The content of this page has been automatically translated by AI. If you encounter any problems while reading, you can view the corresponding content in Chinese.
Lexiang leverages Tencent Cloud ES's one-stop text retrieval and vector retrieval hybrid search capabilities to create an intelligent Q&A module for enterprise-level knowledge management. Through precise information retrieval, strict permission management, and comprehensive knowledge management, it helps internal employees and external partners efficiently mine the knowledge treasures of enterprises and organizations.
This article introduces the practice of Lexiang's one-stop RAG solution based on Tencent Cloud ES to realize the Lexiang intelligent Q&A feature.
Lexiang's Business Background and Challenges
Lexiang is an intelligent organizational learning collaboration platform that integrates knowledge management, corporate training, and cultural construction. It features knowledge bases, Q&A, classrooms, examinations, and more, aiming to help enterprises establish efficient and flexible knowledge sharing and mobility mechanisms to enhance organizational capability.
With the development of large-scale model technology, Lexiang sees unprecedented opportunities to improve the efficiency and accuracy of information acquisition, driving innovation in business models and service modes.
However, Lexiang also faces new challenges, especially in solving the "illusion" problem with large models, ensuring personalized responses while guaranteeing data security and privacy protection. Corporate "private knowledge" cannot be directly used for the pre-training and fine-tuning of large models, which poses higher demands on knowledge management.
How to use the "new bottle" of large models to encapsulate the "old wine" of enterprise knowledge management, maximizing customer value with one hand and commercializing product experience with the other, has become a problem that the Lexiang team must solve.
What is RAG?
With the development of search engine technology, traditional keyword searches can no longer meet user needs. RAG (Retrieval-Augmented Generation) combines vector retrieval and text generation; it searches for relevant documents through a retrieval model and uses them as contextual information for the generation model to produce accurate answers. This method combines external knowledge with the generation model, enhancing the smoothness and accuracy of the content, and is widely used in scenarios such as knowledge Q&A, text summary, and dialogue generation.
Tencent Cloud ES One-Stop RAG Solution
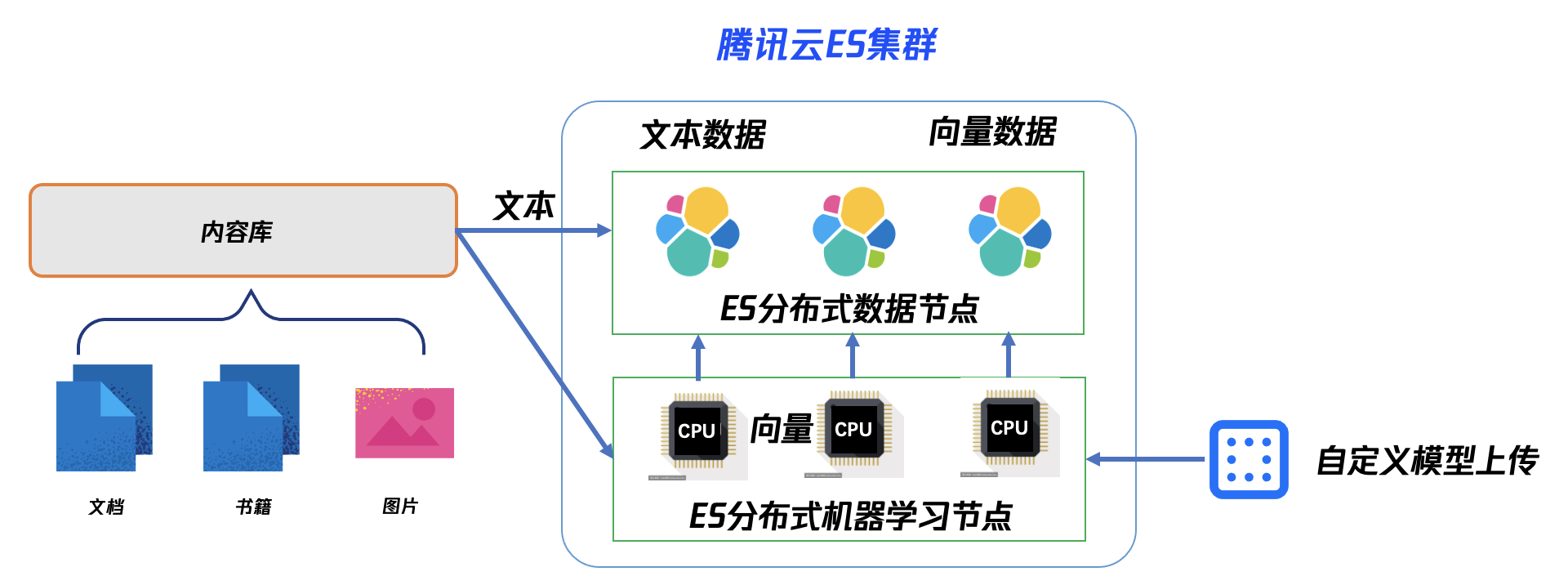
One-stop vector retrieval capability
Based on the capabilities provided by Tencent Cloud ES, we can directly complete the full process operations of Vector Generation > Vector Indexing/Storage > Vector Retrieval. The specific capabilities are as follows:
Built-in, ready-to-use ELSER semantic model.
Support for uploading self-defined models or directly uploading models from open-source communities like Hugging Face.
Support for proprietary machine learning nodes used for vector reasoning (optional, can also be mixed with data nodes).
Support for vector indexing (HNSW Algorithm), vector storage, and KNN retrieval.
Search for the required CAM policy as needed, and click to complete policy association.
Unique Hybrid Search Capability
Despite the ability of vector search to perform semantic queries, it may return irrelevant results when dealing with specific strings like "8XLARGE64". By combining the advantages of vector and text search, hybrid search improves the recall rate through simultaneous execution of text and vector searches and merging the results. Tencent Cloud ES supports one-stop hybrid search, allowing text and vector searches to be performed simultaneously in a single query and automatically sorting and merging the results.
Search for the required CAM policy as needed, and click to complete policy association.
Reciprocal Sorting Fusion (RRF)
In multi-channel recall, different system scoring mechanisms require normalized scores for fair comparison and fusion. Tencent Cloud ES's built-in Reciprocal Sorting Fusion (RRF) algorithm assigns weights to rankings and calculates the sum of the reciprocals of each system's rankings to generate the final merged ranking list. The advantages of RRF include:
Simplicity:No need for complex normalization, just know the rank of each document in each system.
Robustness:Less sensitive to different scoring scales and distributions.
Fairness:Ensures fairness in the merging process by assigning weights using the same formula.
Easy to Implement:Relatively simple to implement, no complex parameter tuning or training required.
Adaptability:Can adapt to new systems or data, not reliant on specific scoring mechanisms.
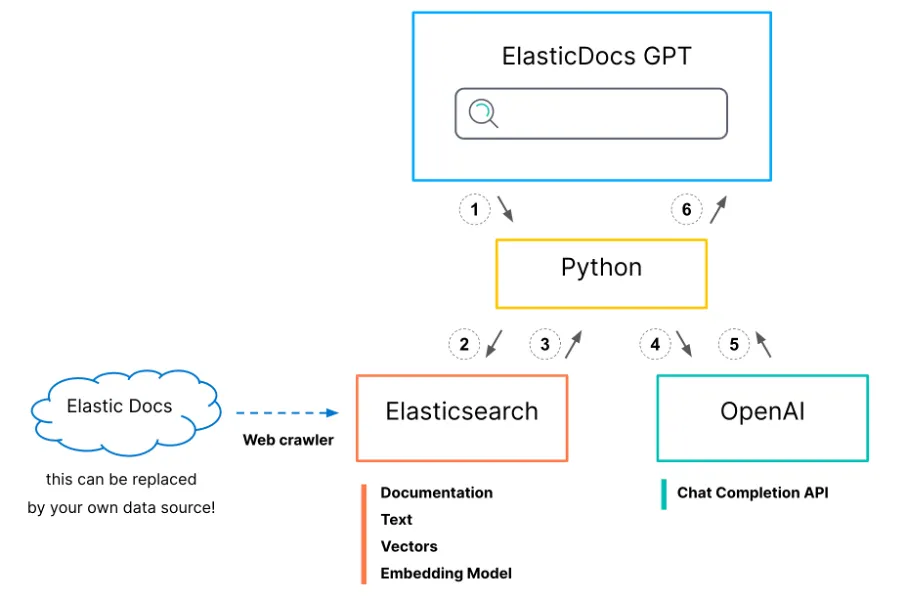
Integration with LLM Large Model
Tencent Cloud ES can seamlessly integrate with third-party pipelines such as Langchain and LLM Large Models to help build generative applications.
Search for the required CAM policy as needed, and click to complete policy association.
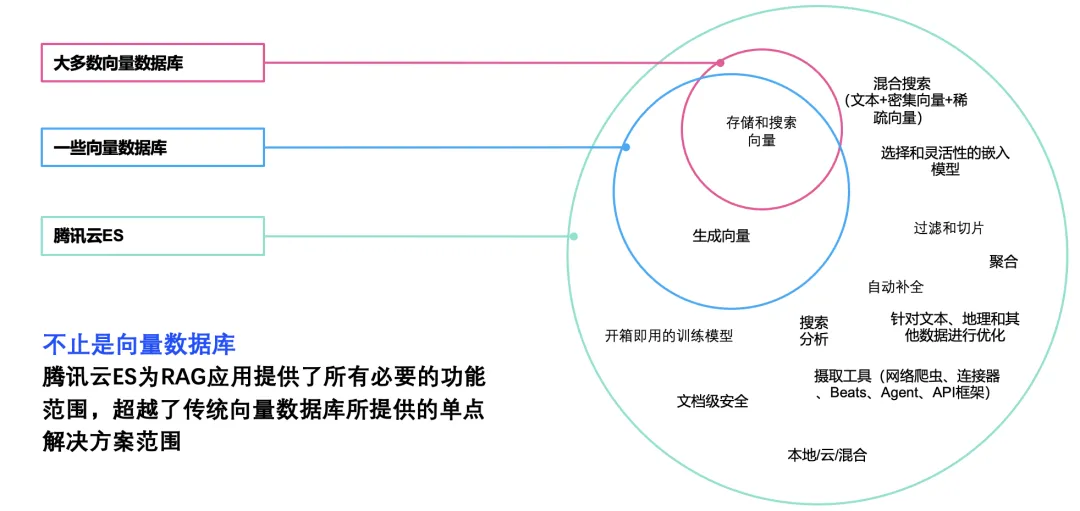
Advantages of Tencent Cloud ES RAG Scheme
Tencent Cloud ES offers a one-stop RAG solution, providing all features within the RAG application scope, surpassing the single-point solutions provided by traditional Tencent Cloud VectorDB. The details are as follows:
Supports direct upload from Definition embedding models or embedding models from hugging face, completing model management, deployment, and data vectorization within ES.
Supports hybrid search capabilities of text + vector to flexibly meet various needs.
Supports scoring and ranking by setting the weight of text, vector, and even field-level term weight. You can also directly use the built-in RRF capability to achieve ranking fusion. Later, the LTR model can be introduced to re-rank coarse-ranked results, meeting the needs of different business scenarios.
In some permission-sensitive scenarios, ES supports role-based document and field-level permission control for precise access management.
Search for the required CAM policy as needed, and click to complete policy association.
Moreover, RAG applications typically serve online business scenarios, and stability is crucial. Tencent Cloud ES supports multiple replicas setting, multiple availability zones deployment, CCR cross-cluster replication, automatic data backup, and AS capabilities to ensure the stability of online businesses. Additionally, intelligent patrol, multi-dimensional stereoscopic monitoring and alerting, and audit log capabilities help enterprises reduce operation and management costs, achieving cost reduction and efficiency improvement.
Tencent Cloud ES high-accuracy high-performance self-developed kernel
Tencent Cloud ES not only provides a more comprehensive RAG solution compared to the traditional Tencent Cloud VectorDB but also has unique advantages in performance. The Tencent Cloud ES RAG solution significantly enhances the efficiency and precision of vector retrieval, leveraging the powerful performance of the Zixiao GPU and the deeply optimized self-developed kernel.
Self-developed kernel optimization
At the kernel level, Tencent Cloud ES has deeply optimized typical vector scenarios, such as sharded architecture optimization, query parallelization, Lucene query cache lock transformation, etc. The average response latency for 1 billion-scale vector retrieval is controlled at the millisecond level, and the overall query performance is improved by 3 to 10 times:
Hybrid Search: Real-time joint retrieval and multi-channel recall based on vector retrieval and BM25 algorithm, with result fusion significantly improving the recall rate while maintaining high performance.
Scalar Quantization of Vectors: Converting float8 to int8 representation, significantly reducing CPU and heap memory resource consumption and search latency while ensuring that the recall rate is not affected.
Adaptive Replica Policy: ES distributed systems involve many network calls. Cross-region/AZ calls or slow node shard replica calls can lead to high query latency. Tencent Cloud ES adopts an improved local adaptive replica selection policy. The core principle is to calculate the average query response time, query queue, and query success rate between the Coordinator and data shard replicas, continuously adjusting to select the replica with the lowest latency for queries. This significantly reduces search latency and ensures CLB.
Query Pruning: The ES query model splits a query request into shard-level sub-requests forwarded to each shard for parallel execution, finally merging results at the Coordinator. Each shard contains multiple segments. Tencent Cloud ES pre-prunes and merges segments based on dimensions such as columnar storage, numerical indexes, and terms, reducing random IO and optimizing query performance.
Query Parallelization: By leveraging idle CPU resources, a single shard-level request in ES is split into 3-5 sub-requests for parallel processing across segments or docs. Each thread processes a portion of the docs or segments. The results from each thread are merged at the data node and returned to the Coordinator, which then merges the results from all shards and returns them to the client, achieving a multiplicative performance boost.
Query Cache Optimization: Using the CBO strategy, query cache operations that could cause latency spikes of 10x are avoided. The LRU cache performance is more than doubled through fine-grained read-write locks. These improvements have been submitted to and recognized by the Elasticsearch and Lucene communities.
Zixiao GPU Support
Tencent Cloud ES is the world's only ES service that supports GPUs. It can leverage Tencent's self-developed "core" technology, Zixiao, which combines hardware and software to fully utilize the performance benefits of GPUs and improve the efficiency of vector generation and retrieval. Zixiao V1 features high energy efficiency, high throughput, and high bandwidth. Its design specifications are comparable to the NVIDIA A10, with memory bandwidth 30% higher than the A10, and overall performance up to 50% - 100% better. For common small to medium models, Zixiao typically offers over 100% performance improvement compared to the NVIDIA T4, and a performance edge of over 20% compared to the NVIDIA A10.
Performance Comparison of Tencent Cloud ES and Milvus
We conducted detailed performance tests using the open-source tool ann-benchmark. By retrieving various dimensional datasets and achieving a recall rate of 99%, we obtained the Top 10 most similar documents. We then compared the QPS data of vector retrieval between Milvus and Tencent Cloud ES.
Public Datasets
Dimension
Configuration
Recall Rate
QPS
Milvus
Tencent Cloud ES
sift-128-euclidean
128
3 nodes, 4C8G,
HNSW(m=16,
efConstruction=200)
99%
3653
19479
gist-960-euclidean
960
480
4136
It can be seen that whether in high-dimensional or low-dimensional vector retrieval scenarios, Tencent Cloud ES has a performance advantage of nearly 5-8 times, helping business development with lower costs and better performance, achieving cost reduction and efficiency improvement.
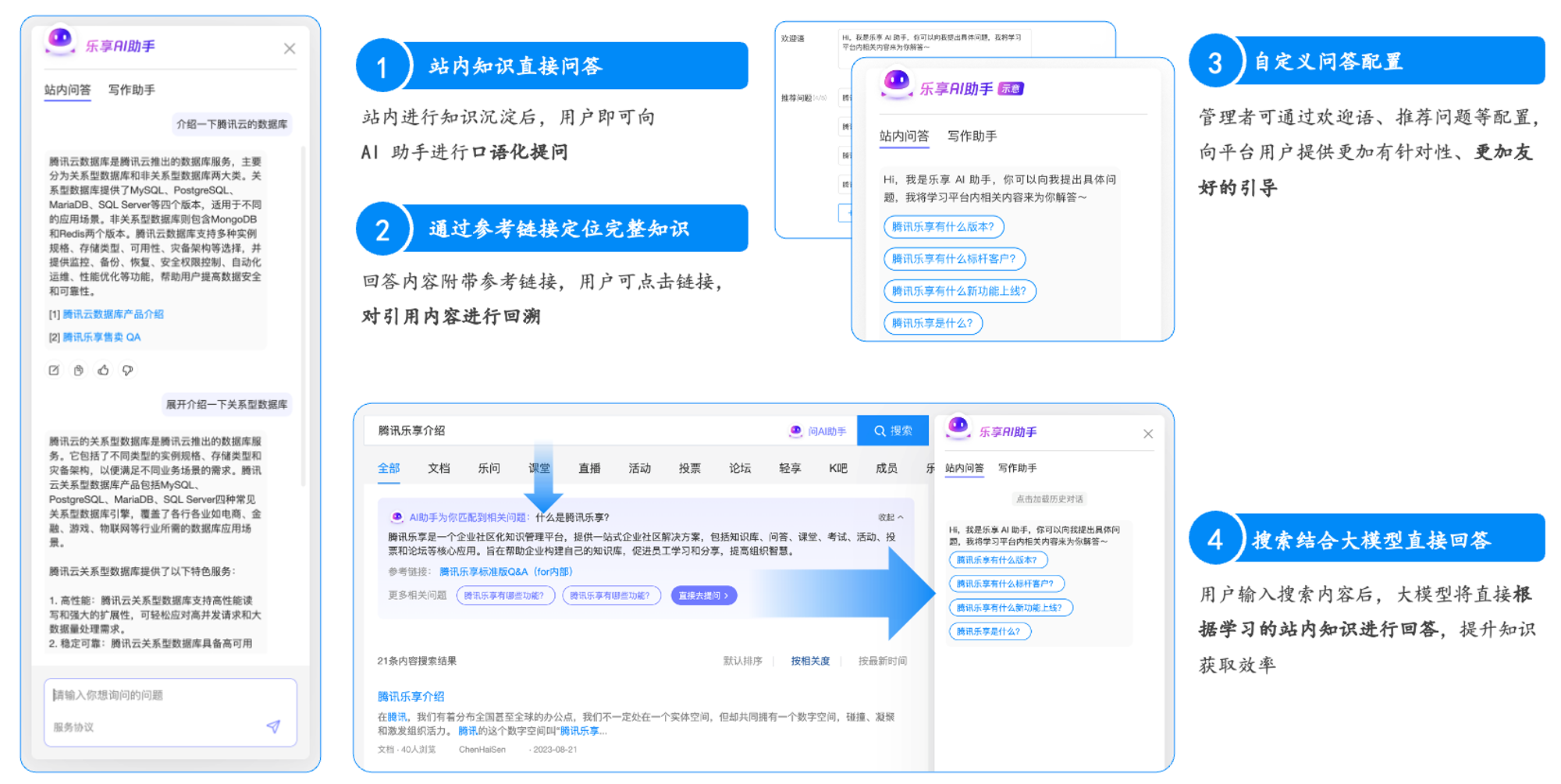
Lexiang's RAG Practice Based on Tencent Cloud ES
The core goal of the LeXiang intelligent search module is to help internal employees and external partners efficiently mine the knowledge deposits within the enterprise. Although the interaction with intelligent search is not complex, achieving good search results is not as easy. The first issue to address is the "illusion" problem of large models, to be precise, reducing the "illusion" to the minimum. For enterprise customers, honestly saying "I don't know" has a much smaller impact than a clearly incorrect answer. Furthermore, the "private knowledge" of these enterprises obviously cannot be directly used in large model pre-training (Pre Trained) and fine-tuning (Fine Tuning). For such problems, LeXiang adopts the RAG (Retrieval Augmented Generation) approach.
Search for the required CAM policy as needed, and click to complete policy association.
In the process of implementing RAG, Lexiang used the hybrid search of vector retrieval and precise text matching provided by Tencent Cloud ES, combined with its built-in Reciprocal Sorting Fusion (RRF) algorithm, to achieve multi-path recall, hybrid search, and hybrid sorting, ultimately achieving high recall rate and high accuracy rate in data retrieval.
Practice Results
By implementing Tencent Cloud ES's RAG solution, Lexiang's intelligent search module achieved the following results:
High Recall Rate and Accuracy: By using hybrid search technology, Lexiang effectively enhanced the recall rate and accuracy of vector retrieval, ensuring more relevant and precise user query results.
Improved User Satisfaction: The intelligent search module reduced the "hallucination" phenomenon of large models, increasing the accuracy and reliability of answers, significantly boosting user satisfaction.
Enhanced Business Efficiency: Internal employees and external partners can quickly access the needed knowledge, improving work efficiency and collaboration.
Data Security: Through strict permission management, Lexiang ensured the security and privacy protection of enterprise data, enhancing user trust in the system.
Summary
Tencent Cloud ES's one-stop RAG solution performed excellently in the field of intelligent retrieval, helping enterprises reduce costs and improve efficiency, achieving continuous growth in business value.
Through cutting-edge large model technology, Lexiang transformed years of accumulated enterprise data into valuable knowledge, aiding enterprises in building an intelligent learning community.
In the future, Tencent Cloud ES will continue to delve deeper into the field of intelligent retrieval, consistently improving in cost, performance, and stability, helping customers achieve greater business value. Thank you all for your support, and we welcome you to continue following Tencent Cloud ES and Lexiang!