1. 接入流程
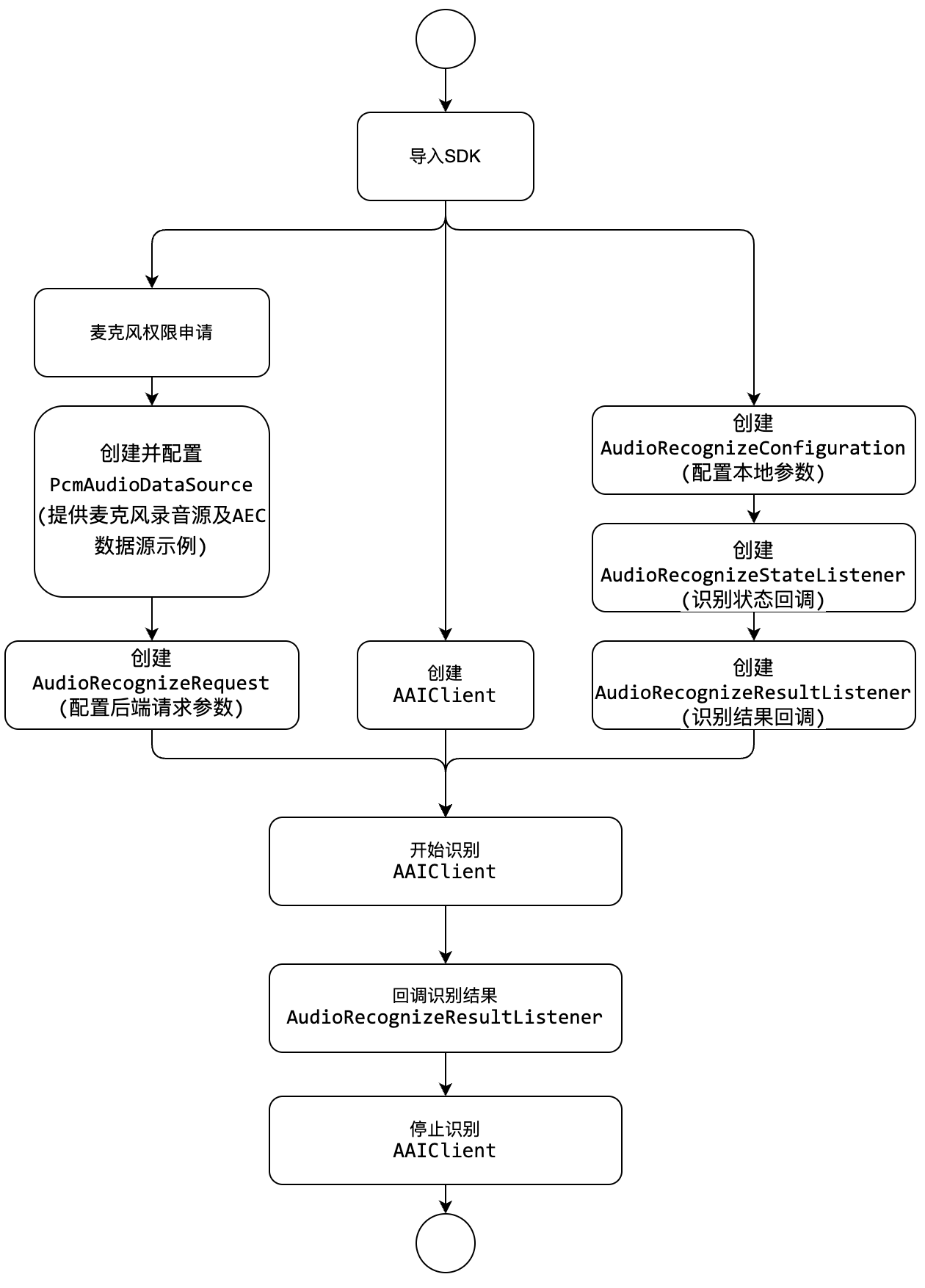
2. 接入准备
2.1 SDK 获取
2.2 接入须知
开发者在调用前请先查看实时语音识别的 接口说明,了解接口的使用要求和使用步骤。
该接口需要手机能够连接网络(3G、4G、5G 或 Wi-Fi 等),且系统为 Android 5.0 及其以上版本。
运行 Demo 必须设置 AppID、SecretID、SecretKey,可在 API 密钥管理 中获取。
2.3 开发环境
添加实时语音识别 SDK aar
将 asr-realtime-release.aar 放在 libs 目录下,在 App 的 build.gradle 文件中添加以下代码。
implementation(name: 'asr-realtime-release', ext: 'aar')
添加其他依赖,在 App 的 build.gradle 文件中添加以下代码。
implementation 'com.squareup.okhttp3:okhttp:4.2.2'
在 AndroidManifest.xml 添加如下权限:
<uses-permission android:name="android.permission.RECORD_AUDIO"/><uses-permission android:name="android.permission.INTERNET"/><uses-permission android:name="android.permission.ACCESS_NETWORK_STATE" />
2.4 混淆规则
-keepclasseswithmembernames class * { # 保持 native 方法不被混淆native <methods>;}-keep public class com.tencent.aai.*-keep public class com.qq.wx.voice.*
3. 快速接入
3.1 启动实时语音识别
int appid = XXX;int projectid = 0; //此参数固定为0;String secretId = "XXX";final AAIClient aaiClient;try {//0. 获取SDK版本号信息String version = AAIClient.getVersion();/**直接鉴权**/aaiClient = new AAIClient(MainActivity.this, appid, projectId, secretId ,new LocalCredentialProvider(secretKey));/**使用临时密钥鉴权* * 1.通过sts 获取到临时证书 (secretId secretKey token) ,此步骤应在您的服务器端实现,见https://cloud.tencent.com/document/product/598/33416* 2.通过临时密钥调用接口* **/// aaiClient = new AAIClient(MainActivity.this, appid, projectId,"临时secretId", "临时secretKey","对应的token");// 2、初始化语音识别请求。AudioRecognizeRequest.Builder builder = new AudioRecognizeRequest.Builder();final AudioRecognizeRequest audioRecognizeRequest = builder//设置数据源,数据源要求实现PcmAudioDataSource接口,您可以自己实现此接口来定制您的自定义数据源,例如从第三方推流中获.pcmAudioDataSource(new AudioRecordDataSource(false)) // 使用SDK内置录音器作为数据源,false:不保存音频.setEngineModelType("16k_zh") // 设置引擎参数("16k_zh" 通用引擎,支持中文普通话+英文).setFilterDirty(0) // 0 :默认状态 不过滤脏话 1:过滤脏话.setFilterModal(0) // 0 :默认状态 不过滤语气词 1:过滤部分语气词 2:严格过滤.setFilterPunc(0) // 0 :默认状态 不过滤句末的句号 1:滤句末的句号.setConvert_num_mode(1) //1:默认状态 根据场景智能转换为阿拉伯数字;0:全部转为中文数字。.setNeedvad(1) //0:关闭 vad,1:默认状态 开启 vad。语音时长超过一分钟需要开启,如果对实时性要求较高,并且时间较短的输入,建议关闭// .setHotWordId("")//热词 id。用于调用对应的热词表,如果在调用语音识别服务时,不进行单独的热词 id 设置,自动生效默认热词;如果进行了单独的热词 id 设置,那么将生效单独设置的热词 id。//.setCustomizationId("")//自学习模型 id。如果设置了该参数,那么将生效对应的自学习模型.build();// 3、初始化语音识别结果监听器。final AudioRecognizeResultListener audioRecognizeResultlistener = new AudioRecognizeResultListener() {@Overridepublic void onSliceSuccess(AudioRecognizeRequest request, AudioRecognizeResult result, int seq) {//返回分片的识别结果,此为中间态结果,会被持续修正}@Overridepublic void onSegmentSuccess(AudioRecognizeRequest request, AudioRecognizeResult result, int seq) {//返回语音流的识别结果,此为稳定态结果,可做为识别结果用与业务}@Overridepublic void onSuccess(AudioRecognizeRequest request, String result) {//识别结束回调,返回所有的识别结果}@Overridepublic void onFailure(AudioRecognizeRequest request, final ClientException clientException, final ServerException serverException,String response) {// 识别失败}};// 4、自定义识别配置final AudioRecognizeConfiguration audioRecognizeConfiguration = new AudioRecognizeConfiguration.Builder()//分片默认40ms,可设置40-5000,如果您不了解此参数不建议更改//.sliceTime(40)// 是否使能静音检测,.setSilentDetectTimeOut(false)// 静音检测超时停止录音可设置>2000ms,setSilentDetectTimeOut为true有效,超过指定时间没有说话将关闭识别;需要大于等于sliceTime,实际时间为sliceTime的倍数,如果小于sliceTime,则按sliceTime的时间为准.audioFlowSilenceTimeOut(5000)// 音量回调时间,需要大于等于sliceTime,实际时间为sliceTime的倍数,如果小于sliceTime,则按sliceTime的时间为准.minVolumeCallbackTime(80).build();// 5、启动语音识别new Thread(new Runnable() {@Overridepublic void run() {if (aaiClient!=null) {aaiClient.startAudioRecognize(audioRecognizeRequest,audioRecognizeResultlistener,audioRecognizeStateListener,audioRecognizeConfiguration);}}}).start();// 6、log组件设置// 将log落盘到本地磁盘,needLogFile字段默认为false,接入调试期间建议设置为true,上线后此接口调用可删除。AAILogger.setNeedLogFile(true, getApplicationContext());// 设置日志级别,默认为ERROR_LEVEL,接入调试期间建议设置为DEBUG_LEVEL。AAILogger.setLogLevel(AAILogger.DEBUG_LEVEL);// 设置日志监听器,用于监听日志信息。AAILogger.setLoggerListener(new LoggerListener() {@Overridepublic void onLogInfo(String s) {}});} catch (ClientException e) {e.printStackTrace();}
3.2 停止实时语音识别
new Thread(new Runnable() {@Overridepublic void run() {if (aaiClient!=null){//停止语音识别,等待最终识别结果aaiClient.stopAudioRecognize();}}}).start();
3.3 取消实时语音识别
new Thread(new Runnable() {@Overridepublic void run() {if (aaiClient!=null){//取消语音识别,丢弃当前任务,丢弃最终结果aaiClient.cancelAudioRecognize();}}}).start();
4. 主要接口类和方法说明
4.1 初始化 AAIClient
AAIClient 是语音服务的核心类,用户可以调用该类来开始、停止以及取消语音识别。
public AAIClient(Context context, int appid, int projectId, String secretId, AbsCredentialProvider credentialProvider) throws ClientException
参数名称 | 类型 | 是否必填 | 参数描述 |
context | Context | 是 | 上下文 |
appid | int | 是 | 腾讯云注册的 appid |
projectId | int | 否 | 此参数固定为0 |
secretId | String | 是 | 用户的 secretId |
credentialProvider | AbsCredentialProvider | 是 | 鉴权类 |
示例:
try {AAIClient aaiClient = new AAIClient(context, appid, projectId, secretId, credentialProvider);} catch (ClientException e) {e.printStackTrace();}
如果 aaiClient 不再需要使用,请调用 release() 方法释放资源:
aaiClient.release();
4.2 配置全局参数
用户调用 ClientConfiguration 类的静态方法来修改全局配置。
方法 | 方法描述 | 默认值 | 有效范围 |
setAudioRecognizeSliceTimeout | HTTP 读超时时间 | 5000ms | 500 - 10000ms |
setAudioRecognizeConnectTimeout | HTTP 连接超时时间 | 5000ms | 500 - 10000ms |
setAudioRecognizeWriteTimeout | HTTP 写超时时间 | 5000ms | 500 - 10000ms |
示例:
ClientConfiguration.setAudioRecognizeSliceTimeout(2000)ClientConfiguration.setAudioRecognizeConnectTimeout(2000)ClientConfiguration.setAudioRecognizeWriteTimeout(2000)
4.3 设置结果监听器
AudioRecognizeResultListener 可以用来监听语音识别的结果,共有如下四个接口:
语音分片的语音识别结果回调接口
void onSliceSuccess(AudioRecognizeRequest request, AudioRecognizeResult result, int order);
参数 | 参数类型 | 参数描述 |
request | AudioRecognizeRequest | 语音识别请求 |
result | AudioRecognizeResult | 语音分片的语音识别结果 |
order | int | 该语音分片所在语音流的次序 |
语音流的语音识别结果回调接口
void onSegmentSuccess(AudioRecognizeRequest request, AudioRecognizeResult result, int seq);
参数 | 参数类型 | 参数描述 |
request | AudioRecognizeRequest | 语音识别请求 |
result | AudioRecognizeResult | 语音分片的语音识别结果 |
seq | int | 该语音流的次序 |
返回所有的识别结果
void onSuccess(AudioRecognizeRequest request, String result);
参数 | 参数类型 | 参数描述 |
request | AudioRecognizeRequest | 语音识别请求 |
result | String | 所有的识别结果 |
语音识别请求失败回调函数
void onFailure(AudioRecognizeRequest request, final ClientException clientException, final ServerException serverException,String response);
参数 | 参数类型 | 参数描述 |
request | AudioRecognizeRequest | 语音识别请求 |
clientException | ClientException | 客户端异常 |
serverException | ServerException | 服务端异常 |
response | String | 服务端返回的 JSON 字符串 |
4.4 设置语音识别参数
通过构建 AudioRecognizeConfiguration 类,可以设置语音识别时的配置:
参数名称 | 类型 | 是否必填 | 参数描述 | 默认值 |
setSilentDetectTimeOut | Boolean | 否 | 是否开启静音检测,开启后检测到超时不说话将停止识别 | false |
audioFlowSilenceTimeOut | int | 否 | 配置 setSilentDetectTimeOut 超时时间 | 5000ms |
minVolumeCallbackTime | int | 否 | 音量检测回调时间 | 80ms |
示例:
AudioRecognizeConfiguration audioRecognizeConfiguration = new AudioRecognizeConfiguration.Builder().setSilentDetectTimeOut(true)// 是否开启静音检测,开启后检测到超时不说话将停止识别.audioFlowSilenceTimeOut(5000) // 静音检测超时停止录音.minVolumeCallbackTime(80) // 音量回调时间.build();
4.5 设置状态监听器
AudioRecognizeStateListener 可以用来监听语音识别的状态:
方法 | 方法描述 |
onStartRecord | 开始录音 |
onStopRecord | 结束录音 |
onVoiceDb | 音量分贝(取值范围:0 - 100,集中分布在40 - 80) |
onNextAudioData | 返回音频流,用于返回宿主层做录音缓存业务。new AudioRecordDataSource(true) 传递 true 时生效 |
onSilentDetectTimeOut | 静音检测超时回调,此时任务还未中止,仍会等待最终识别结果 |
示例:
AudioRecognizeStateListener audioRecognizeStateListener = new AudioRecognizeStateListener() {@Overridepublic void onStartRecord(AudioRecognizeRequest audioRecognizeRequest) {// 开始录音}@Overridepublic void onStopRecord(AudioRecognizeRequest audioRecognizeRequest) {// 结束录音}@Overridepublic void onVoiceVolume(AudioRecognizeRequest audioRecognizeRequest, int i) {// 音量回调}/*** 返回音频流,* 用于返回宿主层做录音缓存业务。* 由于方法跑在sdk线程上,这里多用于文件操作,宿主需要新开一条线程专门用于实现业务逻辑* new AudioRecordDataSource(true) 有效,否则不会回调该函数* @param audioDatas*/@Overridepublic void onNextAudioData(final short[] audioDatas, final int readBufferLength){}/*** 静音检测超时回调* 注意:此时任务还未中止,仍然会等待最终识别结果*/@Overridevoid onSilentDetectTimeOut(){//触发了静音检测事件}};
4.6 其他重要类说明
4.6.1 AudioRecognizeRequest
参数名称 | 类型 | 是否必填 | 参数描述 | 默认值 |
pcmAudioDataSource | PcmAudioDataSource | 是 | 音频数据源 | 无 |
setEngineModelType | String | 否 | 设置引擎参数 | "16k_zh" |
setFilterDirty | int | 否 | 0 :不过滤脏话 1:过滤脏话 | 0 |
setFilterModal | int | 否 | 0 :不过滤语气词 1:过滤部分语气词 2:严格过滤 | 0 |
setFilterPunc | int | 否 | 0 :不过滤句末的句号 1:滤句末的句号 | 0 |
setConvert_num_mode | int | 否 | 1: 根据场景智能转换为阿拉伯数字;0:全部转为中文数字。 | 1 |
setVadSilenceTime | int | 否 | 语音断句检测阈值,静音时长超过该阈值会被认为断句(需配合 needvad = 1 使用) 默认不传递该参数,不建议更改 | 无 |
setNeedvad | int | 否 | 0:关闭 vad,1: 开启 vad。语音时长超过一分钟需要开启,如果对实时性要求较高。 | 1 |
setHotWordId | String | 否 | 热词 ID。用于调用对应的热词表,如果在调用语音识别服务时,不进行单独的热词 id 设置,自动生效默认热词;如果进行了单独的热词 ID 设置,那么将生效单独设置的热词 ID。 | 无 |
setWordInfo | int | 否 | 是否显示词级别时间戳。0:不显示;1:显示,不包含标点时间戳,2:显示,包含标点时间戳。时间戳信息需要自行解析 AudioRecognizeResult.resultJson 获取 | 0 |
setCustomizationId | String | 否 | 自学习模型 ID。如不设置该参数,自动生效最后一次上线的自学习模型;如果设置了该参数,那么将生效对应的自学习模型。 | 无 |
setNoiseThreshold | float | 否 | 噪音参数阈值,默认为0,取值范围:[-2,2],详情见 API 文档 | 无 |
setMaxSpeakTime | int | 否 | 强制断句功能,取值范围 5000-90000(单位:毫秒),在连续说话不间断情况下,该参数将实现强制断句。 | 默认值为0(不开启) |
setApiParam | Object | 否 | 自定义请求参数,用于在请求中添加 SDK 尚未支持的参数 | 无 |
4.6.2 AudioRecognizeResult
语音识别结果对象,和 AudioRecognizeRequest 对象相对应,用于返回语音识别的结果。
参数名称 | 类型 | 参数描述 |
sliceType | int | 0表示一小段话开始,1表示在小段话的进行中,2表示小段话的结束 |
message | String | 识别提示信息 |
text | String | 识别结果 |
seq | int | 当前一段话结果在整个音频流中的序号,从0开始逐句递增 |
voiceId | String | 该语音分片所在语音流的 ID |
startTime | int | 当前一段话结果在整个音频流中的起始时间 |
endTime | int | 当前一段话结果在整个音频流中的结束时间 |
resultJson | String | 后端返回的 JSON 原文本,可解析出上面列出的参数内容,如有需求,您可以自行解析获取更多信息 |
4.6.3 PcmAudioDataSource
用户可以实现这个接口来识别单通道、采样率16k的 PCM 音频数据。主要包括如下几个接口:
向语音识别器添加数据,将长度为 length 的数据从下标0开始复制到 audioPcmData 数组中,并返回实际的复制的数据量的长度。
int read(short[] audioPcmData, int length);
启动识别时回调函数,用户可以在这里做些初始化的工作。
void start() throws AudioRecognizerException;
结束识别时回调函数,用户可以在这里进行一些清理工作。
void stop();
是否保存语音源文件的开关,打开后,音频数据将通过 onNextAudioData 回调返回给调用层。
boolean isSetSaveAudioRecordFiles();
4.6.4 AudioRecordDataSource
PcmAudioDataSource 接口的实现类,可以直接读取麦克风输入的音频数据,用于实时识别,其中 Demo 也提供了一份录音器源码作为数据源的示例,源码与 SDK 内置录音器 AudioRecordDataSource 一致,您可以参考此源代码自由定制修改,详情查阅 SDK 包内 DemoAudioRecordDataSource.java 内注释。
4.6.5 AAILogger
用户可以利用 AAILogger 来控制日志的输出,可以选择性地输出 debug、info、warn 以及 error 级别的日志信息。
public static void disableDebug();public static void disableInfo();public static void disableWarn();public static void disableError();public static void enableDebug();public static void enableInfo();public static void enableWarn();public static void enableError();
5. 错误码
后端错误码,详情请参见 API 文档。
客户端错误码如下:
错误码 | 名称 | 描述 |
-100 | AUDIO_RECORD_INIT_FAILED | 录音器初始化失败 |
-101 | AUDIO_RECORD_START_FAILED | 录音器启动失败 |
-102 | AUDIO_RECORD_MULTIPLE_START | 录音器重复启动 |
-103 | AUDIO_RECOGNIZE_THREAD_START_FAILED | 创建线程失败,录音线程无法启动 |
-104 | AUDIO_SOURCE_DATA_NULL | 数据源为空 |
-105 | AUDIO_RECOGNIZE_REQUEST_NULL | 请求参数为空 |
-106 | WEBSOCKET_NETWORK_FAILED | WebSocket 网络连接失败 |
-1 | UNKNOWN_ERROR | 未知异常,详见 message 信息 |
6. 常见问题指引
6.1 音频数据本地缓存指引
宿主层可根据自身业务需求选择将音频保存到本地或者不保存。若需要保存到本地可按照如下步骤进行操作:
1.
new AudioRecordDataSource(isSaveAudioRecordFiles) 初始化时,isSaveAudioRecordFiles 设置为 true。2.
AudioRecognizeStateListener.onStartRecord 回调函数内添加创建本次录音的文件逻辑。路径、文件名可支持自定义。3.
AudioRecognizeStateListener.onStopRecord 回调函数内添加关流逻辑。(可选)将 PCM 文件转存为 WAV 文件。4.
AudioRecognizeStateListener.onNextAudioData 回调函数内添加将音频流写入本地文件的逻辑。5. 由于回调函数均跑在 SDK 线程中。为了避免写入业务耗时问题影响 SDK 内部运行流畅度,建议将上述步骤放在单独线程池里完成,详情见 Demo 工程中的
MainActivity 类中的示例代码。6.2 回音消除指引
本小节主要介绍如何通过 Android 原生 API 实现回音消除,下面将分章节详细展开(详情可参见 Demo 工程中的 DemoAudioRecordDataSource 类里的 start 方法)。
6.2.1 设置音源的方式
/*** 注: 部分android机型可以通过该方式解决回音消除失效的问题* https://blog.csdn.net/wyw0000/article/details/125195997*/// 1. 设置音频模式为AudioManager.MODE_IN_COMMUNICATION可以起到回音消除的作用AudioManager audioManager = (AudioManager)context.getSystemService(Context.AUDIO_SERVICE);audioManager.setMode(AudioManager.MODE_IN_COMMUNICATION);// 2. 音频源使用MediaRecorder.AudioSource.VOICE_COMMUNICATION可以起到回音消除的作用int audioSource = MediaRecorder.AudioSource.VOICE_COMMUNICATION;AudioRecord audioRecord = new AudioRecord(audioSource, sampleRate, channel, audioFormat, bufferSize);
6.2.2 尝试开启 AEC 和噪音抑制
/*** 注: 以下两个能力(AcousticEchoCanceler和NoiseSuppressor)和手机硬件能力相关,有些机型(比如小米11)即使isAvailable()==true,回音消除也不生效*/// AcousticEchoCanceler回音消除if (AcousticEchoCanceler.isAvailable()) {Log.d(TAG, "AcousticEchoCanceler isAvailable.");AcousticEchoCanceler acousticEchoCanceler = AcousticEchoCanceler.create(audioRecord.getAudioSessionId());int resultCode = acousticEchoCanceler.setEnabled(true);if (AudioEffect.SUCCESS == resultCode) {Log.d(TAG, "AcousticEchoCanceler AudioEffect SUCCESS");}}// NoiseSuppressor噪音抑制if (NoiseSuppressor.isAvailable()) {Log.d(TAG, "NoiseSuppressor isAvailable.");NoiseSuppressor noiseSuppressor = NoiseSuppressor.create(audioRecord.getAudioSessionId());int resultCode = noiseSuppressor.setEnabled(true);if (AudioEffect.SUCCESS == resultCode) {Log.d(TAG, "NoiseSuppressor AudioEffect SUCCESS");}}