注意:
分布式数据仓库(TDW)任务已停止新增,即将下线,存量任务限制修改和变更。欢迎使用其他正在开放的任务类型。
操作场景
CKafka 连接器提供数据流出能力,您可以将 CKafka 数据分发至分布式数据仓库 TDW 以对数据进行存储、查询和分析。
前提条件
该功能目前依赖分布式数据仓库(TDW)产品,使用时需开通相关产品功能。
操作步骤
1. 登录 CKafka 控制台。
2. 在左侧导航栏单击连接器 > 任务列表,选择好地域后,单击新建任务。
3. 填写任务名称,任务类型选择数据流出,数据目标类型选择 数据仓库(TDW),单击下一步。
4. 配置数据源信息。
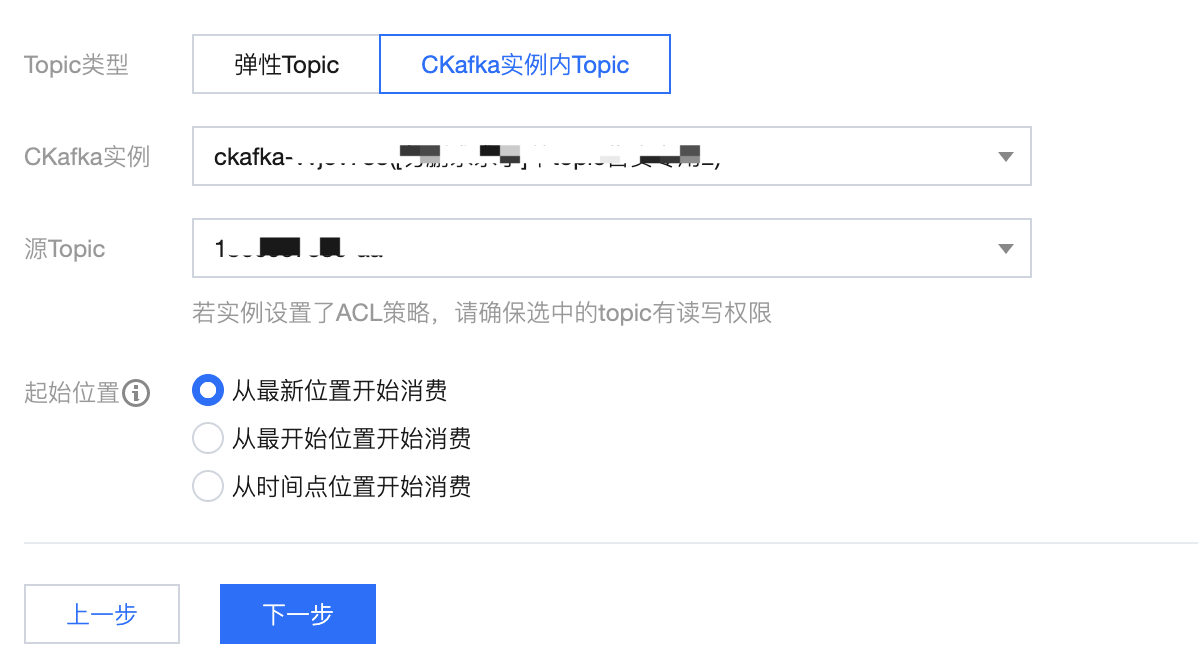
Topic 类型:选择数据源 Topic
弹性 Topic:选择提前创建好的弹性 Topic,详情参见 Topic 管理。
CKafka 实例内 Topic:选择在 CKafka 创建好的实例和 Topic,若实例设置了ACL 策略,请确保选中的 topic 有读写权限。详情参见 Topic 管理。
起始位置:选择转储时历史消息的处理方式,topic offset 设置。
5. 设置上述信息后,单击下一步,单击预览 Topic 消息,将会选取源 Topic 中的第一条消息进行解析。
说明
目前解析消息需要满足以下条件:
消息为 JSON 字符串结构。JSON的 Key 与 TDW 字段名相同即可与 TDW 的表结构相对应。
源数据必须为单层 JSON 格式,嵌套 JSON 格式可使用 数据处理 进行简单的消息格式转换。
6. (可选)开启对源数据进行数据处理按钮,具体配置方法请参见 简单数据处理。
7. 单击下一步,配置数据目标信息。
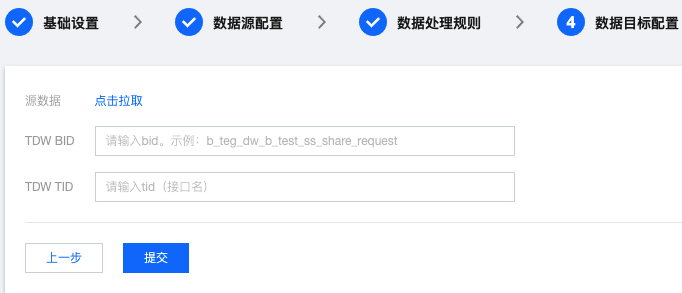
源数据:点击拉取源 Topic 数据。
TDW BID:填写 TDW 业务 BID。
TDW TID:填写 TDW 业务 TID。
8. 单击提交,可以在任务列表看到刚刚创建的任务,在状态栏可以查看任务创建进度。



