Flink 简介
Apache Flink 是一个可以处理流数据的实时处理框架,用于在无界和有界数据流上进行有状态的计算。Flink 能在所有常见集群环境中运行,并能以内存速度和任意规模进行计算。
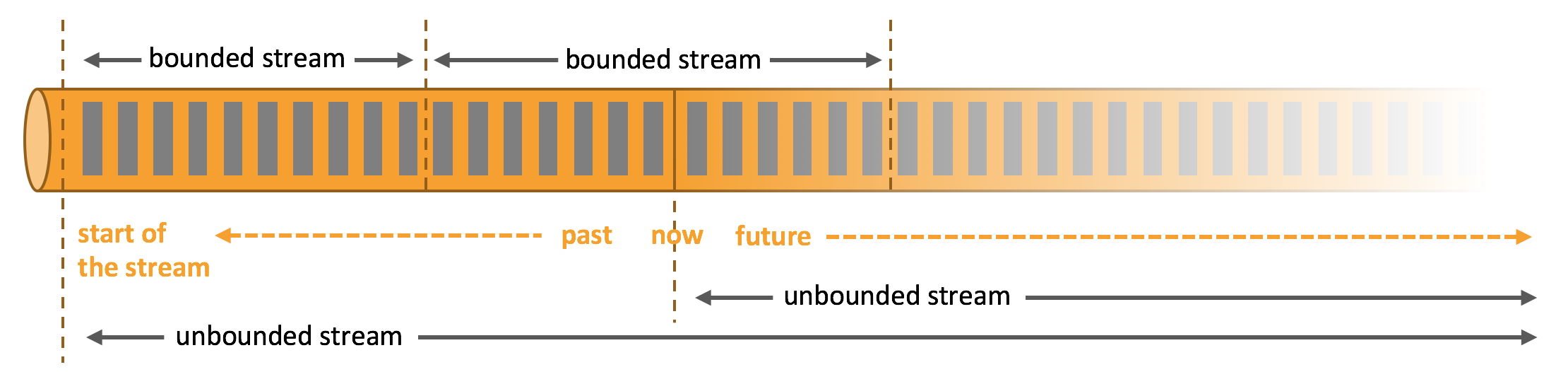
Apache Flink 擅长处理无界和有界数据集。Flink runtime 能够通过对时间和状态的精确控制处理无界数据流,也能够使用为固定大小数据集设计的算法和数据结构对有界数据集进行处理,并达到出色的性能。
应用程序可能会使用来自各种数据源(如消息队列或分布式日志,如 Apache Kafka 或 Kinesis)的实时数据。Flink 提供了 Apache Kafka 连接器,用于从 Kafka topic 中读取或者向其中写入数据,可提供一次精确的处理语义。
操作步骤
步骤1:获取 CKafka 实例接入地址
1. 登录 CKafka 控制台。
2. 在左侧导航栏选择实例列表,单击实例的“ID”,进入实例基本信息页面。
3. 在实例的基本信息页面的接入方式模块,可获取实例的接入地址,接入地址是生产消费需要用到的 bootstrap-server。

步骤2:创建 Topic
1. 在实例基本信息页面,选择顶部Topic管理页签。
2. 在 Topic 管理页面,单击新建,创建一个名为 test 的 Topic,接下来将以该 Topic 为例介绍如何消费。

步骤3:添加 Maven 依赖
pom.xml 配置如下:
<?xml version="1.0" encoding="UTF-8"?><project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>org.example</groupId><artifactId>Test-CKafka</artifactId><version>1.0-SNAPSHOT</version><dependencies><dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId><version>0.10.2.2</version></dependency><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-simple</artifactId><version>1.7.25</version><scope>compile</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-java</artifactId><version>1.6.1</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-java_2.11</artifactId><version>1.6.1</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka_2.11</artifactId><version>1.7.0</version></dependency></dependencies><build><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><version>3.3</version><configuration><source>1.8</source><target>1.8</target></configuration></plugin></plugins></build></project>
步骤4:消费 CKafka 中的消息
您可以单击以下页面,查看消费消息的两种方式。通过控制台或打印的日志即可查看消费结果。
import org.apache.flink.api.common.serialization.SimpleStringSchema;import org.apache.flink.streaming.api.datastream.DataStream;import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;import java.util.Properties;public class CKafkaConsumerDemo {public static void main(String args[]) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();Properties properties = new Properties();//公网接入域名地址,即公网路由地址,在实例详情页的接入方式模块获取。properties.setProperty("bootstrap.servers", "IP:PORT");//消费者组id。properties.setProperty("group.id", "testConsumerGroup");DataStream<String> stream = env.addSource(new FlinkKafkaConsumer<>("topicName", new SimpleStringSchema(), properties));stream.print();env.execute();}}
import org.apache.flink.api.common.serialization.SimpleStringSchema;import org.apache.flink.streaming.api.datastream.DataStream;import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;import java.util.Properties;public class CKafkaConsumerDemo {public static void main(String args[]) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();Properties properties = new Properties();//公网接入域名地址,即公网路由地址,在实例详情页的接入方式模块获取。properties.setProperty("bootstrap.servers", "IP:PORT");//消费者组id。properties.setProperty("group.id", "testConsumerGroup");properties.setProperty("security.protocol", "SASL_PLAINTEXT");properties.setProperty("sasl.mechanism", "PLAIN");//用户名和密码,注:用户名是需要拼接,并非控制台的用户名:instanceId#username。properties.setProperty("sasl.jaas.config","org.apache.kafka.common.security.plain.PlainLoginModule required\\nusername=\\"yourinstanceId#yourusername\\"\\npassword=\\"yourpassword\\";");properties.setProperty("sasl.kerberos.service.name","kafka");DataStream<String> stream = env.addSource(new FlinkKafkaConsumer<>("topicName", new SimpleStringSchema(), properties));stream.print();env.execute();}}



