Elasticsearch 主要用于海量数据的存储和检索,若将所有数据都放在 SSD 硬盘上,成本会非常高。可通过热温分离来解决这个问题,热温集群可以在一个集群内包含温、热两种属性的节点,从而兼顾性能和容量之间的矛盾。
对读写性能要求比较高的热数据(例如7天内的日志)可以在热节点上以 SSD 磁盘存储。
对存储量需求比较大但对读写性能要求较低的索引(例如1个月甚至更长时间的日志)可以在温节点上以 SATA 磁盘存储。
腾讯云 ES 提供了快速配置构建热温集群的能力,用户可以在腾讯云官网根据业务需要指定温热节点规格,快速建立一个温热分离架构的 ES 集群。
创建热温集群
在购买集群时直接创建
1. 进入腾讯云 Elasticsearch Service 创建集群 页面,在页面填写所需创建集群的相关信息。
2. 数据节点部署方式选择温数据节点,并选择温数据节点规格,如下图:
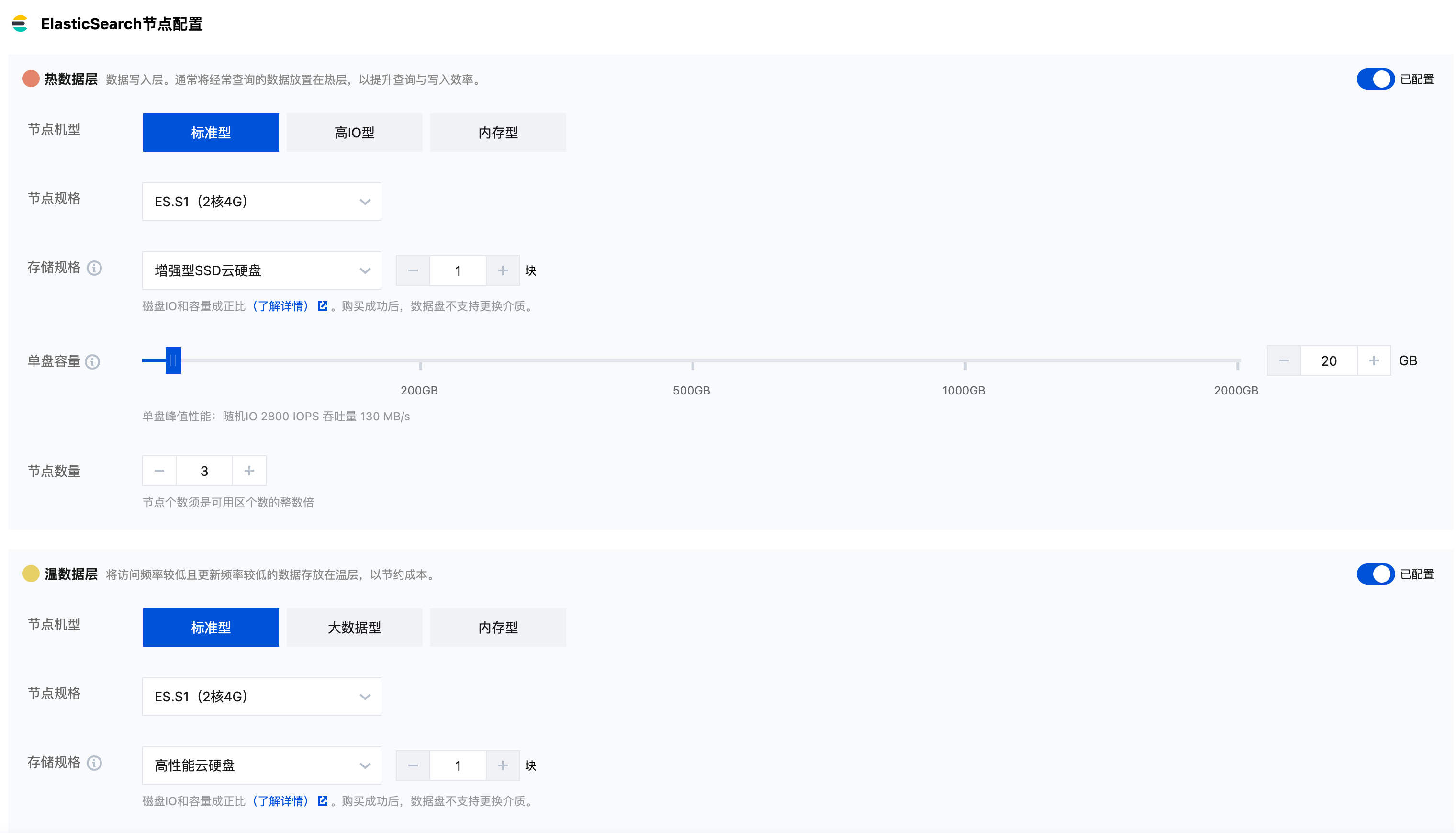
3. 进一步设置集群的其他参数,确认并支付即可。
将现有集群变配为热温集群
在集群详情页面,选择右上角更多操作 > 调整配置,在调整配置页面,选择数据节点部署模式为温热模式,根据需要设置温热节点的规格和相关配置,将现有集群变配为热温集群。
使用热温集群
节点角色查看
验证节点温热属性,命令如下:
GET _cat/nodeattrs?v&h=node,attr,value&s=attr:descnode attr valuenode1 temperature hotnode2 temperature hotnode3 temperature warmnode4 temperature hotnode5 temperature warm...
7.14.2 版本中查看节点属性使用如下命令:
GET _nodes?filter_path=nodes.*.name,nodes.*.roles&pretty
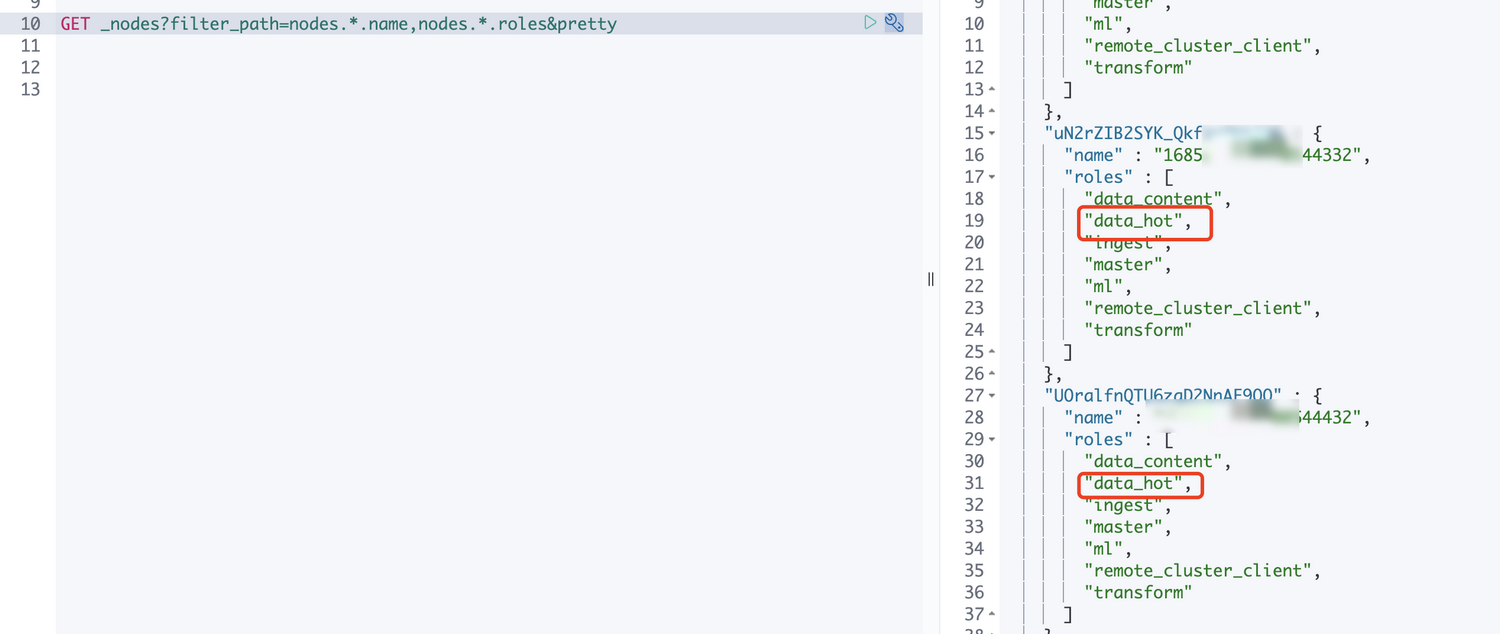
指定索引温热属性
业务方可以根据实际情况决定索引的温热属性。
1. 创建索引。
PUT hot_warm_test_index{"settings": {"number_of_replicas": 1,"number_of_shards": 3}}
2. 查看分片分配,可以看到分片均匀分配在五个节点上。
GET _cat/shards/hot_warm_test_index?v&h=index,shard,prirep,node&s=nodeindex shard prirep nodehot_data_index 1 p node1hot_data_index 0 r node1hot_data_index 2 r node2hot_data_index 2 p node3hot_data_index 1 r node4hot_data_index 0 p node5
3. 设置索引。
设置索引为热索引。
PUT hot_warm_test_index/_settings{"index.routing.allocation.require.temperature": "hot"}//7.14.2版本中更改索引为热属性命令如下:PUT hot_warm_test_index/_settings{"index.routing.allocation.include._tier_preference": "data_hot"}
查看分片分配,分片均分配在热节点上。
GET _cat/shards/hot_warm_test_index?v&h=index,shard,prirep,node&s=nodeindex shard prirep nodehot_data_index 1 p node1hot_data_index 0 r node1hot_data_index 0 p node2hot_data_index 2 r node2hot_data_index 2 p node4hot_data_index 1 r node4
设置索引为温索引。
PUT hot_warm_test_index/_settings{"index.routing.allocation.require.temperature": "warm"}//7.14.2版本中更改索引为温属性命令如下:PUT hot_warm_test_index/_settings{"index.routing.allocation.include._tier_preference": "data_warm"}
查看分片分配,分片均分配到温节点上。
GET _cat/shards/hot_warm_test_index?v&h=index,shard,prirep,node&s=nodeindex shard prirep nodehot_data_index 1 p node3hot_data_index 0 r node3hot_data_index 2 r node3hot_data_index 0 p node5hot_data_index 2 p node5hot_data_index 1 r node5
索引生命周期管理
腾讯云目前已提供 6.8.2 版本的集群,该版本 Elasticsearch(>=6.6) 提供了索引生命周期管理功能。索引生命周期管理可以通过 API 或者 kibana 界面配置,详情请参见 index-lifecycle-management。下文将通过 kibana 界面来演示,如何使用索引生命周期管理,结合温热分离架构,实现索引数据的动态管理。
kibana 中的索引生命周期管理位置如下图(版本 7.14.2):
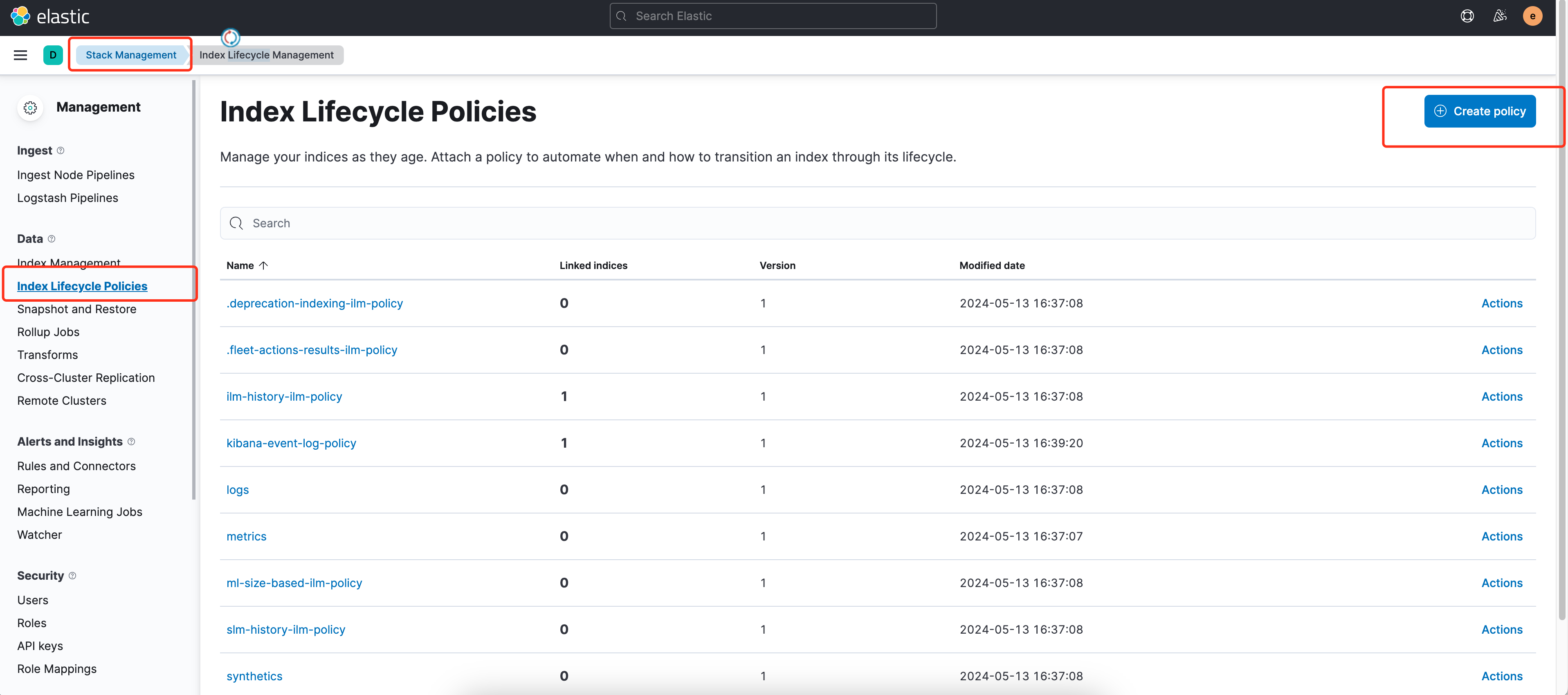
Hot phase、Warm phase、Cold phase三个阶段。Hot phase:此阶段可以根据索引的文档数、大小、时长决定是否调用 rollover API 来滚动索引,详情请参见 indices-rollover-index。因与本文关系不大,这里不再赘述。
Warm phase:当一个索引在
Hot phase被 rollover 后便会进入Warm phase ,进入该阶段的索引会被设置为 read-only。用户可为此索引设置要使用的 attribute,例如对于温热分离策略,这里可选择temperature: warm属性。另外还可以对索引进行 forceMerge、shrink 等操作,这两个操作具体请参见 shrink API 和 force merge 官方文档。
Cold phase:可以设置当索引 rollover 一段时间后进入 cold 阶段,这个阶段也可以设置一个属性。从温热分离架构可以看出温热属性是具备扩展性的,不仅可以指定 hot、warm,也可以扩展增加 hot、warm、cold、freeze 等多个温热属性。如果想使用三层的温热分离,可指定为
temperature: cold。同时还支持对索引的 freeze 操作,详情请参见 freeze API 官方文档。 


