视频讲解
录音文件识别功能体验
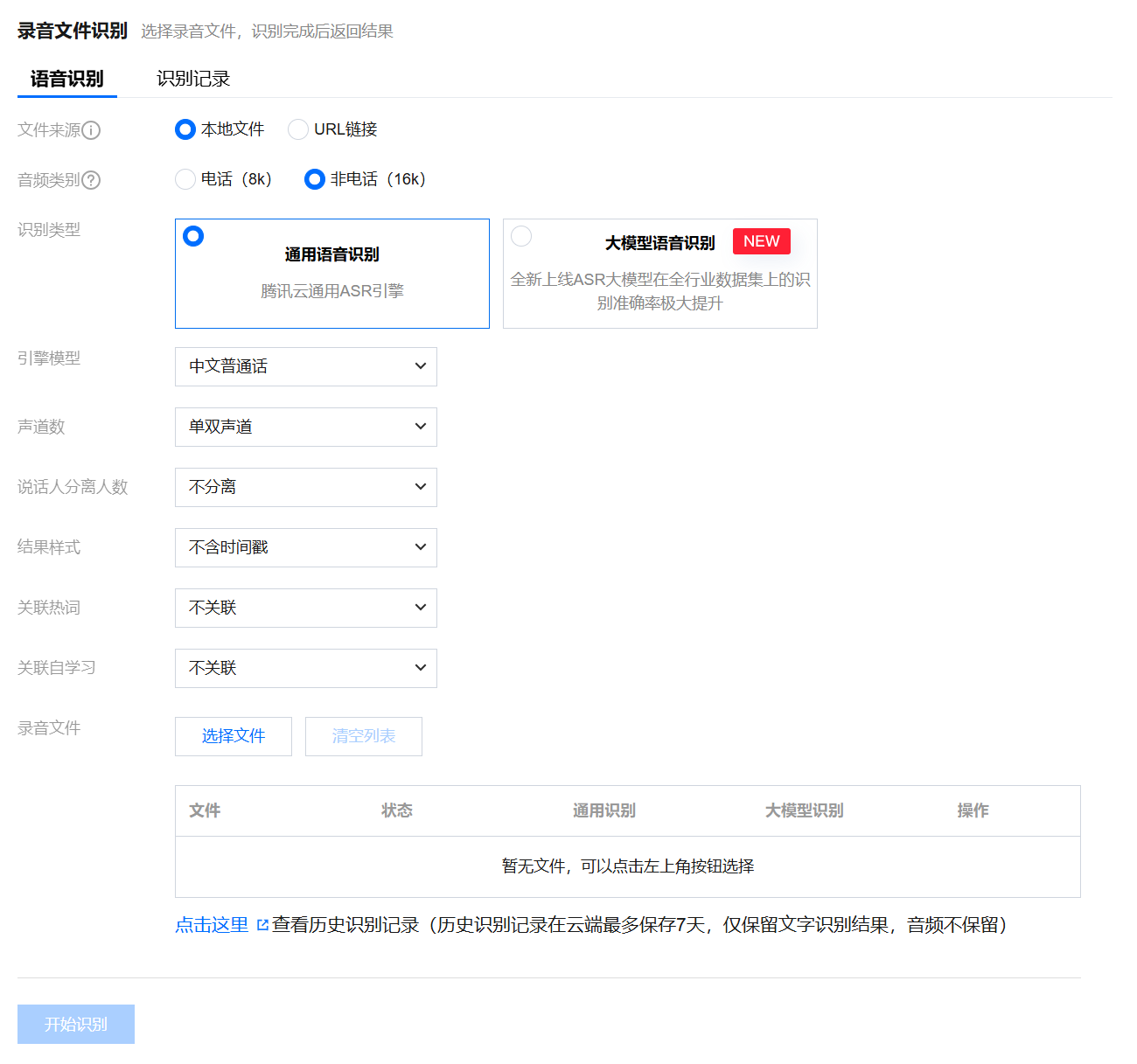
1. 进入 功能体验 界面,即可开始体验录音文件识别功能。
文件来源:支持上传本地文件和 URL 链接两种方式。需要您按照产品详细信息中的 录音文件识别 要求,音频 URL 时长不能大于5小时,文件大小不超过1GB;本地音频文件不能大于5MB。
音频类别:支持电话和非电话。两种类别音频的推荐位深都为16位。音频类别必须和上传的音频相匹配,才会得到正确的识别结果。若您不知道录音文件的音频属性,可在常见的音频软件中查看(例如 Adobe Audition),也可使用开源命令行工具 FFmpeg 进行查看。
电话:手机或座机通话生成的音频,一般采样率默认为8000Hz。
非电话:非手机或座机通话生成的音频,推荐的采样率为16000Hz。
识别类型:支持通用语音识别和大模型语音识别。
通用语音识别:腾讯云通用 ASR 引擎。
大模型语音识别:腾讯全新上线 ASR 大模型,在全行业数据集上的识别准确率极大提升。
支持的语种类别请前往 控制台 查看。
引擎模型:可根据您实际音频的语言和行业来选择,若您的音频并没有对应行业的引擎模型,建议使用对应语音的通用模型进行识别。
声道数:支持单双声道。
说话人分离人数:支持自动分离,最大分离人数10。
结果样式:支持含时间戳和不含时间戳。
含时间戳:识别结果带对应语音分片的起止时间。
不含时间戳:识别结果只包含文字。
关联热词:选择配置的热词,需配置热词可参见文档 热词。
关联自学习:选择配置的自学习定制模型,需配置自学习定制模型可参见 自学习定制模型。
录音文件:选择文件/文件地址。
“文件来源”选择本地文件时,单击选择文件进行本地文件上传。
“文件来源”选择 URL 链接时,需填写语音 URL 的地址。
2. 上传完文件后,单击开始识别,识别完后,单击下载结果即可查看语音识别的内容。
3. 点击这里即可跳转至识别记录页,可以查看音频名称、时长、类型、引擎模型、状态等相关信息。
实时语音识别功能体验
1. 手机扫码进行实时语音文件识别功能体验。

2. 选择“语音识别”进入功能体验。
3. 选择您需要体验的引擎模型。
4. 按住按钮进行说话,请在完全按住后再开始说话,说完后再松开按钮。
5. 可实时地获取识别结果。



