问题描述
MySQL 实例 CPU 利用率过高通常容易导致系统异常,例如响应变慢、无法获取连接、超时等,大量的超时重试往往是性能“雪崩”的罪魁祸首。而 CPU 利用率过高场景,很多时候均是由异常 SQL 所导致,大量锁冲突、锁等待或事务未提交也有可能导致 MySQL 实例 CPU 利用率高。
当数据库执行业务查询、修改语句时,CPU 会先从内存中请求数据块(默认是8kb):
如果内存中存在对应的数据,CPU 执行计算任务后会将结果返回给用户,可能涉及到排序类高消耗 CPU 的动作。
如果内存中不存在对应的数据,数据库会触发从磁盘获取数据的动作。
这两个数据获取过程分别称为逻辑读和物理读。因此,性能较低的 SQL,在执行时容易让数据库产生大量的逻辑读,从而导致 CPU 利用率过高,也可能让数据库产生大量的物理读,从而导致 IOPS 和 I/O 时延过高。
解决方案
DBbrain 为用户提供三大功能来排查和优化导致 CPU 利用率过高的异常 SQL 语句:
异常诊断:7 * 24小时异常发现诊断,提供实时优化建议。
慢 SQL 分析:针对当前实例出现的慢 SQL 进行分析,并给出慢 SQL 的优化建议。
方式一:使用“异常诊断”功能排查数据库异常情况(推荐)
异常诊断功能提供故障主动定位和优化,不需要任何数据库运维经验,不仅包括 CPU 利用率过高的异常,还几乎涵盖所有 MySQL 实例高频的异常和故障。
操作步骤及示例如下:
1. 登录 DBbrain 控制台,在左侧导航选择诊断优化,在上方选择异常诊断页。
2. 在页面上方选择数据库类型,选择实例或节点 ID。
3. 在页面中选择实时或历史要查询的时间,若该时间段内存在故障,可在右侧的“诊断提示”中查看到概要信息。
4. 单击“实时/历史诊断”栏的查看详情或诊断提示栏的诊断项可进入诊断详情页。
事件概要:包括诊断项、起止时间、风险等级、持续时长、概要等信息。
现象描述:异常事件(或健康巡检事件)的外在表现现象的快照和性能趋势。
智能分析:分析导致性能异常的根本原因,定位具体操作。
专家建议:提供优化指导建议,包括但不限于 SQL 优化(索引建议、重写建议)、资源配置优化和参数调优。
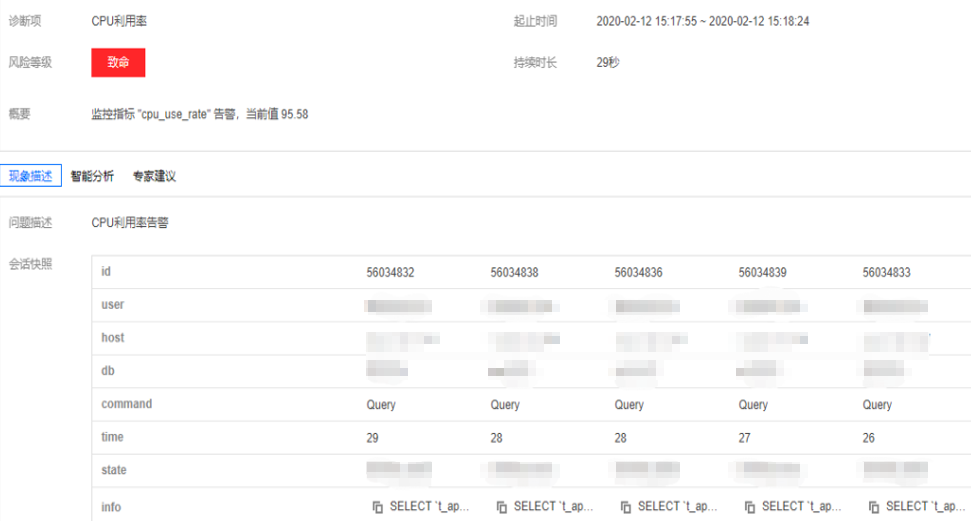
5. 选择专家建议页,即可查看 DBbrain 针对该故障给出的优化建议,本例中是 SQL 语句的优化建议。本例中的 SQL 语句执行时缺少对应的索引,导致该语句执行时要进行全表扫描,单次执行成本高,所以大量并发场景下就很容易导致 CPU 利用率过高,可能会达到100%的状况。
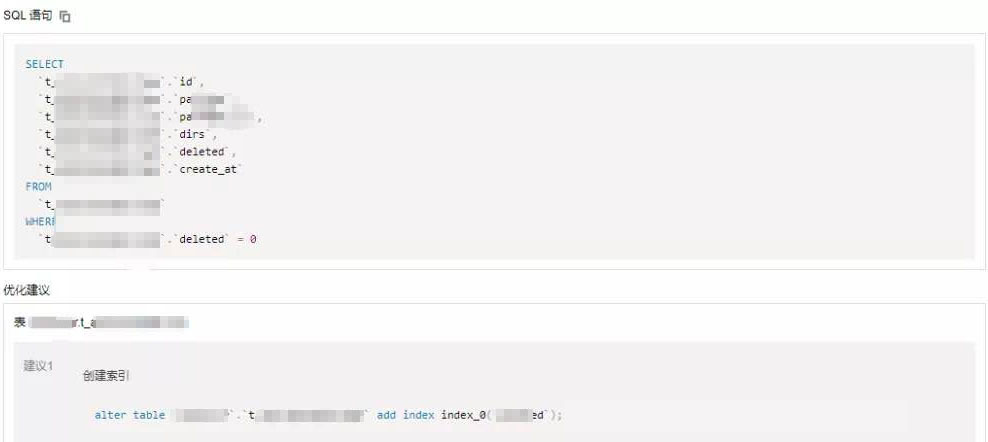
方式二:使用“慢 SQL 分析”功能排查导致 CPU 利用率过高的 SQL
1. 登录 DBbrain 控制台,在左侧导航选择诊断优化,在上方选择慢 SQL 分析页。
2. 在页面上方选择数据库类型,选择实例或节点 ID。
3. 在页面中选择要查询的时间,若此实例在该时间段中有慢 SQL,SQL 统计会以柱形图的方式展示慢 SQL 产生的时间点和个数。
单击柱形图,下方的列表会显示对应的所有慢 SQL 信息(模板聚合之后的 SQL),右方会显示该时间段内 SQL 的耗时分布。
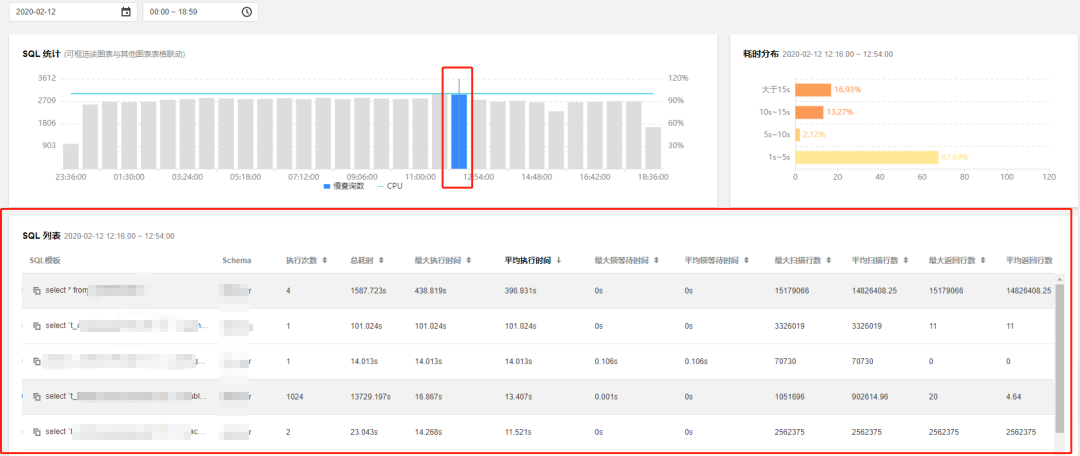
4. 针对 SQL 列表中 SQL 执行的数据进行判断和筛选,下面简单介绍一种判断方式:
4.1 先按照平均耗时(或者最大耗时)降序,重点关注耗时处在 top 的 SQL,不推荐使用总耗时,容易受到执行次数多而累加的干扰。
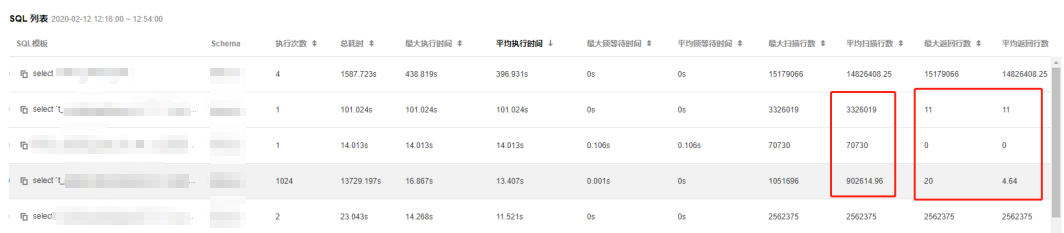
4.2 然后关注返回行数和扫描行数的值。
若发现“返回行数”与“扫描行数”值相等的 SQL,大概率是全表查找并返回了。

若发现几行 SQL 都有很多扫描行数,但返回行数都为0或特别小,说明系统产生了大量的逻辑读和物理读。当查找的数据量过大且内存不足时,该请求必然会产生大量的物理 I/O 请求,导致 I/O 资源大量消耗;大量的逻辑读便会占用大量的 CPU 资源,导致 CPU 利用率过高。
5. 单击 SQL 语句,可查看该 SQL 语句的详情、资源消耗以及优化建议。
分析页:可查看完整的 SQL 模板、SQL 样例以及优化建议和说明,您可根据 DBbrain 给出的专家建议优化 SQL,提升 SQL 性能,降低 SQL 执行的耗时。
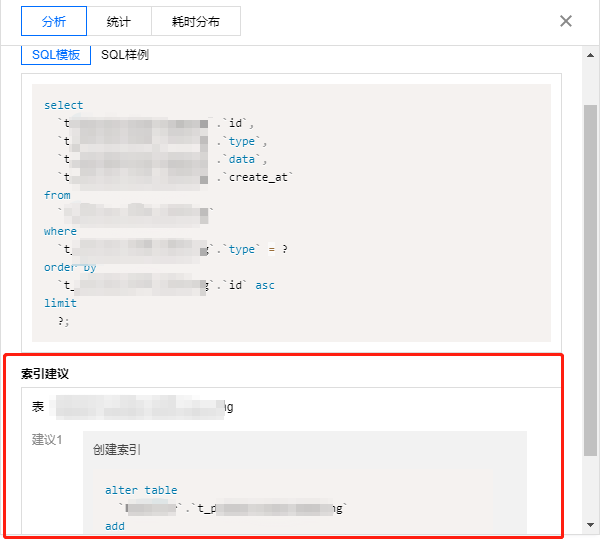
统计页:可根据统计报表的总锁等待时间占比、总扫描行数占比、总返回行数占比,横向分析该条慢 SQL 产生的具体原因,以及进行对应优化。
耗时分布页:可查看该类型的 SQL(经过聚合后汇总的)运行的时间分布区间,以及来源 IP 的访问占比。



