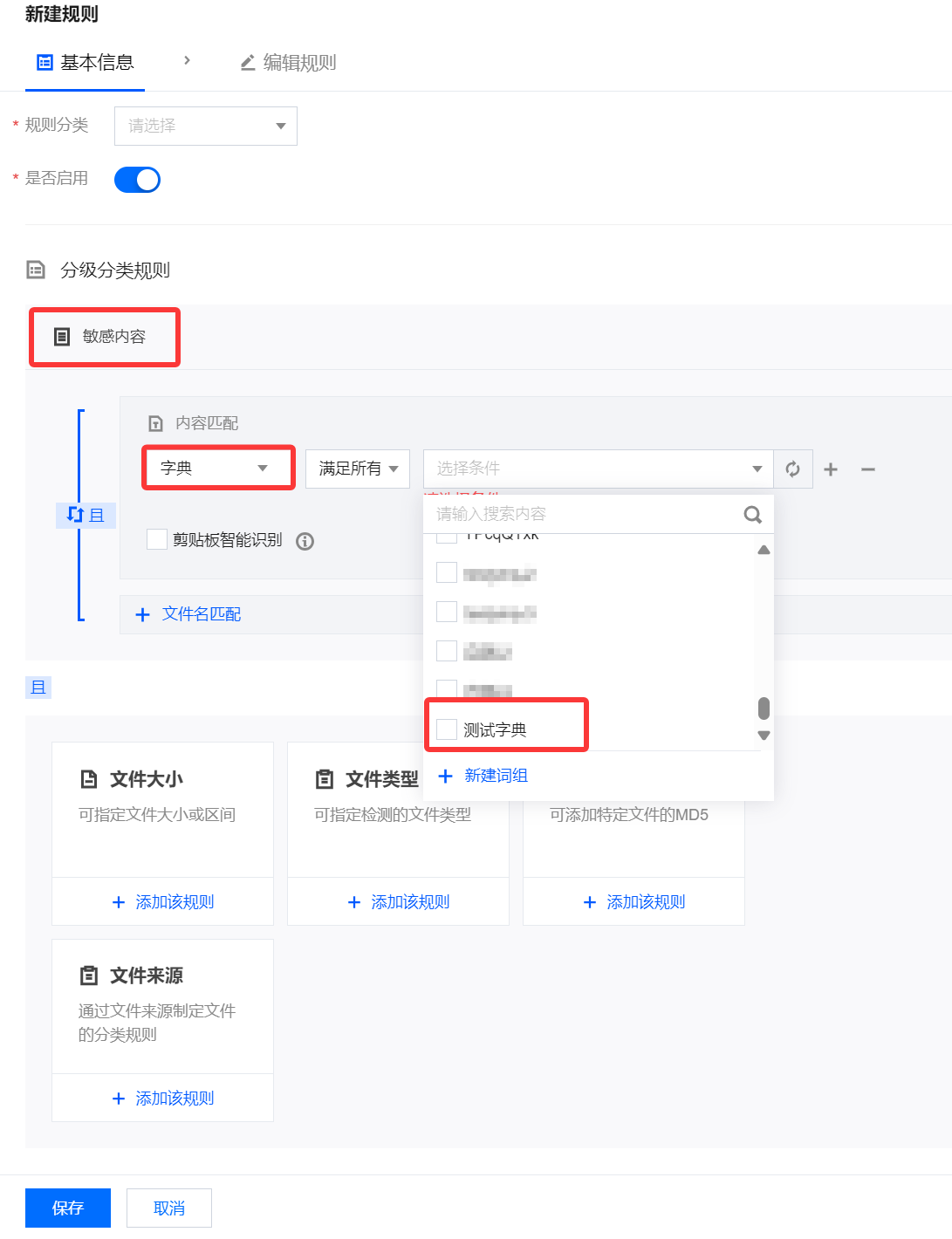
支持用户上传样本数据。借助自然语言处理(NLP)和上下文分析技术,系统能够对敏感样本进行智能学习,并支持以聚类或添加词典形式,将学习结果中获得的关键词作为规则,在分级分类规则的敏感内容中进行引用。
1. 登录 iOA 零信任管理平台控制台,在左侧导航栏,选择数据安全中心 > 分级分类运营 > 机器学习。
2. 在机器学习页面,单击添加模型。

3. 在添加模型页面,单击上传文件,可上传单个文件或批量相似文件, 上传完成后单击开始学习。
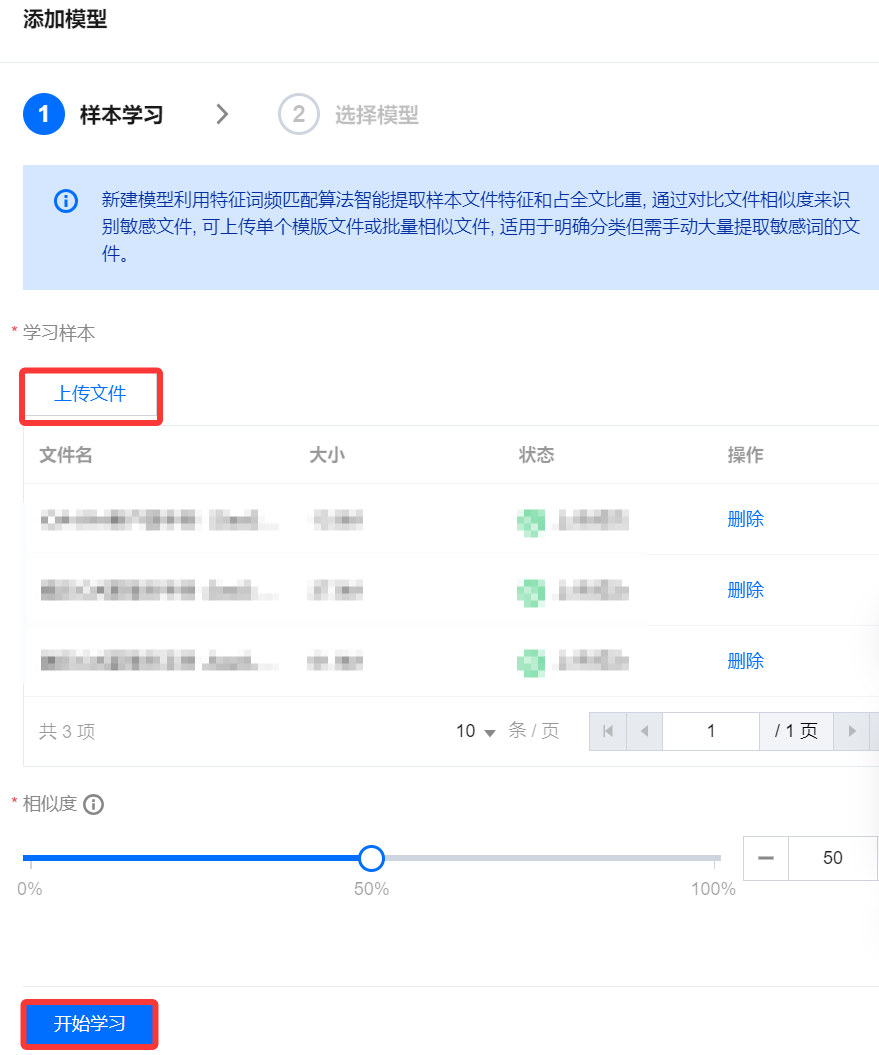
4. 相似度:自定义相似度的值,相似度仅影响机器学习文件分组结果,不影响敏感内容的提取。
4.1 模板文件/代码文件:上传单个文件,并将相似度调整至100% 。
4.2 多数据实际应用场景:可将不同后缀样本进行分析,相似度代表相似文件分类严格程度,阈值越高即分类越严格,学习结果分组会越多。可根据最终学习结果调整相似度阈值,以适配不同业务场景,请至少使用3个及以上样本文件进行学习。
5. 学习结果说明:
5.1 模型可由多个文档组成,多个文档进行聚合,将多个文档中所有的关键词按照权重进行汇总计算。
5.2 模型的数量与相似度关系:
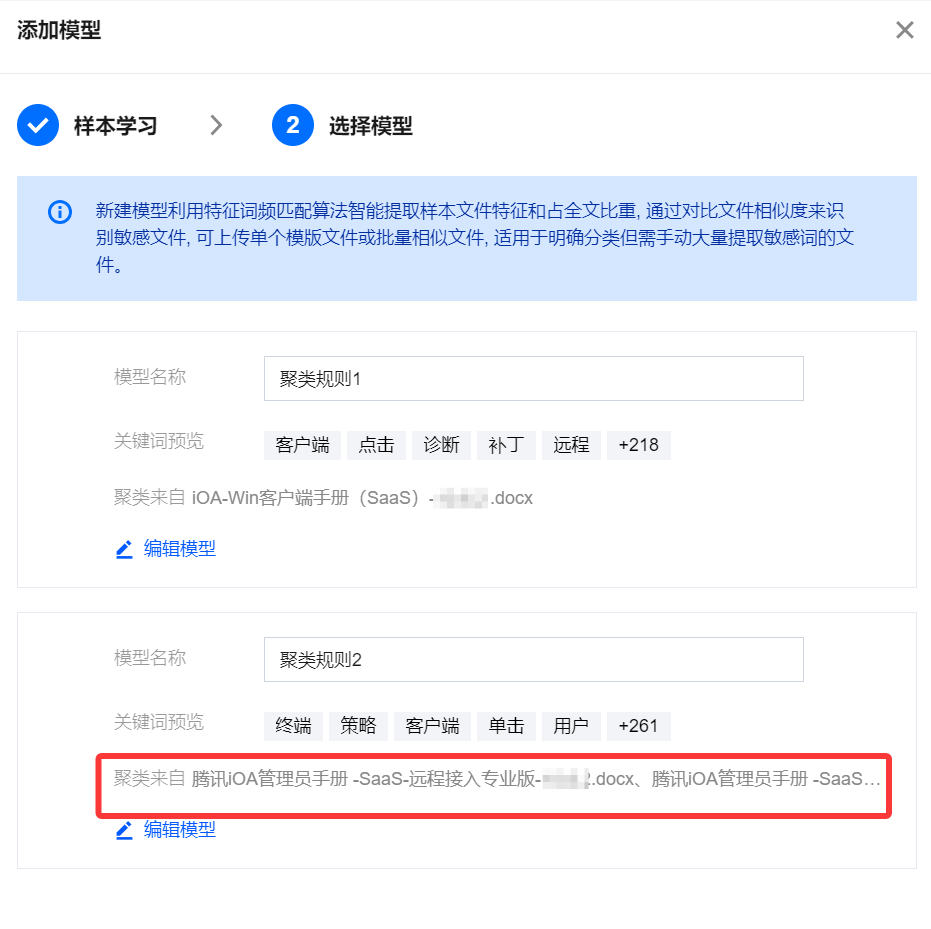
示例:当上传的 3 个文档中有 2 个文档高度相似且相似度设置百分比较低时,系统会自动将它们聚合为 1 个聚类(1个模型)。
如果是3个完全不同的文件,而 相似度设置百分比较高时,就会形成 3 个不同的聚类(3个模型)。
以下图为例:上传3个文档,设置相似度50%,因上传的管理员手册本身相似度较高,当设置相似度百分比为50%时,则自动聚合为1个聚类。
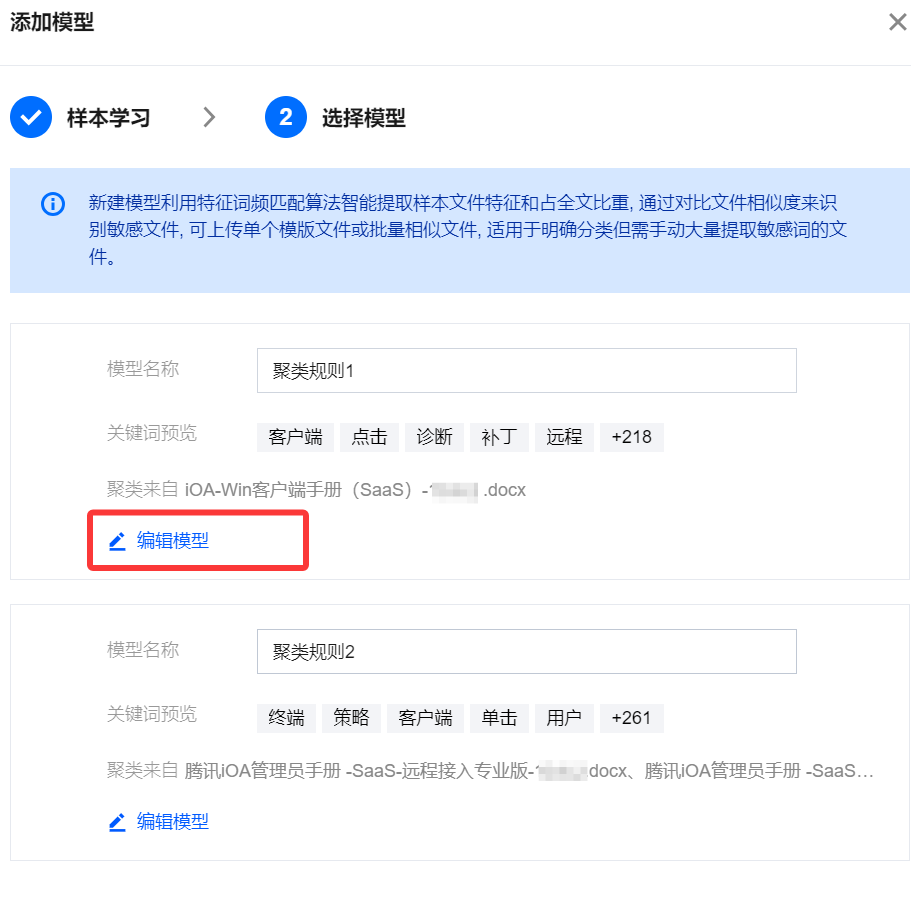
6. 文件组合为1个聚类,关键词众多,但并非所有关键词都具有实际价值。这种情况下,可勾选您认为有实际价值的关键词;支持编辑模型或字典模式。
6.1 编辑模型
6.1.1 单击编辑模型,完成编辑后单击确定保存,系统会从所选的关键词中生成模型。
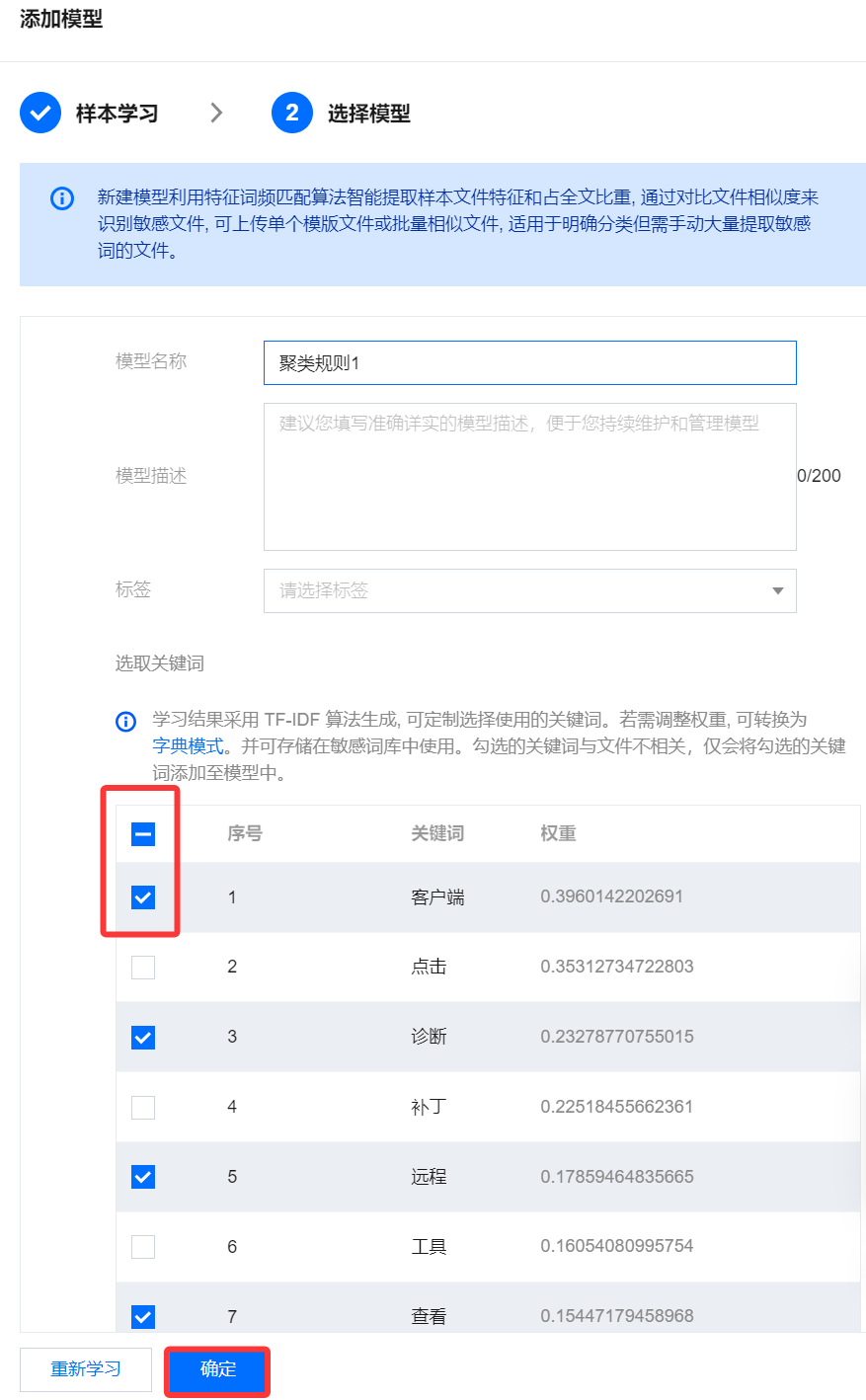
6.1.2 勾选您认为有实际价值的关键词,完成编辑后单击确定保存,系统会从所选的关键词中生成模型。
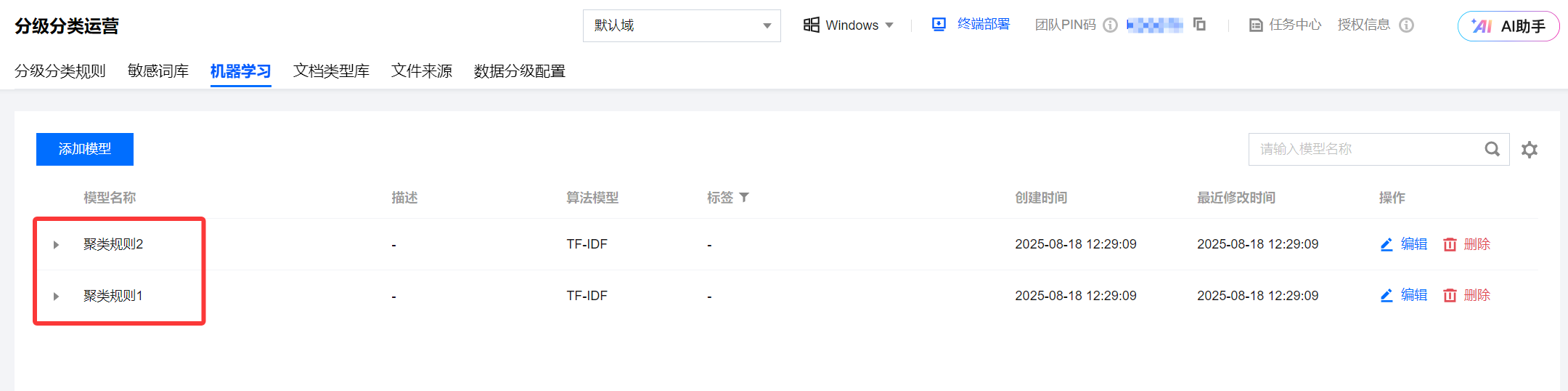
6.1.3 生成的模型如下图:
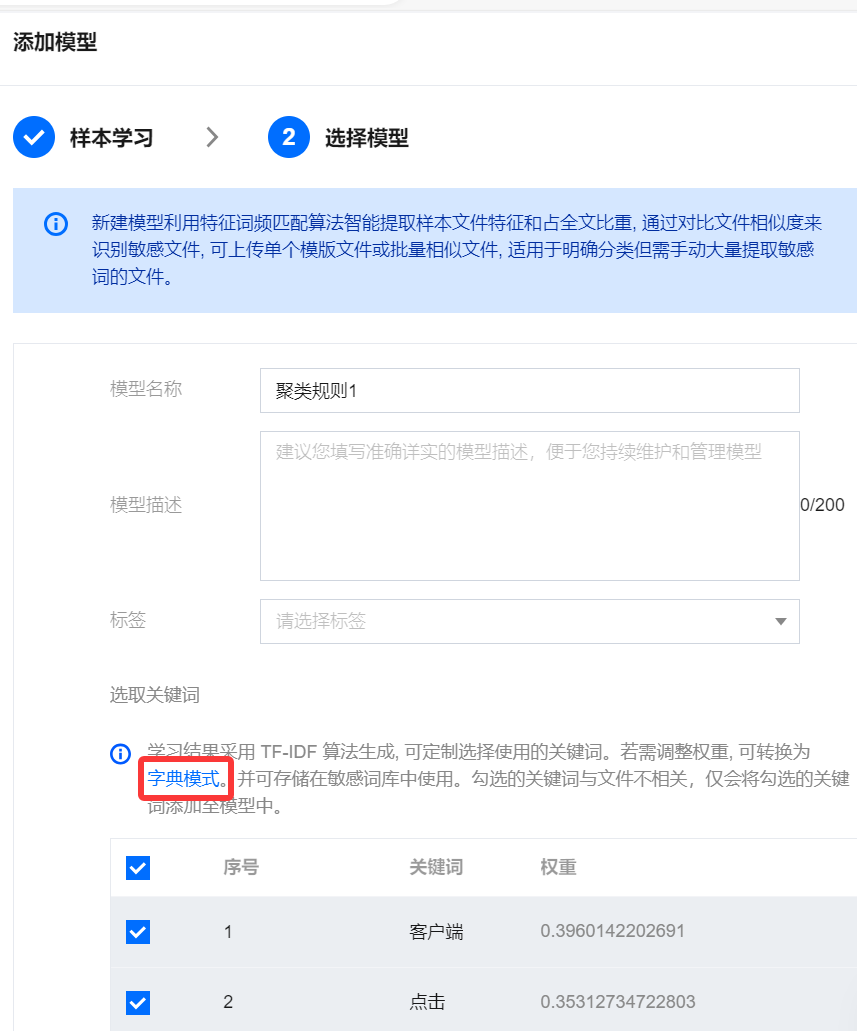
6.2 字典模式
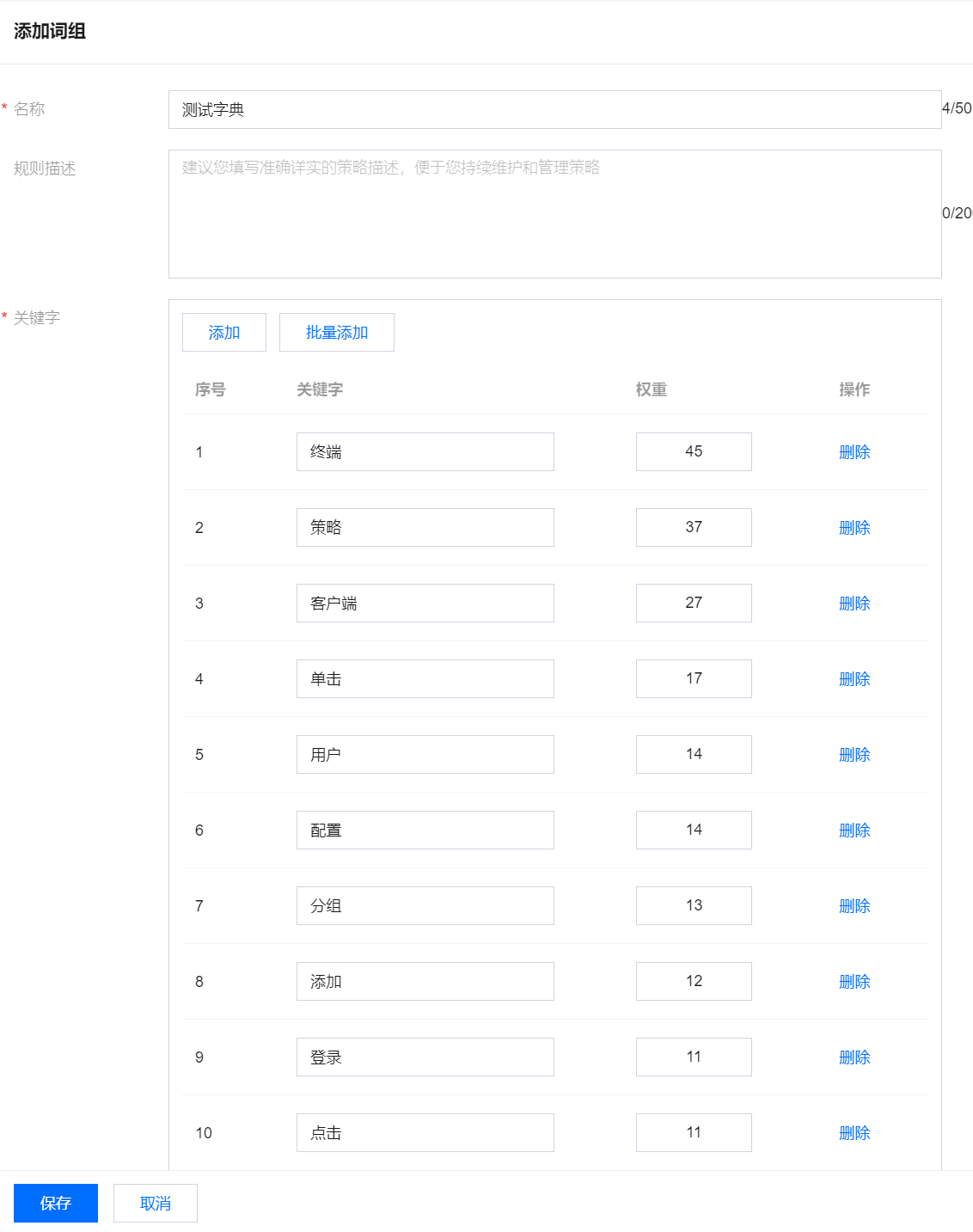
6.2.1 支持配置字典模式,单击字典模式,可将已计算出权重的模型,快速添加为字典。
6.2.2 选中的关键词保存在字典,可在分级分类运营 > 分级分类规则 > 敏感内容中选择字典,引用该规则。
7. 以词云或表格视角展示关键词。
词云视角:词云中仅显示学习结果后,进行保存的关键词,大小按照权重进行排列。
表格视角:按关键词权重结果生成列表(关键词+权重比例)。

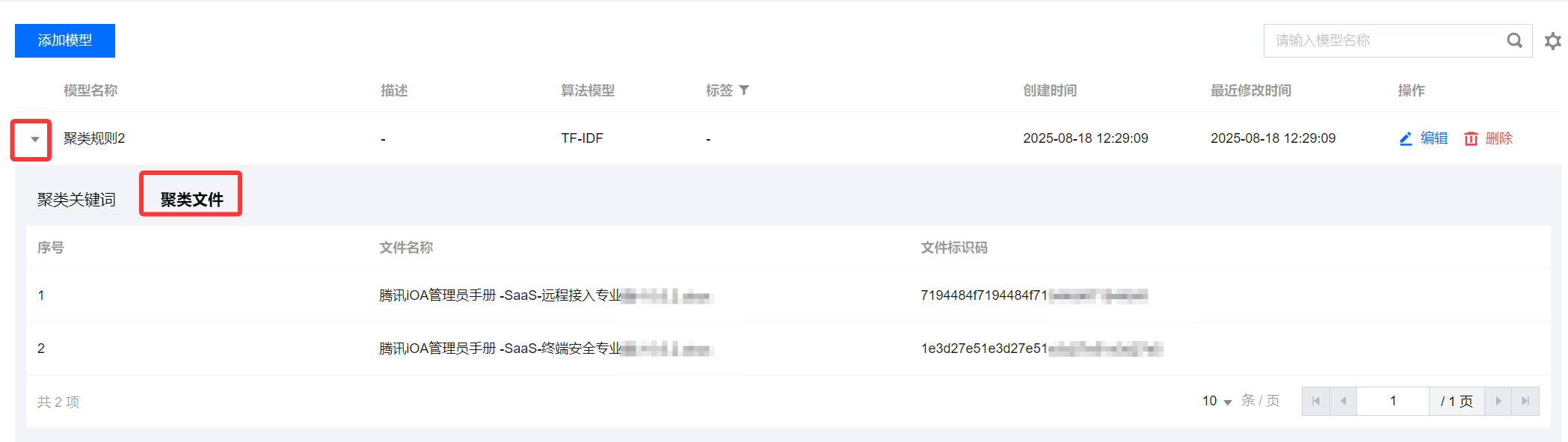
8. 聚类文件:根据学习结果,将符合相似度及以上的文件进行聚类(显示该模型所有聚类的文件名及 MD5值)。
9. 机器学习后的使用方式:通过“字典模式”生成字典后,在分级分类运营 > 分级分类规则 > 敏感内容中选择字典。