我们使用 Ray 来对分布式训练过程进行优化。通过 Ray 的任务调度与资源管理,我们可以在多个工作节点之间均衡负载,快速并高效地完成训练任务。
二、任务描述
数据集 MNIST
我们使用经典的 MNIST(Modified National Institute of Standards and Technology)数据集来进行模型训练。MNIST 是一个手写数字识别数据集,包含6万张28x28的灰度图像作为训练集,另外1万张作为测试集。每张图像均为灰度图,包含一个数字(0到9),这些数字是由不同的书写者手写的。这个数据集广泛用于图像分类算法的验证,并且已经成为计算机视觉领域的一个标准数据集。
任务目标:手写数字分类
我们的任务是训练一个卷积神经网络(CNN)模型,利用MNIST数据集中的手写数字图片进行数字分类。CNN 是一种专门用于图像数据处理的神经网络,通过卷积层、池化层和全连接层的组合,可以高效地提取图像特征并进行分类。
训练完成后的模型将能够根据输入的图像,准确地识别图中的数字(0到9)。该模型不仅能够用于数字识别,还可以在实际应用中扩展为图像分类、OCR(光学字符识别)等其他任务。
模型的应用场景
训练完成的 CNN 模型可广泛应用于多个实际场景,尤其是在需要自动数字识别的任务中,例如:
手写数字识别:例如银行支票扫描、邮政编码自动识别等。
数字验证码识别:在自动化测试或网站登录时识别验证码。
自动标注和数据输入:在一些行业中,手写数据的自动分类和提取可以显著提高工作效率,减少人工错误。
通过分布式训练,我们能在合理的时间内完成对这些大规模数据集的处理,并且能够训练出更高效、更高精度的数字分类模型。
环境与依赖
本实验环境基于 EMR 科学计算集群,集群预安装了 Python 3.9、torch、tensorflow、scikit‑learn 等库。Ray、Spark、MLflow 和 Jupyter-Lab 组件安装位置为
/usr/local/service。训练脚本通过ray.init(address="auto")自动连接到集群中的 Ray head 节点。三、实践流程
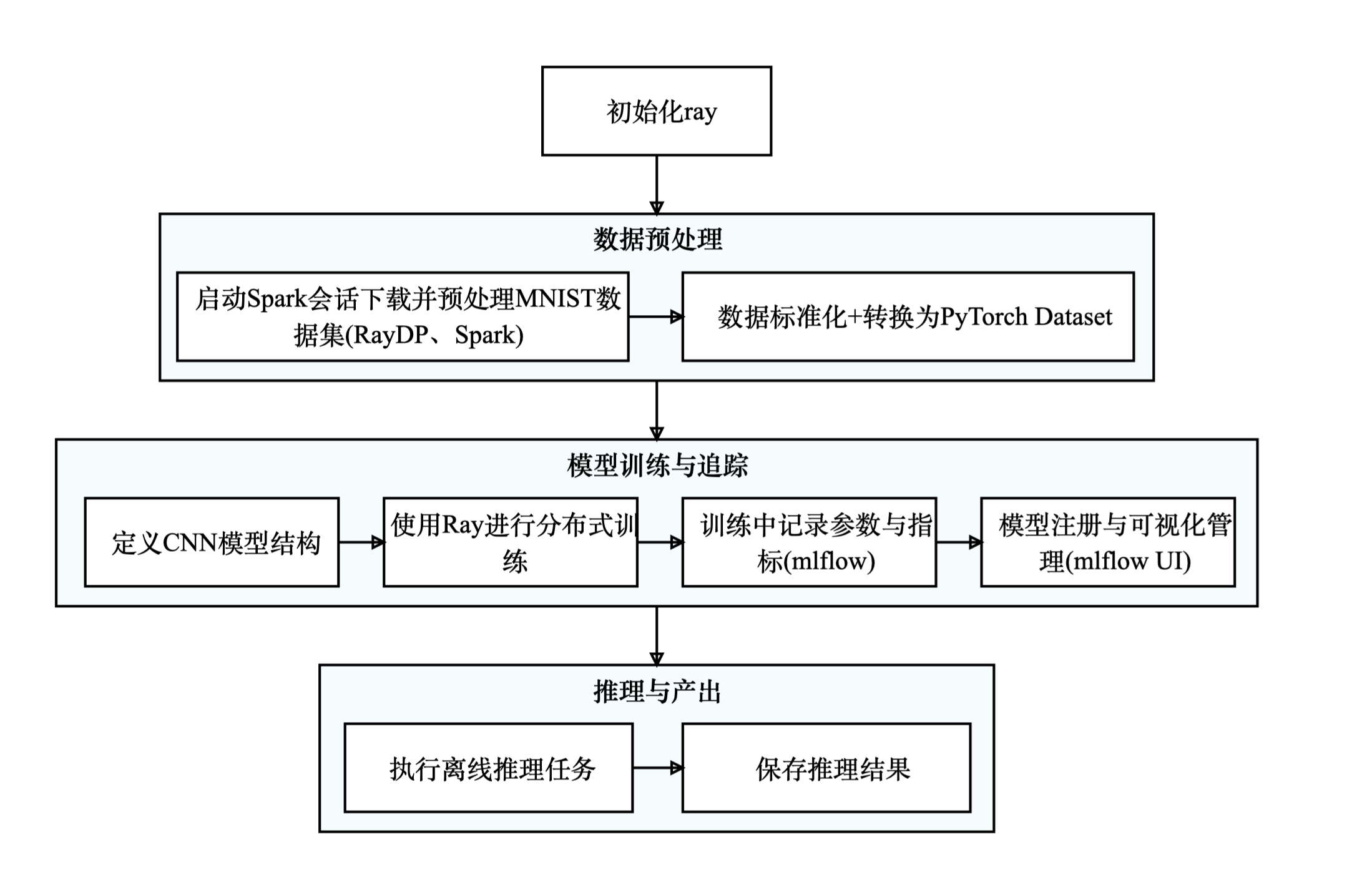
实践流程包括:
1. 初始化 Ray 并连接到集群。
2. 使用 RayDP 启动 Spark 会话,下载并预处理 MNIST 数据。
3. 将 Spark DataFrame 标准化并转换为 PyTorch 的数据集。
4. 设计卷积神经网络模型,使用 Ray 的 remote 函数将训练任务分布到多个 worker。
5. 进行分布式训练,各 worker 独立训练模型并定期评估。
6. 通过 MLflow 记录参数、指标和模型文件。
7. 完成离线推理任务并保存预测结果。
1.初始化 Ray 连接
首先,我们需要确保 EMR 集群上的 Ray 服务已启动,并正确连接到 Ray 集群。
import rayimport timeimport logging# 配置日志logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(name)s - %(levelname)s - %(message)s')logger = logging.getLogger("RayTrainer")# 清理已有Ray连接logger.info("清理已有Ray连接...")if ray.is_initialized():ray.shutdown()time.sleep(1)logger.info("成功关闭历史Ray连接")# 初始化Ray连接logger.info("初始化新的Ray连接...")ray.init(address="auto", ignore_reinit_error=True)logger.info("Ray自动连接成功!")
ray.init()是 Ray 的连接接口,通过它可以连接到 Ray 集群。如果 Ray 连接已存在,代码会清理并重新初始化连接,确保环境的干净。2.使用 RayDP 初始化 Spark 会话
RayDP 是 Ray 与 Spark 结合的一个框架,它帮助我们在分布式环境中使用Spark进行数据处理,同时利用 Ray 进行任务调度。
raydp.init_spark()方法用于启动 Spark 会话。import raydpfrom pyspark.sql import SparkSession# 初始化RayDP Spark会话spark = raydp.init_spark(app_name="MNIST_Preprocessing",num_executors=2,executor_cores=2,executor_memory="1GB", # 需根据集群情况配置执行节点数、内存configs={"spark.rpc.message.maxSize": "512","spark.driver.maxResultSize": "512m"})logger.info("Spark会话创建成功!")
这一步通过 RayDP 启动一个 Spark 会话,提供分布式的数据处理功能。
num_executors指定了执行节点的数量,executor_memory和executor_cores分别控制每个节点的内存和 CPU 核数。这些设置根据集群的硬件配置进行调整。3.使用 Spark 进行数据预处理
在这一步,我们将 MNIST 数据集从原始格式转换为 Spark DataFrame,并对数据进行标准化处理。标准化是常见的数据预处理步骤,用于让模型更快地收敛。
import torchvisionimport torchvision.transforms as transformsimport pandas as pdimport numpy as npfrom pyspark.ml.feature import StandardScalerfrom pyspark.sql.types import StructType, StructField, ArrayType, FloatType, IntegerTypefrom pyspark.sql.functions import udffrom pyspark.ml.linalg import Vectors, VectorUDTdef prepare_dataset_with_spark():"""使用Spark进行数据预处理"""logger.info("下载MNIST数据集...")transform = transforms.ToTensor()train_set = torchvision.datasets.MNIST(root='./data', train=True, download=True, transform=transform)test_set = torchvision.datasets.MNIST(root='./data', train=False, download=True, transform=transform)logger.info("将数据转换为Spark DataFrame...")train_images = [x.view(-1).numpy().tolist() for x, _ in train_set]train_labels = [y for _, y in train_set]train_df = pd.DataFrame({"features": train_images,"label": train_labels})test_images = [x.view(-1).numpy().tolist() for x, _ in test_set]test_labels = [y for _, y in test_set]test_df = pd.DataFrame({"features": test_images,"label": test_labels})logger.info("创建Spark DataFrame...")schema = StructType([StructField("features", ArrayType(FloatType()), True),StructField("label", IntegerType(), True)])spark_train_df = spark.createDataFrame(train_df, schema=schema)spark_test_df = spark.createDataFrame(test_df, schema=schema)logger.info("使用Spark进行标准化...")array_to_vector = udf(lambda arr: Vectors.dense(arr), VectorUDT())spark_train_df = spark_train_df.withColumn("features_vec", array_to_vector("features"))spark_test_df = spark_test_df.withColumn("features_vec", array_to_vector("features"))scaler = StandardScaler(inputCol="features_vec", outputCol="scaled_features", withStd=True, withMean=True)scaler_model = scaler.fit(spark_train_df)spark_train_df = scaler_model.transform(spark_train_df)spark_test_df = scaler_model.transform(spark_test_df)return spark_train_df, spark_test_df
MNIST 数据集下载:通过
torchvision.datasets.MNIST函数下载 MNIST 数据集,并使用transforms.ToTensor()将图像数据转换为张量。数据标准化:使用Spark的
StandardScaler对特征进行标准化,使数据分布的均值为0,方差为1。标准化后的数据有助于训练时收敛更快。4.将 Spark DataFrame 转换为 PyTorch Dataset
from torch.utils.data import DataLoader, Subset, TensorDatasetdef spark_df_to_torch_dataset(spark_df):"""将Spark DataFrame转换为PyTorch Dataset"""pandas_df = spark_df.select("scaled_features", "label").toPandas()features = np.stack(pandas_df['scaled_features'].apply(lambda x: x.toArray()))labels = pandas_df['label'].valuesfeatures_tensor = torch.tensor(features, dtype=torch.float32)labels_tensor = torch.tensor(labels, dtype=torch.long)return TensorDataset(features_tensor, labels_tensor)
通过将 Spark DataFrame 转换为 Pandas DataFrame 并提取特征和标签,将数据集转换为 PyTorch 的 TensorDataset,方便用于训练。
5.使用 Ray 进行分布式训练
Ray 的基本算法原理
Ray是一个分布式计算框架,旨在简化大规模并行和分布式计算任务。它的核心思想是将计算任务分解成较小的“任务单元”,并通过一个高度可定制的调度器在多个节点上执行。Ray 使用任务和 actor 模型:
Task:每个计算单元或工作单元,通常表示一个函数或方法调用。Ray 可以通过 @ray.remote 装饰器将函数转化为远程任务,并在集群的不同节点上调度执行。
Actor:一种有状态的计算单元,能够在多次调用间保存状态,并根据输入产生输出。Actor 适用于需要持久化状态并进行多次计算的场景。
Ray 的任务调度器可以动态地选择最合适的节点来运行这些任务,支持细粒度的任务调度和资源管理。这些设计使得 Ray 能够高效地处理大规模的并行计算任务,例如深度学习训练、数据处理和科学计算。
使用@ray.remote实现分布式训练
Ray 通过
@ray.remote装饰器将训练任务分配到多个 worker 中,使得每个 worker 可以处理不同的数据分片,从而加速训练过程。@ray.remotedef train_worker(worker_id, num_workers, train_dataset, test_dataset, epochs=3):"""每个worker的训练任务"""device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# 分配数据给每个workerworker_indices = list(range(worker_id, len(train_dataset), num_workers))worker_train_set = Subset(train_dataset, worker_indices)train_loader = DataLoader(worker_train_set, batch_size=64, shuffle=True)test_loader = DataLoader(test_dataset, batch_size=64, shuffle=False)model = SimpleCNN().to(device)optimizer = optim.Adam(model.parameters(), lr=0.001)criterion = nn.CrossEntropyLoss()# 训练过程for epoch in range(epochs):model.train()total_loss = 0correct = 0total = 0for data, target in train_loader:data, target = data.to(device), target.to(device)optimizer.zero_grad()output = model(data)loss = criterion(output, target)loss.backward()optimizer.step()total_loss += loss.item()_, predicted = torch.max(output.data, 1)total += target.size(0)correct += (predicted == target).sum().item()train_accuracy = 100 * correct / totalmodel.eval()test_correct, test_total = 0, 0with torch.no_grad():for data, target in test_loader:data, target = data.to(device), target.to(device)output = model(data)_, predicted = torch.max(output.data, 1)test_total += target.size(0)test_correct += (predicted == target).sum().item()test_accuracy = 100 * test_correct / test_totalreturn worker_id, test_accuracy
Ray 的分布式训练:使用
@ray.remote将训练过程并行化,将数据分片分配给不同的 worker。每个 worker 都训练部分数据,并定期计算精度,最终汇总结果。Ray 的分布式调度:Ray 能够根据任务的需求动态调度资源,将计算任务分配给合适的 worker 节点。
6.使用 MLflow 记录训练过程和模型
在训练过程中,我们使用 MLflow 记录模型的参数、指标和文件,方便后续管理和复现。
import mlflowimport mlflow.pytorchdef log_model_to_mlflow(model_path, accuracy):"""将模型记录到MLflow"""mlflow.set_tracking_uri("<http://localhost:5000")> # 修改为跟踪服务器mlflow.set_experiment("MNIST_Classification")with mlflow.start_run():mlflow.log_param("model_type", "SimpleCNN")mlflow.log_param("optimizer", "Adam")mlflow.log_param("learning_rate", 0.001)mlflow.log_metric("accuracy", accuracy)model = SimpleCNN()model.load_state_dict(torch.load(model_path))mlflow.pytorch.log_model(model, "model", registered_model_name="MNIST_Classifier")mlflow.log_artifact(model_path, "model_files")
使用
mlflow.pytorch.log_model()将训练好的模型和相关参数记录到 MLflow,便于后续的模型管理和实验追踪。使用 MLflow UI 查看实验记录与模型文件
在完成模型训练后,MLflow WebUI 提供了图形化界面,方便我们追踪、比较和管理不同的实验运行结果。
实验总览界面(Experiments)
如下图所示,每一次模型训练都会作为一个独立的 run 被记录,本案例中创建的实验目录为
MNIST_Classification。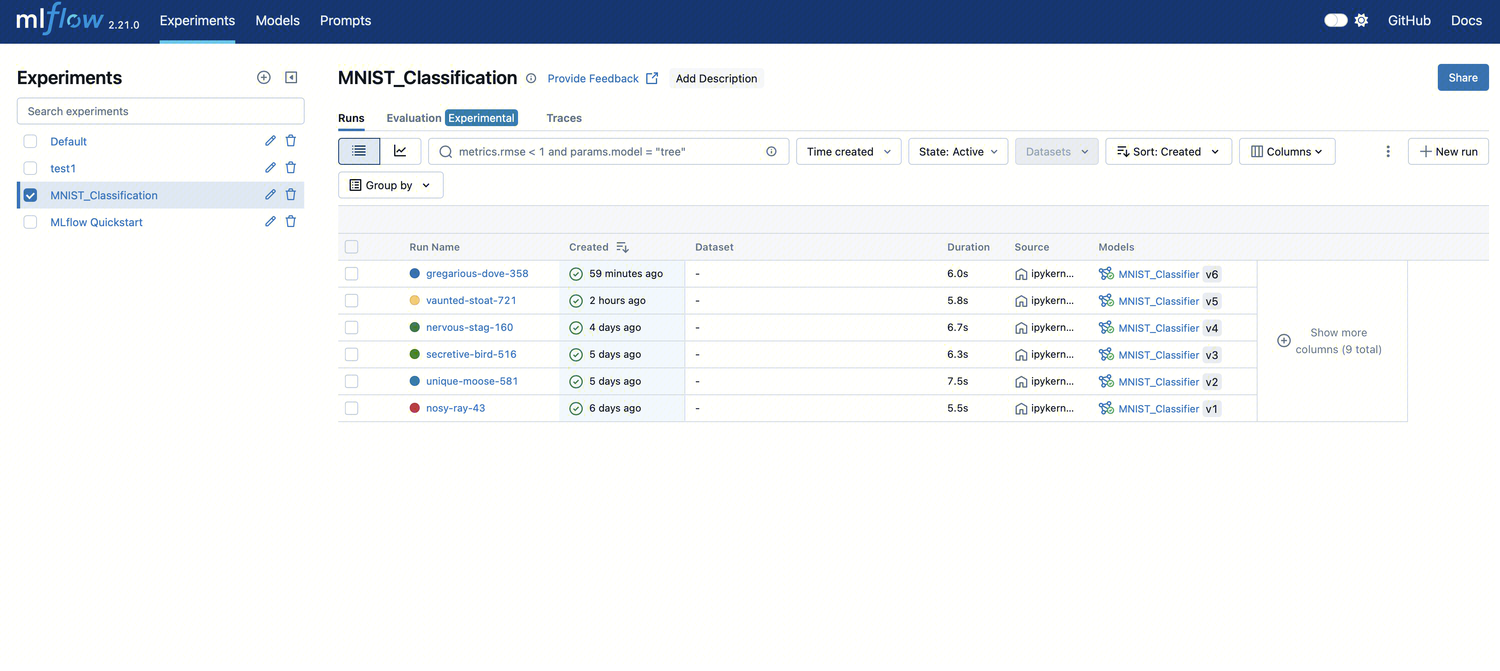
在该页面可以看到以下信息:
Run Name:自动生成的运行名称
Created:运行时间
Duration:运行耗时
Models:已注册模型的版本(例如 MNIST_Classifier v6)
Metrics & Parameters:支持在顶部的搜索框中筛选结果,例如:
metrics.rmse < 1 and params.model = "tree"筛选器支持分组、排序、状态筛选、字段列控制等
单击任意一行可进入该 run 的详细页面。
Run 详情页
单击某条训练后,会跳转到该训练运行的详细页面。
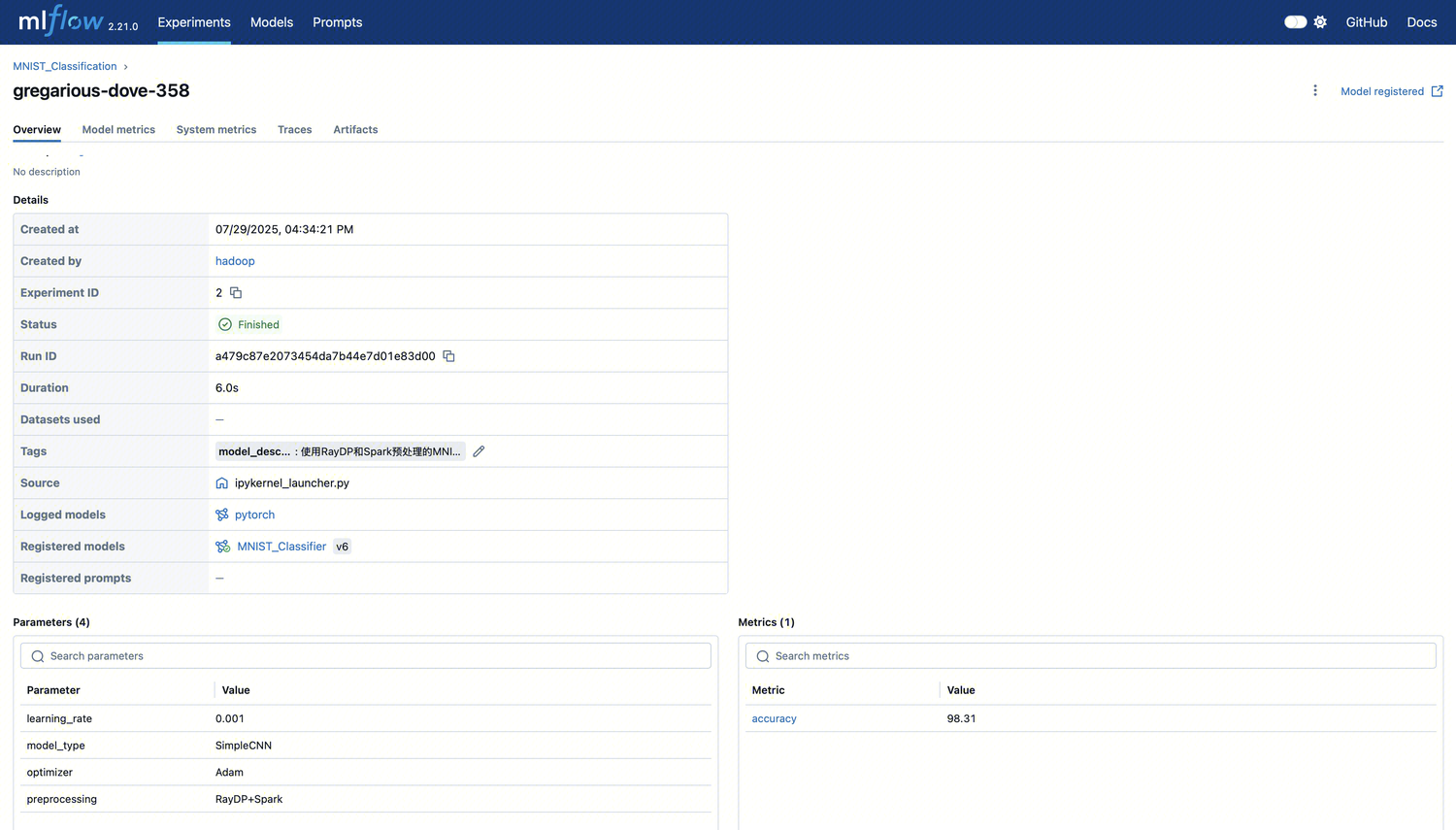
分类 | 描述 |
Status | 当前训练状态(Finished / Failed) |
Parameters | 训练使用的超参数(例如 learning rate、optimizer 等) |
Metrics | 模型评估指标(例如 accuracy=98.31) |
Source | 执行脚本路径(例如 ipykernel_launcher.py) |
Logged models | 使用的模型框架(例如 PyTorch) |
Registered models | 注册的模型名称和版本(例如 MNIST\\_Classifier v6) |
Tags | 自定义标记信息(例如模型用途、架构、备注等) |
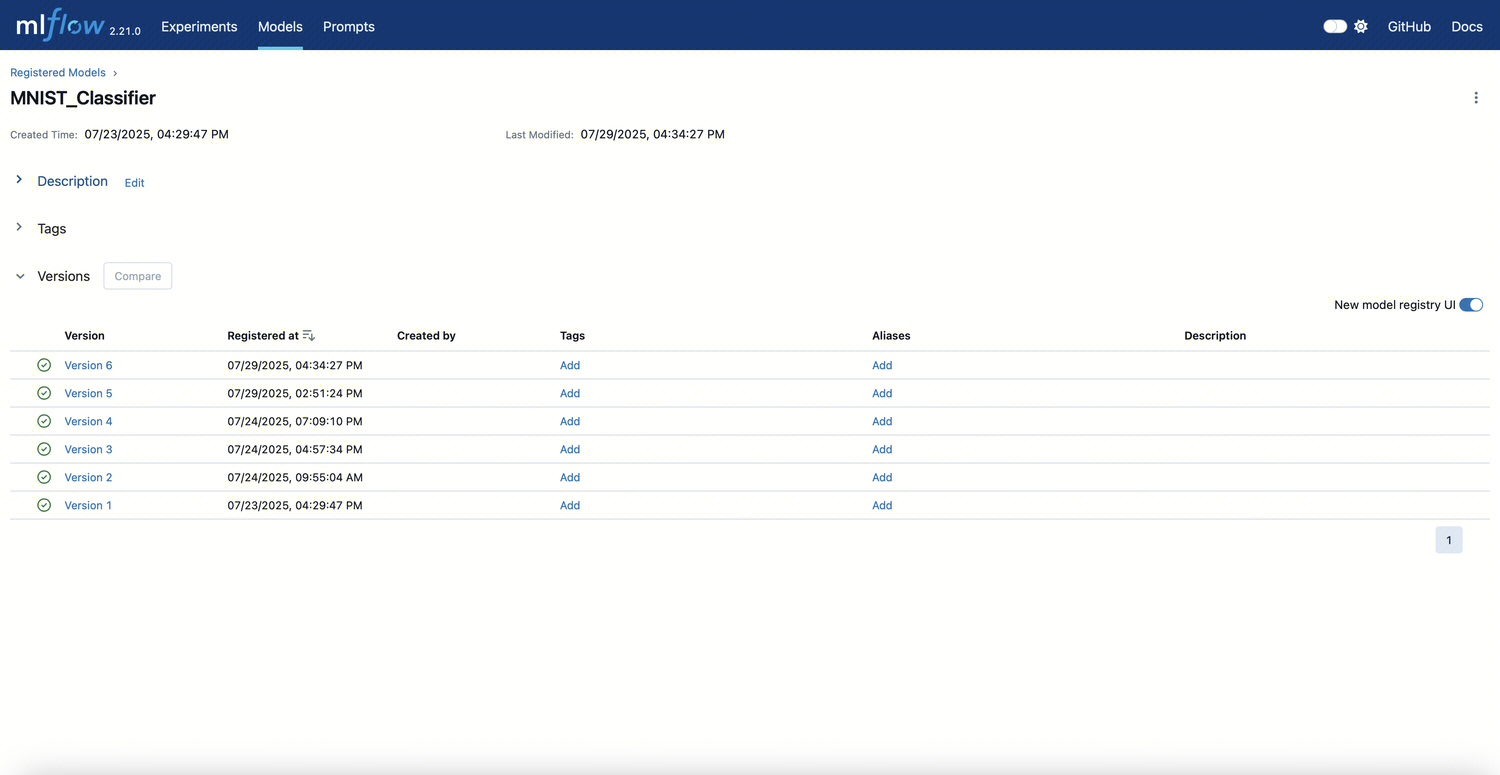
model页
可查看所有注册的模型,单击模型可查看模型具体信息,包括:
查看各版本注册时间、创建人、说明等
单击任一版本,跳转查看具体训练参数、指标、模型文件结构
为模型添加 Tag、Alias
版本对比
与Experiments页面联动,追踪来源 run
方便用户进行生命周期管理
模型与文件管理(Artifacts)
单击“Artifacts”标签页,可以查看当前 run 所记录的所有模型文件及依赖环境:
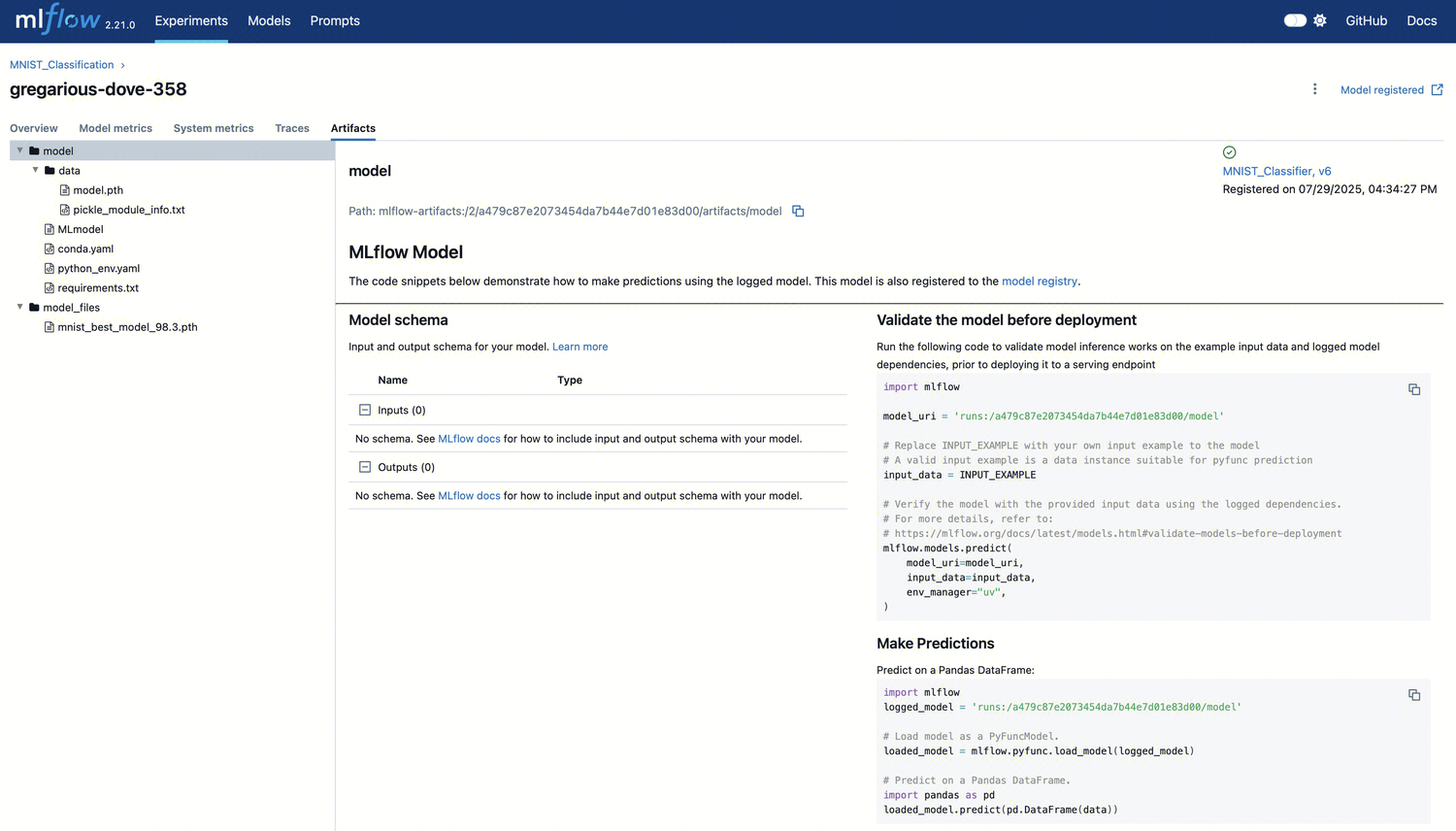
可以看到以下几类内容:
MLmodel:模型元信息文件,描述模型输入输出接口、依赖等
model\\_files/:实际的模型权重文件
conda.yaml / requirements.txt:模型所依赖的 Python 包信息
Python 环境信息:方便复现和部署模型
7.离线推理
通过训练好的模型进行离线推理,并将结果保存为 CSV 文件。
def offline_inference(model, data):"""使用训练好的模型进行推理"""model.eval()with torch.no_grad():inputs = torch.tensor(data, dtype=torch.float32)predictions = model(inputs)# 获取每个样本的预测类别(即最大概率对应的类别)predicted_classes = torch.argmax(predictions, dim=1)return predicted_classesdef perform_offline_inference(model_path, data):"""执行离线推理并保存结果"""logger.info(f"加载模型: {model_path}...")# 加载训练好的模型model = SimpleCNN()model.load_state_dict(torch.load(model_path))# 执行离线推理logger.info("开始离线推理...")predictions = offline_inference(model, data)# 将预测类别保存到CSV文件result_df = pd.DataFrame(predictions.numpy(), columns=["predictions"])result_df.to_csv("offline_predictions.csv", index=False)logger.info("离线推理完成,结果已保存至 offline_predictions.csv")
总结
本文详细介绍了如何在 EMR 集群中使用 RayDP、Spark、PyTorch 和 MLflow 进行分布式深度学习训练。通过 Ray 的分布式任务调度和资源管理,我们能够加速训练过程,并在训练结束后通过 MLflow 记录模型和训练过程。同时,离线推理功能提供了批量预测的能力,便于实际应用中进行数字识别任务的自动化。



