说明
此接口为实时语音合成接口,在参数风格、错误码等方面有区别于云 API 接口,请知悉。
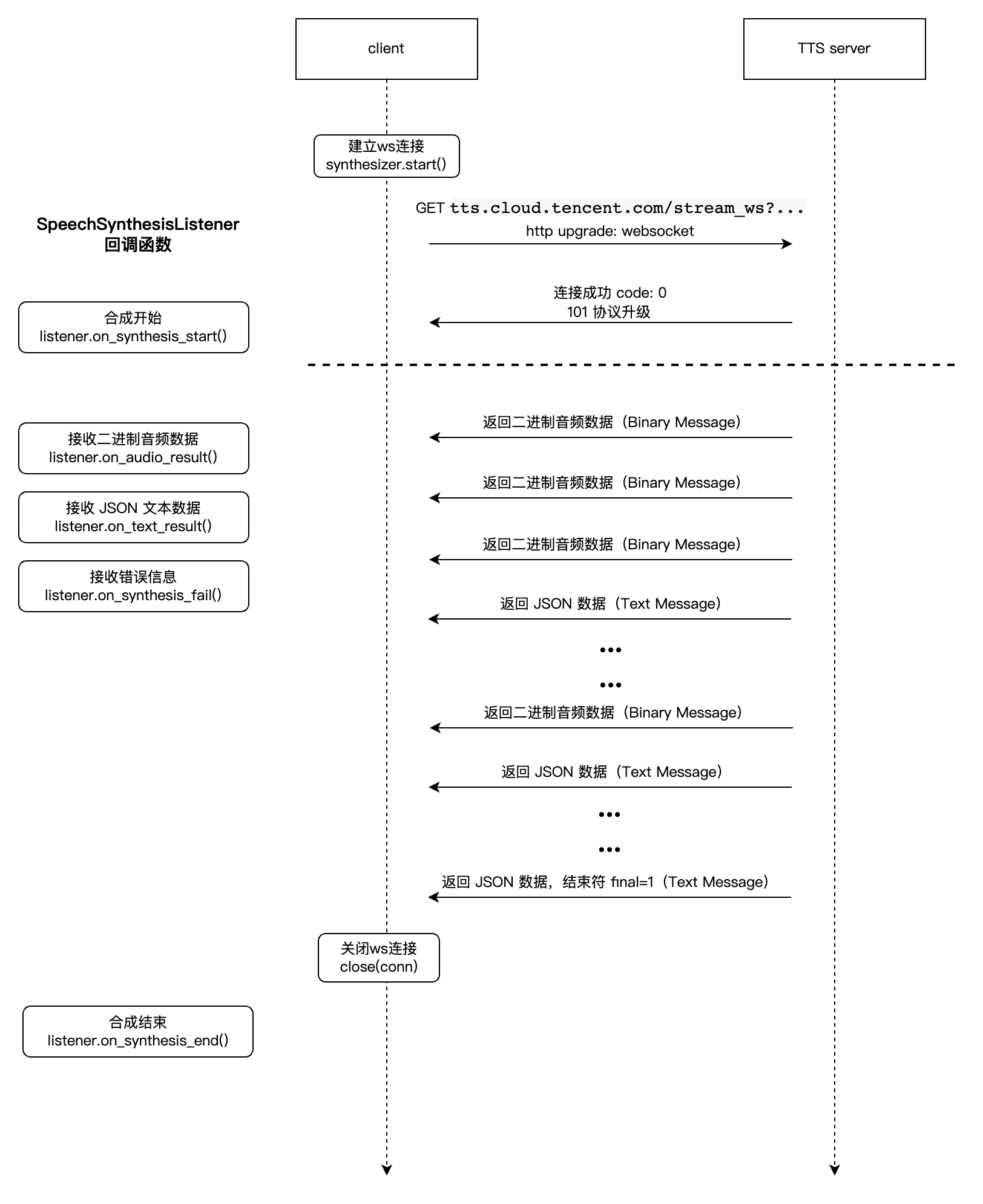
本接口服务采用 WebSocket 协议,将请求文本合成为音频,同步返回合成音频数据及相关文本信息,达到“边合成边播放”的效果。
接口要求
集成实时语音合成 API 时,需按照以下要求。
内容 | 说明 |
音色种类 | |
支持场景 | |
音频属性 | 采样率:16000Hz 或 8000Hz 采样精度:16bits 声道:单声道(mono) |
音频格式 | pcm、mp3 |
请求协议 | wss 协议 |
请求地址 | wss://tts.cloud.tencent.com/stream_ws?{请求参数} |
接口鉴权 | |
响应格式 | 音频信息通过 binary 类型帧,返回原始二进制数据。 文本信息通过 text 类型帧,返回 JSON 格式数据(如状态码、时间戳等)。 |
并发限制 | 默认单账号限制并发 精品音色:20路 大模型音色:20路 超自然大模型音色:10路 一句话复刻音色:10路 |
接口调用流程
接口调用流程分为两个阶段:握手阶段和合成阶段。两阶段后台均会返回 text message,内容为 JSON 序列化字符串,以下是格式说明:
字段名 | 类型 | 描述 |
code | Integer | 状态码,0代表正常,非0值表示发生错误。 |
message | String | 错误说明,发生错误时显示这个错误发生的具体原因,随着业务发展或体验优化,此文本可能会经常保持变更或更新。 |
session_id | String | 音频流唯一 ID,由客户端在握手阶段生成并赋值在调用参数中。 |
request_id | String | 音频流唯一 ID,由服务端在握手阶段自动生成。 |
message_id | String | 本 message 唯一 ID。 |
result | Result | 最新语音合成文本结果。 |
final | Integer | 该字段返回1时表示文本全部合成结束,客户端收到后需主动关闭 WebSocket 连接。 |
其中合成结果 Result 结构体格式为:
字段名 | 类型 | 描述 |
subtitles | Subtitle Array | 当前一段话的词列表,Subtitle 结构体格式为: Text:String 类型,该字的内容。 BeginTime::Integer 类型,该字在整个音频流中的起始时间。 EndTime:Integer 类型,该字在整个音频流中的结束时间。 BeginIndex:Integer 类型,该字在整个文本中的开始位置,从0开始。 EndIndex:Integer 类型,该字在整个文本中的结束位置,从0开始。 Phoneme:String 类型,该字的音素。(注意:此字段可能返回 null,表示取不到有效值)。 |
握手阶段
请求格式
握手阶段,客户端主动发起 WebSocket 连接请求,请求 URL 格式为:
wss://tts.cloud.tencent.com/stream_ws?{请求参数}
key1=value2&key2=value2...(key 和 value 都需要进行 urlencode)
参数说明:
参数名称 | 必填 | 类型 | 描述 |
Action | 是 | String | 调用接口名,取值为:TextToStreamAudioWS。 |
AppId | 是 | Integer | 账号 AppId(请确保该字段数据类型为整型 int)。 |
SecretId | 是 | String | |
Timestamp | 是 | Integer | 当前 UNIX 时间戳,可记录发起 API 请求的时间。例如1529223702,如果与当前时间相差过大,会引起签名过期错误。 |
Expired | 是 | Integer | 签名的有效期,是一个符合 UNIX Epoch 时间戳规范的数值,单位为秒;Expired 必须大于 Timestamp 且 Expired-Timestamp 小于90天。 |
SessionId | 是 | String | 语音合成全局唯一标识,一个 WebSocket 连接对应一个,用户自己生成(推荐使用 UUID),最长128位。 |
Text | 是 | String | 合成语音的源文本,按 UTF-8 编码统一计算。中文最大支持600个汉字(全角标点符号算一个汉字);英文最大支持1800个字母(半角标点符号算一个字母)。 |
VoiceType | 否 | Integer | 注意: 若使用一句话版声音复刻,请填入固定值“200000000”。 |
FastVoiceType | 否 | String | 一句话版声音复刻音色 ID,使用一句话版声音复刻音色时需填写。 |
Volume | 否 | Float | 音量大小,范围[-10,10],对应音量大小。默认为0,代表正常音量,值越大音量越高。 |
Speed | 否 | Float | 语速,范围:[-2,6],分别对应不同语速: -2:代表0.6倍 -1:代表0.8倍 0:代表1.0倍(默认) 1:代表1.2倍 2:代表1.5倍 6:代表2.5倍 如果需要更细化的语速,可以保留小数点后 2 位,例如0.5/1.25/2.81等。 |
SampleRate | 否 | Integer | 音频采样率: 24000:24k(部分音色支持,请参见 音色列表) 16000:16k(默认) 8000:8k |
Codec | 是 | String | 返回音频格式: pcm:返回二进制 pcm 音频 mp3:返回二进制 mp3 音频 |
EnableSubtitle | 否 | Boolean | 是否开启时间戳功能,默认为 false。超自然音色暂不支持时间戳。 |
EmotionCategory | 否 | String | 控制合成音频的情感,仅支持多情感音色使用。 取值:neutral(中性)、sad(悲伤)、happy(高兴)、angry(生气)、fear(恐惧)、news(新闻)、story(故事)、radio(广播)、poetry(诗歌)、call(客服)、sajiao(撒娇)、disgusted(厌恶)、amaze(震惊)、peaceful(平静)、exciting(兴奋)、aojiao(傲娇)、jieshuo(解说) 示例值:neutral |
EmotionIntensity | 否 | Integer | 控制合成音频情感程度,取值范围为 [50,200],默认为 100;只有 EmotionCategory 不为空时生效。 |
SegmentRate | 否 | Integer | 断句敏感阈值,取值范围:[0,1,2],默认值:0 该值越大越不容易断句,模型会更倾向于仅按照标点符号断句。此参数建议不要随意调整,可能会影响合成效果。 |
Signature | 是 | String | 接口签名参数 |
Signature 签名生成
1. 对除 Signature 之外的所有参数按字典序进行排序,拼接后得到请求参数为:
Action=TextToStreamAudioWS&AppId=130046****&Codec=pcm&EnableSubtitle=True&Expired=1688697305&SampleRate=16000&SecretId=*****XcaKs2w4vZw5zTCrHRM7dOwre9*****&SessionId=b78ae3ba-1ba5-11ee-a106-768645a5c72a&Speed=0&Text=欢迎使用腾讯云实时语音合成&Timestamp=1688610905&VoiceType=101001&Volume=0
再拼接请求方法、域名地址,得到签名原文。签名原文格式为:
请求方法(GET) + 域名地址(tts.cloud.tencent.com/stream_ws) + 请求参数(?Action=TextToStreamAudioWS&其他参数...)
最终,得到的签名原文为:
GETtts.cloud.tencent.com/stream_ws?Action=TextToStreamAudioWS&AppId=130046****&Codec=pcm&EnableSubtitle=True&Expired=1688697305&SampleRate=16000&SecretId=*****XcaKs2w4vZw5zTCrHRM7dOwre9*****&SessionId=b78ae3ba-1ba5-11ee-a106-768645a5c72a&Speed=0&Text=欢迎使用腾讯云实时语音合成&Timestamp=1688610905&VoiceType=101001&Volume=0
2. 对签名原文使用 SecretKey 进行 HMAC-SHA1 加密,之后再进行 base64 编码。例如对上一步的签名原文,
SecretKey=*****SkqpeHgqmSz*****,使用 HMAC-SHA1 算法进行加密并做 base64 编码处理:Base64Encode(HmacSha1("GETtts.cloud.tencent.com/stream_ws?Action=TextToStreamAudioWS&AppId=130046****&Codec=pcm&EnableSubtitle=True&Expired=1688697305&SampleRate=16000&SecretId=*****XcaKs2w4vZw5zTCrHRM7dOwre9*****&SessionId=b78ae3ba-1ba5-11ee-a106-768645a5c72a&Speed=0&Text=欢迎使用腾讯云实时语音合成&Timestamp=1688610905&VoiceType=101001&Volume=0", "*****SkqpeHgqmSz*****"))
得到 Signature 签名值为:
U6O4dLlz3mgj6ONKUkO/0g4u5pk=
3. 将 Signature 值进行 urlencode(必须进行 URL 编码,编码函数必须要支持对+、=等特殊字符的编码,否则将导致鉴权失败偶现)后拼接得到 URL 为:
wss://tts.cloud.tencent.com/stream_ws?Action=TextToStreamAudioWS&AppId=130046****&Codec=pcm&EnableSubtitle=True&Expired=1688697305&SampleRate=16000&SecretId=*****XcaKs2w4vZw5zTCrHRM7dOwre9*****&SessionId=b78ae3ba-1ba5-11ee-a106-768645a5c72a&Speed=0&Text=欢迎使用腾讯云实时语音合成&Timestamp=1688610905&VoiceType=101001&Volume=0&Signature=4Lv%2Bk6y6v5VRT/iBFPU%2BGyfeiy0%3D
4. 将 Text 值进行 urlencode 编码,替换原始文本值:
Text=欢迎使用腾讯云实时语音合成替换为Text=%E6%AC%A2%E8%BF%8E%E4%BD%BF%E7%94%A8%E8%85%BE%E8%AE%AF%E4%BA%91%E5%AE%9E%E6%97%B6%E8%AF%AD%E9%9F%B3%E5%90%88%E6%88%90
得到最终的请求 URL 为:
wss://tts.cloud.tencent.com/stream_ws?Action=TextToStreamAudioWS&AppId=130046****&Codec=pcm&EnableSubtitle=True&Expired=1688697305&SampleRate=16000&SecretId=*****XcaKs2w4vZw5zTCrHRM7dOwre9*****&SessionId=b78ae3ba-1ba5-11ee-a106-768645a5c72a&Speed=0&Text=%E6%AC%A2%E8%BF%8E%E4%BD%BF%E7%94%A8%E8%85%BE%E8%AE%AF%E4%BA%91%E5%AE%9E%E6%97%B6%E8%AF%AD%E9%9F%B3%E5%90%88%E6%88%90&Timestamp=1688610905&VoiceType=101001&Volume=0&Signature=4Lv%2Bk6y6v5VRT/iBFPU%2BGyfeiy0%3D
请求响应
客户端发起连接请求后,后台建立连接并进行签名校验,校验成功则返回 code 值为 0 的确认消息表示握手成功;如果校验失败,后台返回 code 为非0值的消息并断开连接。
{"code":0,"message":"success","session_id":"e042008c-1019-11ee-8b49-6c92bf65e6fe","request_id":"b028dfe6-d7af-4d25-b61d-dcae685aa81f","message_id":"f81c0771-5606-478e-9560-555a5717ea25","final":0,"result":{"subtitles":null}}
合成阶段
握手成功之后,进入合成阶段,客户端接收合成的音频二进制数据、文本数据(如时间戳)。
接收消息
客户端需要同步接收后台返回的二进制音频数据与文本数据。文本数据示例如下:
{"code":0,"message":"success","session_id":"659f1260-101a-11ee-959d-6c92bf65e6fe","request_id":"20ebf801-53ee-4a58-96ab-c63e0f16044a","message_id":"8d4a2f2b-3b15-445c-933b-74b6b44cd882","final":0,"result":{"subtitles":[{"Text":"欢","BeginTime":250,"EndTime":570,"BeginIndex":0,"EndIndex":1,"Phoneme":"huan1"},{"Text":"迎","BeginTime":570,"EndTime":770,"BeginIndex":1,"EndIndex":2,"Phoneme":"ying2"},{"Text":"使","BeginTime":770,"EndTime":1020,"BeginIndex":2,"EndIndex":3,"Phoneme":"shi3"},{"Text":"用","BeginTime":1020,"EndTime":1270,"BeginIndex":3,"EndIndex":4,"Phoneme":"yong4"}]}}
后台合成完所有音频数据之后,最终返回 final 值为1的消息,客户端收到后,需主动断开 WebSocket 连接。
{"code":0,"message":"success","session_id":"dbb8417e-101a-11ee-840e-6c92bf65e6fe","request_id":"99207183-3bda-42de-a1f4-6d8838122ad3","message_id":"d56a3fed-0dd6-4dc6-b434-416ae1b69f0f","final":1,"result":{"subtitles":null}}
合成过程中如果出现错误,后台返回 code 为非0值的消息并断开连接。
{"code":10001,"message":"参数不合法(Please check your parameter VoiceType)","session_id":"b6b10dc0-101a-11ee-9e72-6c92bf65e6fe","request_id":"a2edbe4f-c12f-48e6-8810-fda7a0992f79","message_id":"da63be2f-d44e-4f3b-a2d7-0b19a3748d23","final":0,"result":{"subtitles":null}}
调用流程示意图
开发者资源
SDK
SDK 调用示例
Java 示例
C++ 示例
Go 示例
错误码
数值 | 说明 |
10001 | 参数不合法,具体详情参考 message 字段 |
10002 | 账号当前调用并发超限 |
10003 | 鉴权失败 |
10004 | 客户端数据上传超时 |
10005 | 客户端连接断开 |
20000 | 后台错误 |
20001 | 后台服务器合成失败 |
20002 | 后台引擎合成失败 |
20003 | 后台引擎合成超时 |



