AI 类数据库下集合视图的数据操作支持文档导入、文档内容检索、查询文档详情、获取文档列表、查询文本块、更新文档和删除文档。
文档导入
支持导入格式为 Markdown、PDF、PPT、Word 的文档,并支持为导入的文档配置元数据字段及值。
文档内容检索
基于相似度匹配的查询方式,用于在指定的文档中,查找与指定文本信息相似的 Top K 条文本信息。
支持指定文档名称检索最相似的文本信息。
支持文档名搭配文档元数据的标量字段的 Filter 表达式检索最相似的文本信息。
支持仅使用文档元数据的标量字段的 Filter 表达式检索最相似的文本信息。
查询文档详情
支持指定文档名称查询文档详情。
获取文档列表
支持指定具体的文档名称名查找文档,或搭配文档 Meta 信息对应字段的 Filter 表达式查询文档信息。
支持指定具体的 DocumentSet ID 查找文档,或搭配文档 Meta 信息对应字段的 Filter 表达式查询文档信息。
支持指定查询起始位置 offset 和返回数量 limit,查找指定范围的文档信息。
支持根据文档 Meta 信息对应字段 Filter 表达式,直接过滤需查找的文档。
查询文本块
Chunk 指语块,较长文本在处理时会切分为多个语块,以便于向量化和更高效地检索,多个 Chunk 组成一个 DocumentSet。
支持指定具体的文档名获取文档切分后的语块。
支持指定具体的 DocumentSet ID 获取文档切分后的语块。
更新文档
支持通过主键(DocumentSet ID)或文档名,搭配 Filter 表达式过滤需更新的文档。
支持新增字段,支持更改部分字段。新增字段,在创建 CollectionView 时没有为这些字段指定索引方式,那么新增这些字段时,系统不会自动为其创建索引。
删除文档
支持批量删除,文档 ID 或文档名数组元素数量最大为20。
支持使用 Filter 表达式过滤所需删除的所有文档。
前提条件
已 登录实例。
已 创建 AI 类数据库、创建集合视图。
文档导入
1. 在左侧库表栏,展开 AI 类数据库和集合视图。
2. 打开数据操作页面。
方式一:单击集合视图名称。
方式二:鼠标悬停至待操作集合视图名称处,在右侧单击
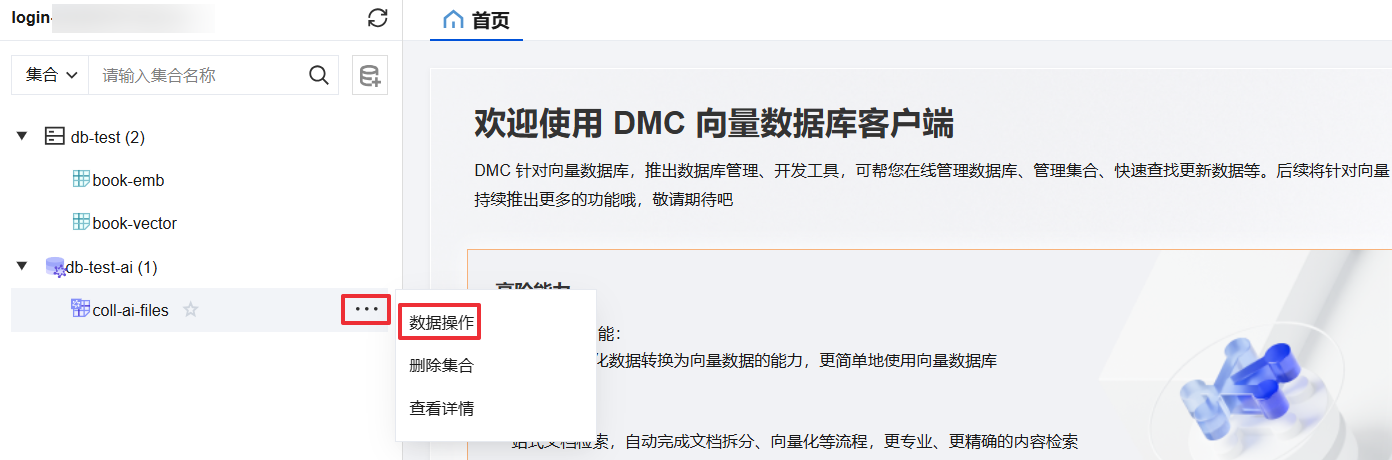
3. 选择文档导入页签。
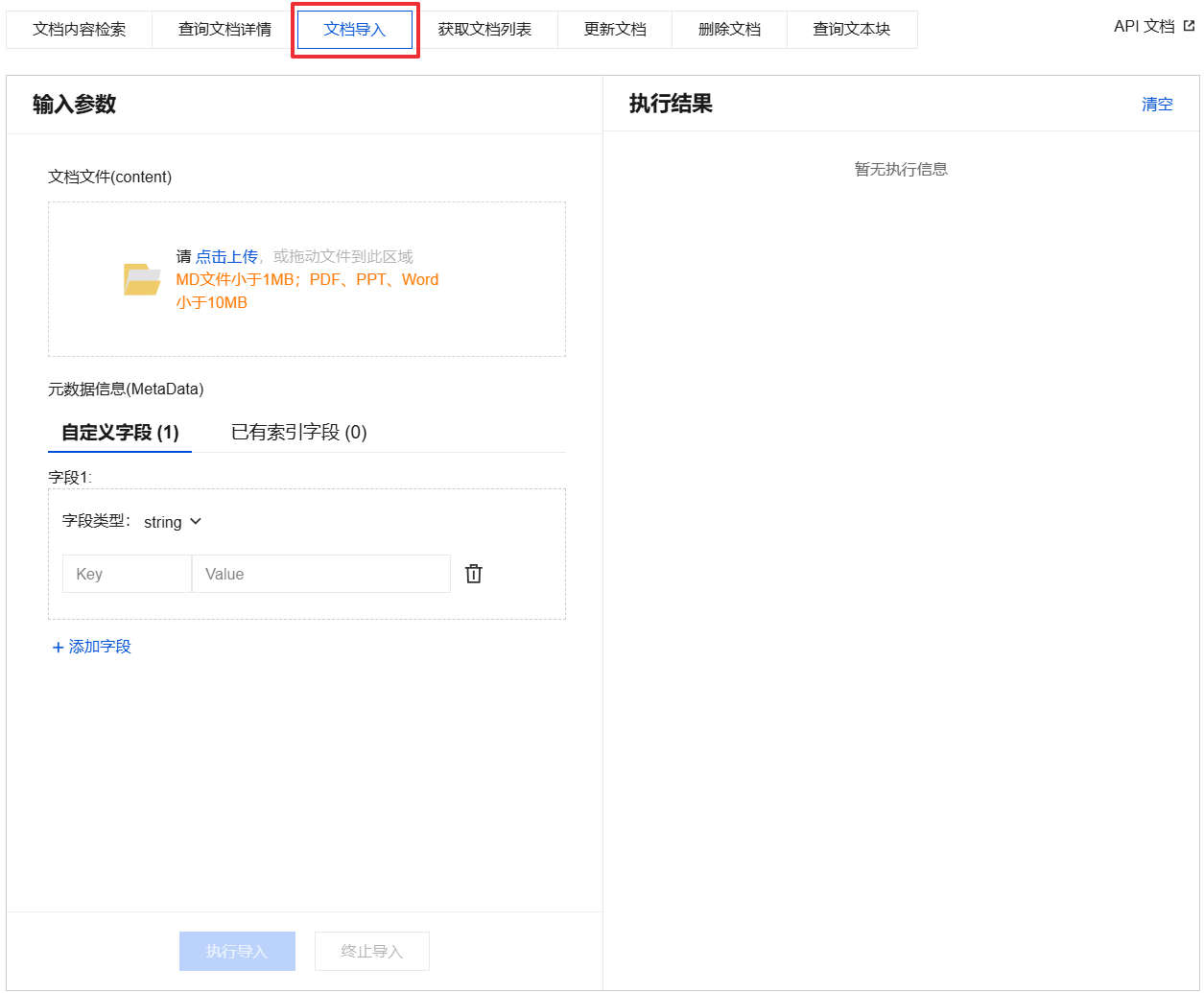
4. 单击点击上传或拖拽文档到文档文件区域。
说明:
一次仅允许上传一个文档。
支持上传文档大小小于1MB的 Markdown 的文档。
支持上传文档大小小于10MB的 PDF、PPT、Word 的文档。
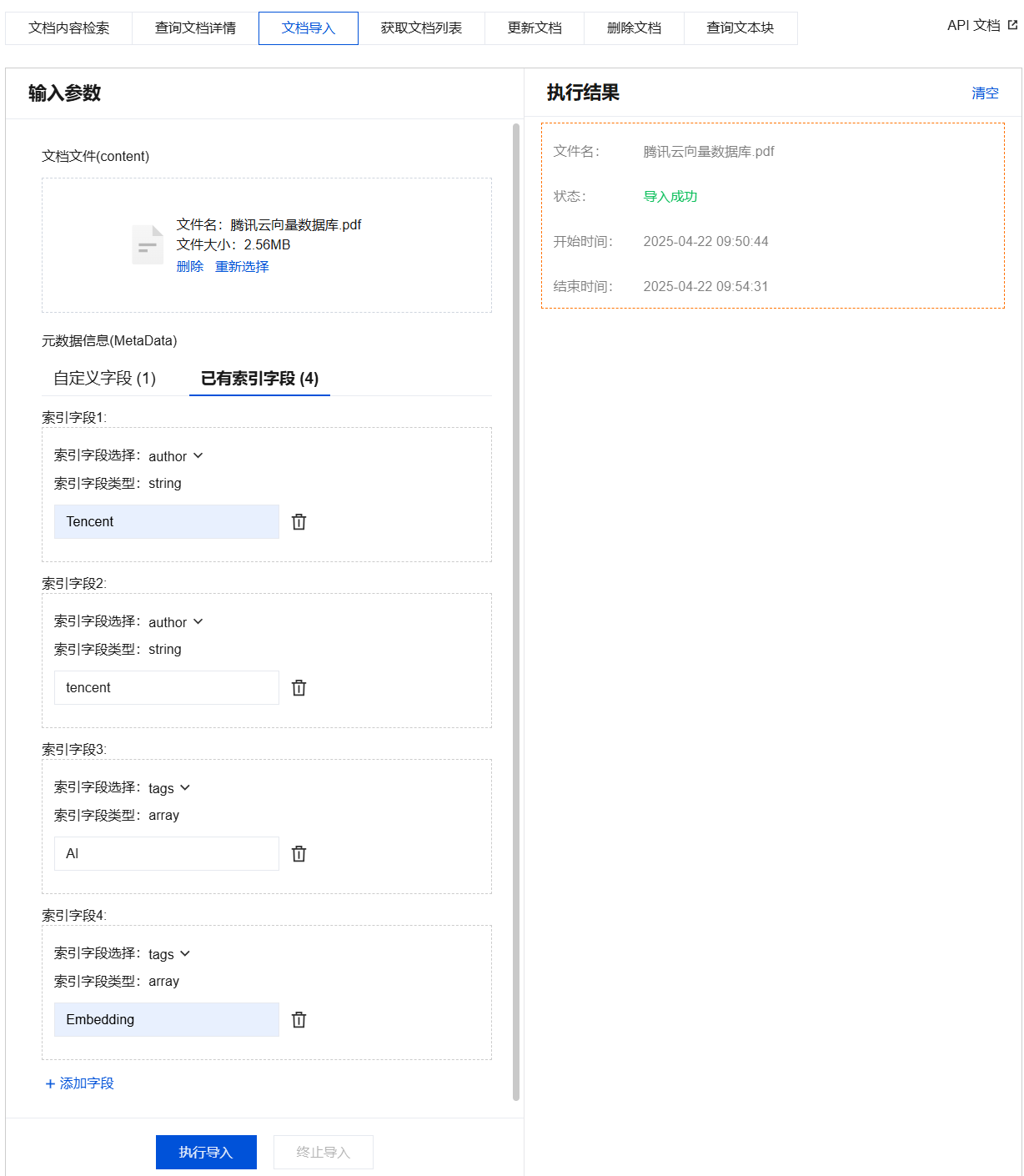
5. (可选)配置元数据信息(MetaData)。
自定义字段:新增标量字段,但新增字段不会构建 Filter 索引。
选择自定义字段页签,选择字段类型,并输入 Key、Value。若需要自定义多个字段,请单击添加字段。
可选字段类型:
string:字符型。
uint64:指无符号整数(unsigned integer)。
float:指浮点数(即带有小数点的数值)。
array:数组类型,数组元素为 string。
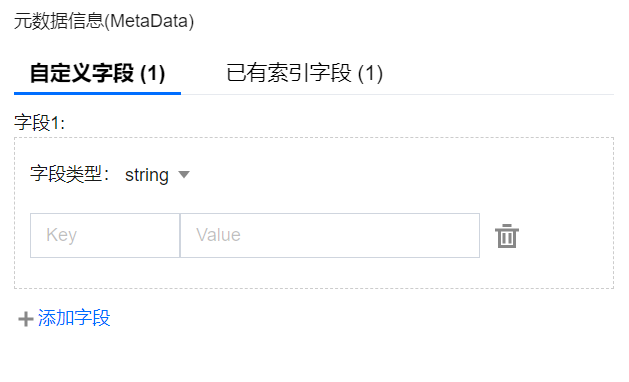
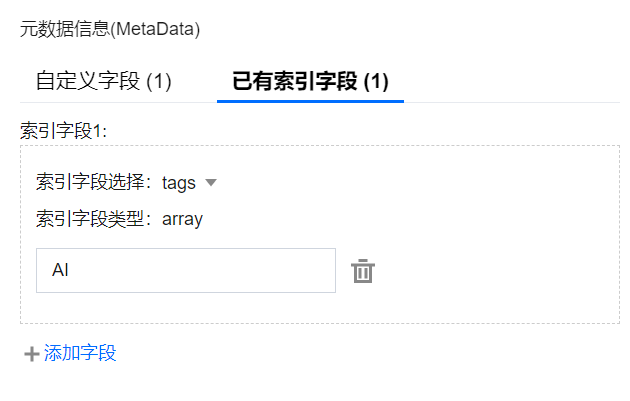
已有索引字段:可为创建集合视图时设置的 Filter 索引的字段赋值,以便在检索时,使用该字段的 Filter 表达式检索文档。
选择已有索引字段页签,单击添加字段,选择创建集合时已设置的索引字段和系统默认提供的索引字段(包括 documentSetName 和documentSetId),并为索引字段赋值。支持添加多个索引字段,但一个索引字段仅允许设置一个 Value。
6. 配置完成后,在输入参数下方单击执行导入。
在执行结果区域查看执行结果。
文档导入及执行结果示例
文档内容检索
1. 在左侧库表栏,展开 AI 类数据库和集合视图。
2. 打开数据操作页面。
方式一:单击集合视图名称。
方式二:鼠标悬停至待操作集合视图名称处,在右侧单击
3. 选择文档内容检索页签。
4. 配置输入参数。
输入方式:表单、JSON。
输入参数:参数字段说明如下表所示。
参数 | 子参数 | 是否必选 | 说明 |
database | - | 是 | 指定要查询的 Database 名称。 |
database | - | 是 | 指定需查询的 CollectionView 名称。 |
search (设置检索数据的条件) | content(查询内容) | 否 | 输入需检索的文本信息。 |
| documentSetName(指定文档查询) | 否 | 指定需检索的文档名称,支持批量查询。 表单:多个文档名称之间按 Enter 进行分隔。 JSON:数组元素范围[1,10]。 |
| filter(根据条件表达式查询) | 否 | 使用创建集合视图时指定的 Filter 索引的字段设置查询过滤表达式。
Filter 表达式格式为 <field_name><operator><value>,多个表达式之间支持 and(与)、or(或)、not(非)关系。具体信息,请参见 混合检索。其中: <field_name>:表示要过滤的字段名。 <operator>:表示要使用的运算符。 string :匹配单个字符串值(=)、排除单个字符串值(!=)、匹配任意一个字符串值(in)、排除所有字符串值(not in)。其对应的 Value 必须使用英文双引号括起来。 uint64:大于(>)、大于等于(>=)、等于(=)、小于(<)、小于等于(<=)。例如:expired_time > 1623388524。 array:数组类型,包含数组元素之一(include)、排除数组元素之一(exclude)、全包含数组元素(include all)。例如,name include (\\"Bob\\", \\"Jack\\")。 <value>:表示要匹配的值。 示例: Filter('author="jerry"').And('page>20') |
| limit(查询的数据条数) | 否 | 指定返回最相似的 Top K 的 K 的值。 默认值:10。 |
| options.chunkExpand(结果前后补充 chunk 数) | 否 | 以数组形式配置检索的目标信息所需向前扩展的段落数量以及向后扩展的段落数。例如,输入[2,3],指所检索到的 Chunk 返回时,同时返回其之前的2个段落与之后的3个段落。 段落指文档在上传存储时,自动向量化拆分的段落。 默认值:[1,1]。 |
5. 配置完成后,在输入参数下方单击执行。
在执行结果区域查看执行结果。
说明:
当输入方式选择表单,不输入任何参数,单击执行,可最多获取该集合视图内的前10条数据。
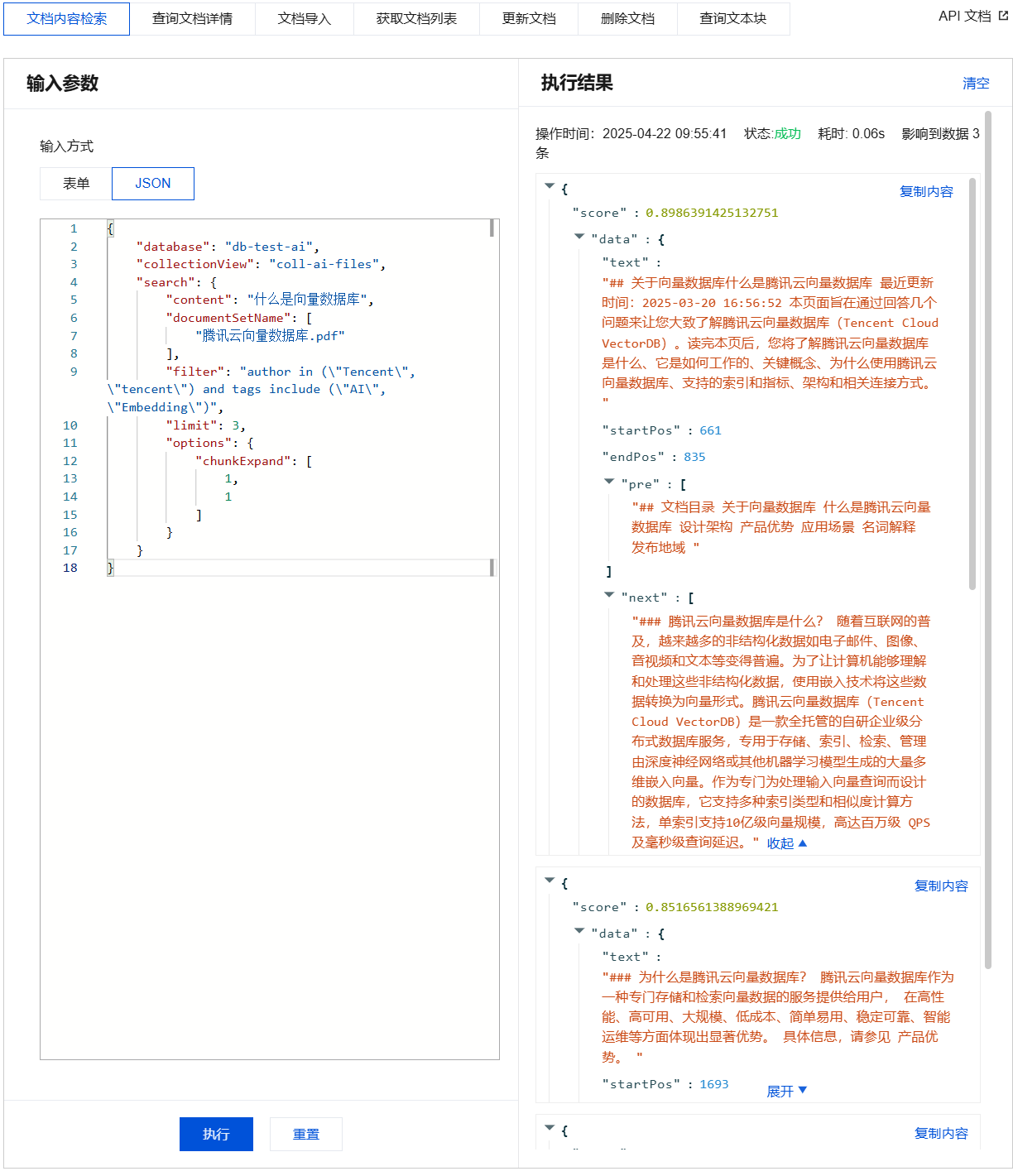
文档内容检索输入参数及执行结果示例
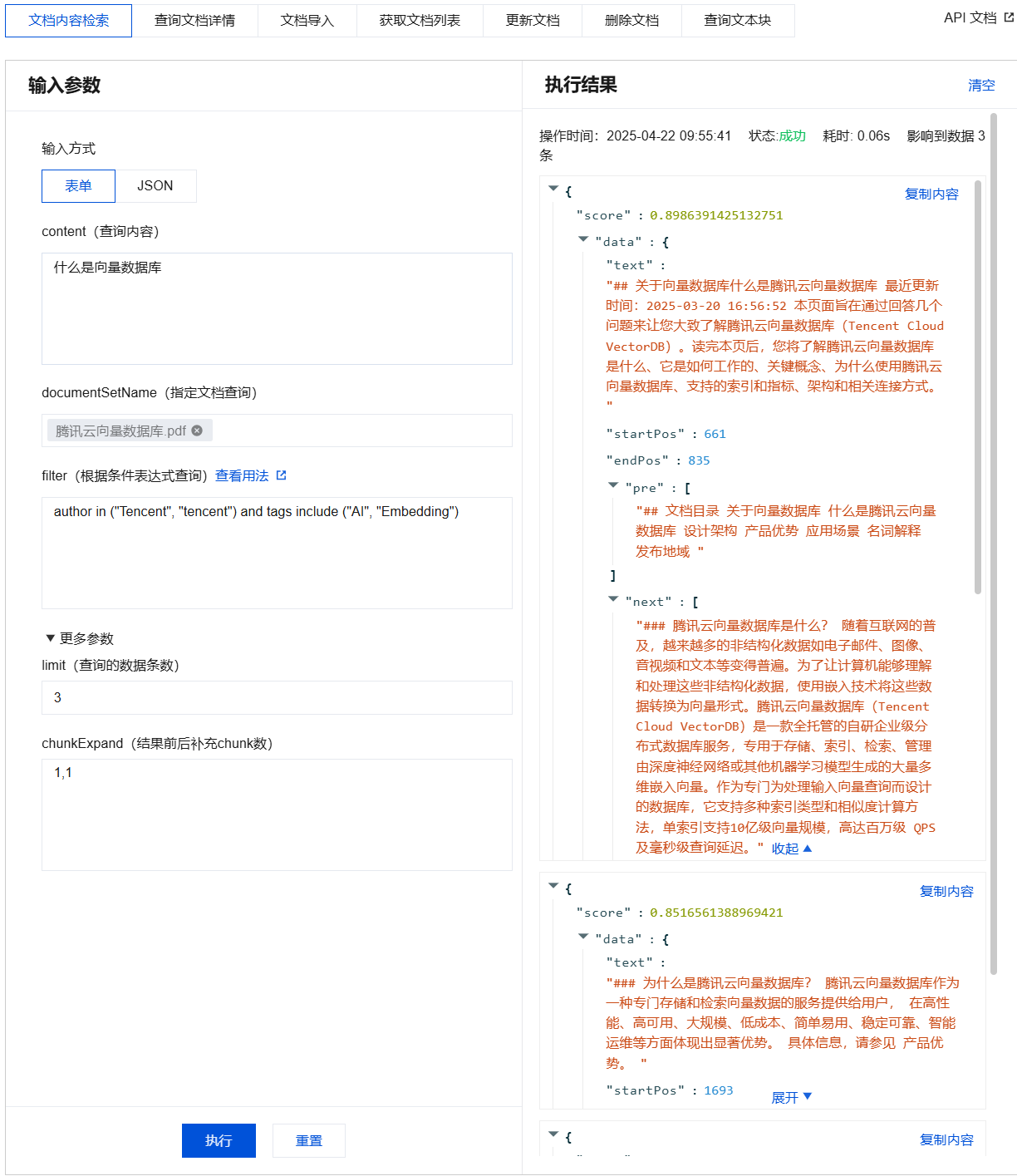
{"database": "db-test-ai","collectionView": "coll-ai-files","search": {"content": "什么是向量数据库","documentSetName": ["腾讯云向量数据库.pdf"],"filter": "author in (\\"Tencent\\", \\"tencent\\") and tags include (\\"AI\\", \\"Embedding\\")","limit": 3,"options": {"chunkExpand": [1,1]}}}
查询文档详情
1. 在左侧库表栏,展开 AI 类数据库和集合视图。
2. 打开数据操作页面。
方式一:单击集合视图名称。
方式二:鼠标悬停至待操作集合视图名称处,在右侧单击
3. 选择查询文档详情页签。
4. 配置输入参数。
输入方式:表单、JSON。
输入参数:参数字段说明如下表所示。
参数 | 是否必选 | 说明 |
database | 是 | 指定需查询的 Database 名称。 |
collectionView | 是 | 指定需查询的 CollectionView 名称 |
documentSetName(指定文档查询) | 是 | 指定需查询的文档名称。 |
5. 配置完成后,在输入参数下方单击执行。
在执行结果区域查看执行结果。
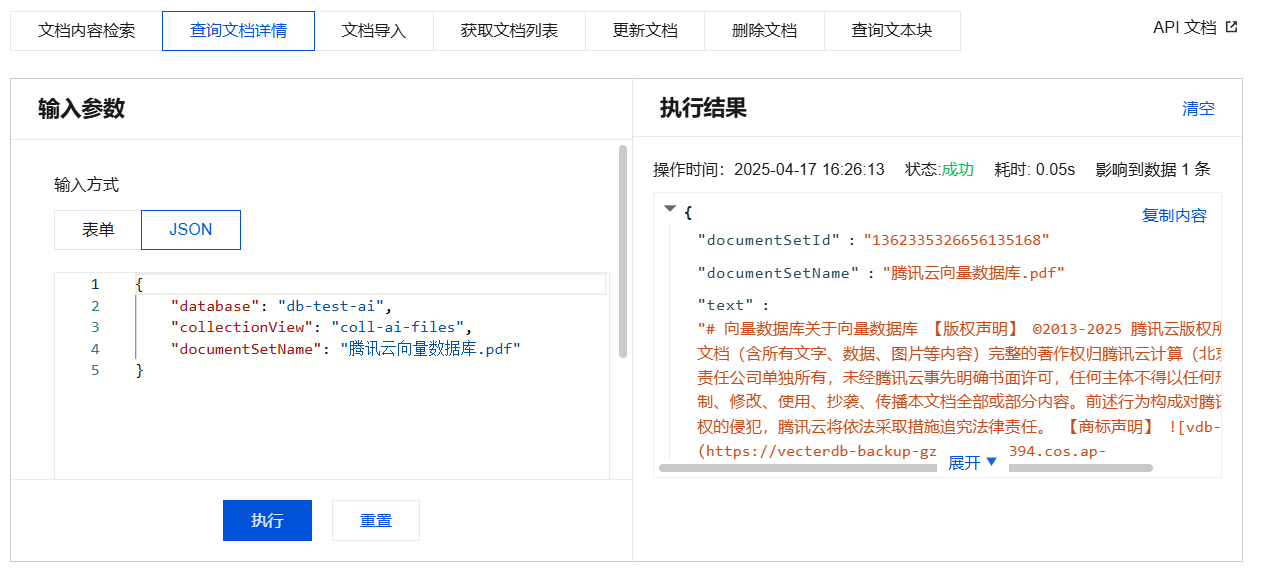
查询文档详情输入参数及执行结果示例
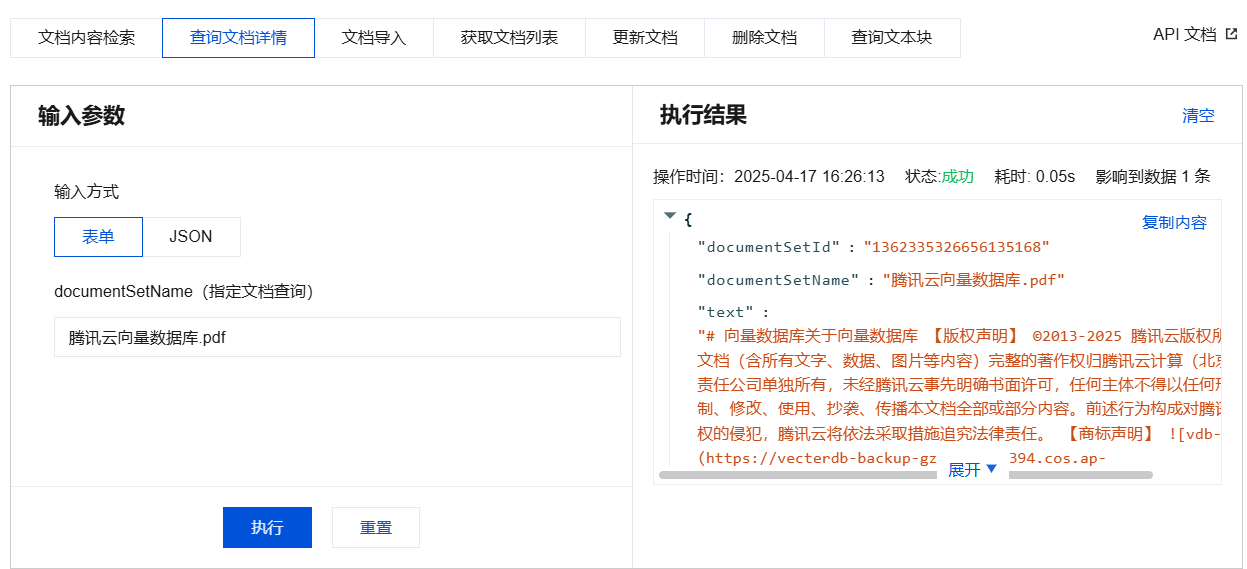
{"database": "db-test-ai","collectionView": "coll-ai-files","documentSetName": "腾讯云向量数据库.pdf"}
获取文档列表
1. 在左侧库表栏,展开 AI 类数据库和集合视图。
2. 打开数据操作页面。
方式一:单击集合视图名称。
方式二:鼠标悬停至待操作集合视图名称处,在右侧单击
3. 选择获取文档列表页签。
4. 配置输入参数。
输入方式:表单、JSON。
输入参数:参数字段说明如下表所示。
参数 | 子参数 | 是否必选 | 参数说明 |
database | - | 是 | 指定需查询的 Database 名称。 |
collectionView | - | 是 | 指定需查询的 CollectionView 名称 |
query(设置查询条件) | documentSetName(指定文档查询) | 否 | 指定需查询的文档名称,支持批量查询。 表单:多个文档名称之间用英文逗号(,)分隔。 JSON:数组元素范围[1,20]。 |
| documentSetId(指定文档ID查询) | 否 | 指定需查询的文档的 ID,支持批量查询,数组元素范围[1,20]。 表单:多个文档 ID 之间按 Enter 进行分隔。 JSON:数组元素范围[1,20]。 |
| filter(根据条件表达式查询) | 否 | 使用创建 CollectionView 指定的 Filter 索引的字段设置查询过滤表达式。 <field_name>:表示要过滤的字段名。 <operator>:表示要使用的运算符。 string :匹配单个字符串值(=)、排除单个字符串值(!=)、匹配任意一个字符串值(in)、排除所有字符串值(not in)。其对应的 Value 必须使用英文双引号括起来。 uint64:大于(>)、大于等于(>=)、等于(=)、小于(<)、小于等于(<=)。例如:expired_time > 1623388524。 array:数组类型,包含数组元素之一(include)、排除数组元素之一(exclude)、全包含数组元素(include all)。例如,name include (\\"Bob\\", \\"Jack\\")。 <value>:表示要匹配的值。 示例: Filter('author="jerry"').And('page>20') |
| limit(查询的数据条数) | 否 | 每页返回的 DocumentSet 数量。 数据类型:uint 64。 默认值:10。 取值范围:[1,16384] 注意: 若不配置任何查询条件,即 doc_list = coll_view.query(),则默认返回 10个 DocumentSet。 若查询条件仅配置 Filter 表达式,不配置 limit,则默认返回10条 DocumentSet。 若查询条件仅设置 documentSetName 或 documentSetId,则可不配置 limit 参数,默认返回10条数据。 |
| offset(查询的数据偏移量) | 否 | 设置分页偏移量,用于控制分页查询返回结果的起始位置,方便用户对数据进行分页展示和浏览。 取值:为 limit 整数倍。 计算公式:offset=limit*(page-1)。 例如:当 limit = 10,page = 2 时,分页偏移量 offset = 10 * (2 - 1) = 10,表示从查询结果的第11条记录开始返回数据。 |
| outputFields(指定输出字段) | 否 | 以数组形式配置需返回的字段。 |
5. 配置完成后,在输入参数下方单击执行。
在执行结果区域查看执行结果。
说明:
当输入方式选择表单,不输入任何参数,单击执行,可最多获取该集合视图内的前10条数据。
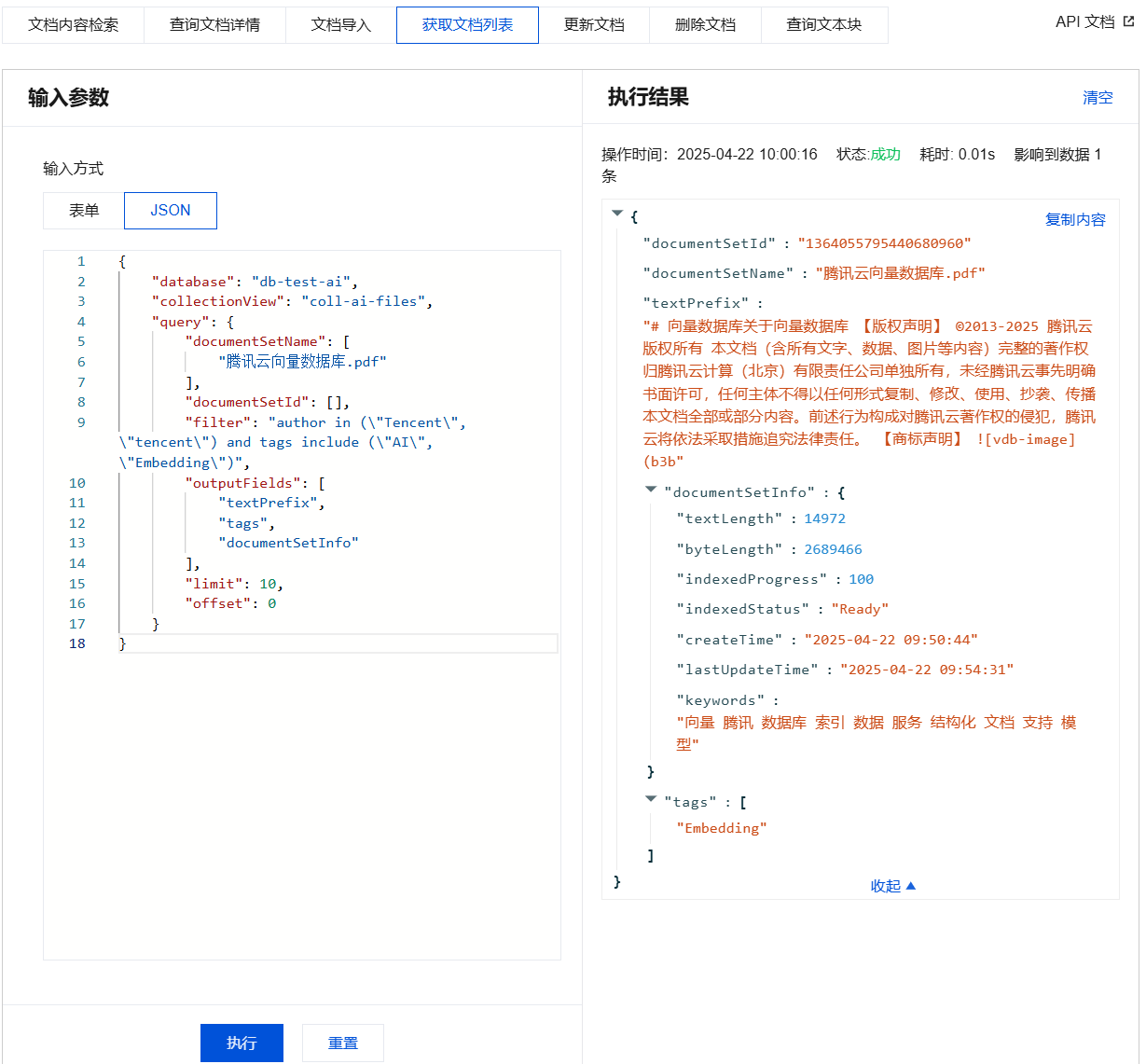
获取文档列表输入参数及执行结果示例
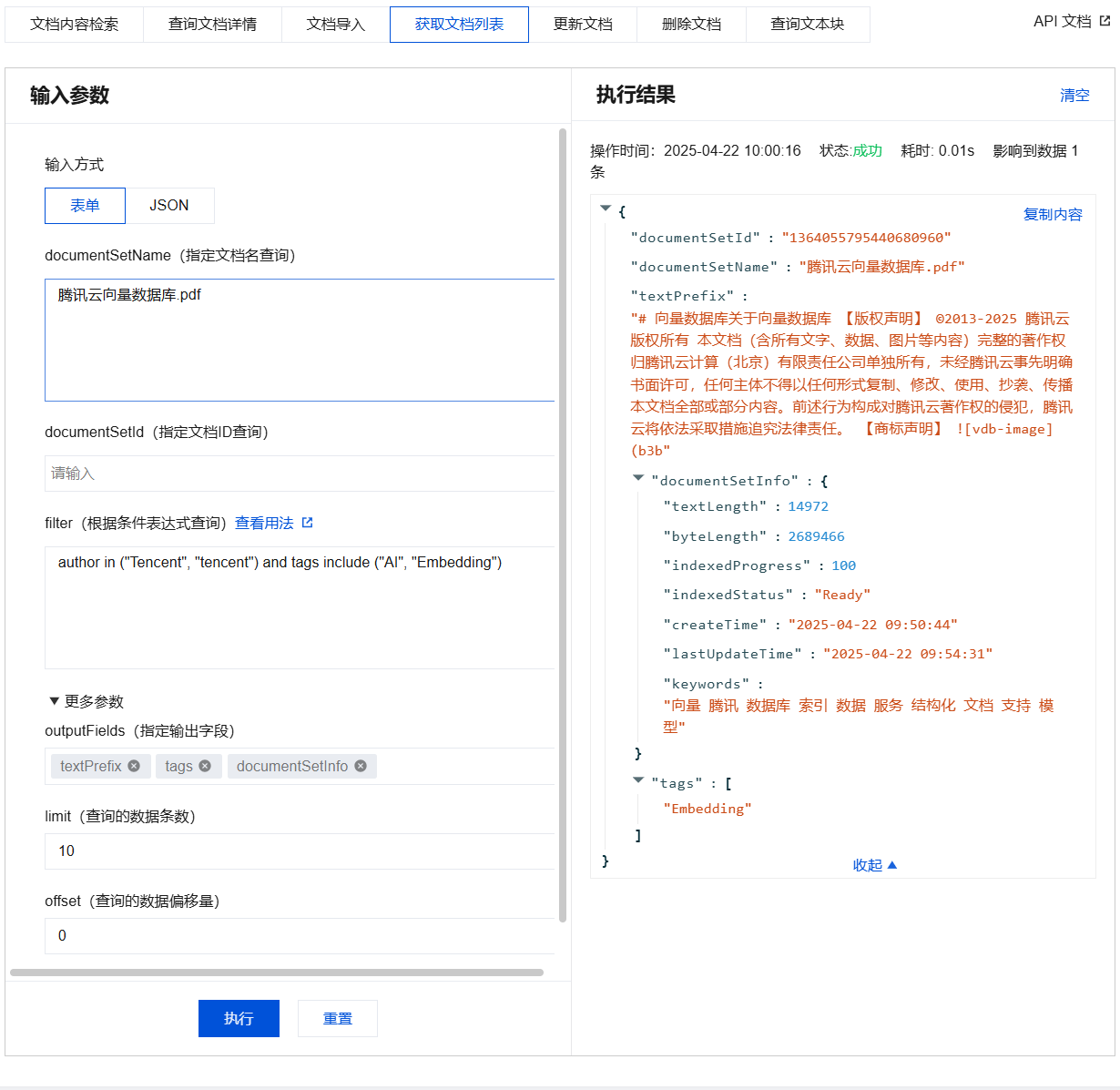
{"database": "db-test-ai","collectionView": "coll-ai-files","query": {"documentSetName": ["腾讯云向量数据库.pdf"],"documentSetId": [],"filter": "author in (\\"Tencent\\", \\"tencent\\") and tags include (\\"AI\\", \\"Embedding\\")","outputFields": ["textPrefix","tags","documentSetInfo"],"limit": 10,"offset": 0}}
查询文本块
1. 在左侧库表栏,展开 AI 类数据库和集合视图。
2. 打开数据操作页面。
方式一:单击集合视图名称。
方式二:鼠标悬停至待操作集合视图名称处,在右侧单击
3. 选择查询文本块页签。
4. 配置输入参数。
输入方式:表单、JSON。
输入参数:参数字段说明如下表所示。
参数名 | 是否必选 | 说明 |
database | 是 | 指定需查询文本块的 Database 名称。 |
collectionView | 是 | 指定需查询文本块的 Collection 名称。 |
documentSetName(指定文档查询) | 否 | 指定需查询的文档名称。 |
documentSetId(指定文档ID查询) | 否 | 指定需查询的文档 ID。 说明: documentSetId 与 documentSetName 必须指定其中一个,以指定查询的文档。 |
limit(查询的数据条数) | 否 | 每页返回的 Chunks 数量。 数据类型:uint 64。 默认值:10。 取值范围:[1,16384]。 |
offset(查询的数据偏移量) | 否 | 设置分页偏移量,用于控制分页查询返回结果的起始位置,方便用户对数据进行分页展示和浏览。 取值:为 limit 整数倍。 计算公式:offset=limit*(page-1)。 示例:当 limit = 10,page = 2 时,分页偏移量 offset = 10 * (2 - 1) = 10,表示从查询结果的第11条记录开始返回数据。 |
5. 配置完成后,在输入参数下方单击执行。
在执行结果区域查看执行结果。
说明
当输入方式选择表单,不输入任何参数,单击执行,可最多获取该集合视图内的前10条数据。
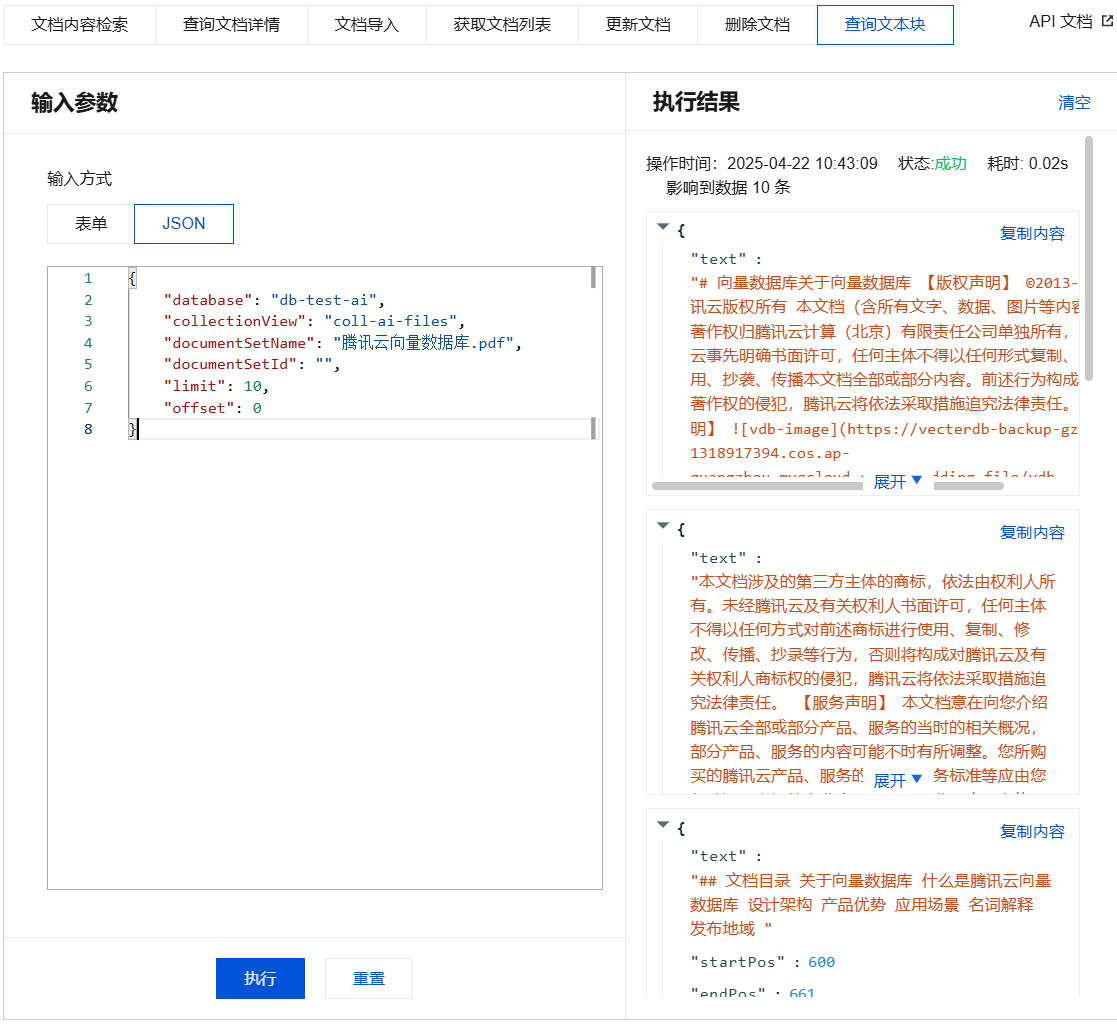
查询文本块输入参数及执行结果示例
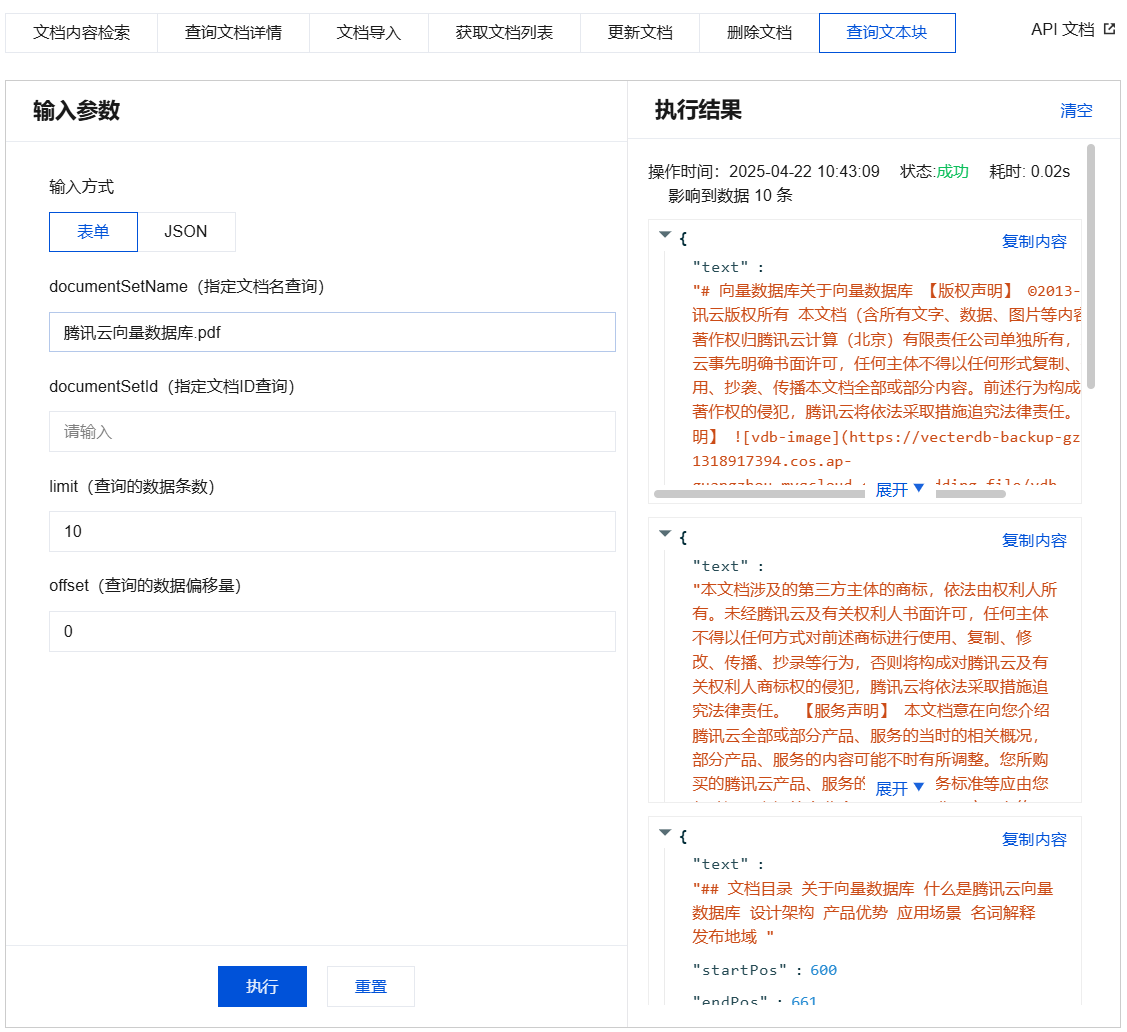
{"database": "db-test-ai","collectionView": "coll-ai-files","documentSetName": "腾讯云向量数据库.pdf","documentSetId": "","limit": 10,"offset": 0}
更新文档
注意:
不能变更系统分配的 DocumentSet ID 字段,不要求事务完整性。
不能变更已上传的文档内容。
1. 在左侧库表栏,展开 AI 类数据库和集合视图。
2. 打开数据操作页面。
方式一:单击集合视图名称。
方式二:鼠标悬停至待操作集合视图名称处,在右侧单击
3. 选择更新文档页签。
4. 配置输入参数。
输入方式:仅支持 JSON。
输入参数:参数字段说明如下表所示。
参数名称 | 子参数 | 是否必选 | 说明 |
database | - | 是 | 指定需更文档的 Database 名称。 |
collectionView | - | 是 | 指定需更新文档的 Collection 名称。 |
query (设置查询条件检索需更新的文档) | documentSetName | 否 | 指定需更新的 DocumentSet 的文档名称,可以批量更新,数据元素最大值为20。 说明: 同时配置 documentSetName 与 filter 参数,更新数据将会取二者的并集。 |
| filter | 否 | 使用创建 CollectionView 指定的 Filter 索引的字段设置查询过滤表达式。 <field_name>:表示要过滤的字段名。 <operator>:表示要使用的运算符。 string :匹配单个字符串值(=)、排除单个字符串值(!=)、匹配任意一个字符串值(in)、排除所有字符串值(not in)。其对应的 Value 必须使用英文双引号括起来。 uint64:大于(>)、大于等于(>=)、等于(=)、小于(<)、小于等于(<=)。例如:expired_time > 1623388524。 array:数组类型,包含数组元素之一(include)、排除数组元素之一(exclude)、全包含数组元素(include all)。例如,name include (\\"Bob\\", \\"Jack\\")。 <value>:表示要匹配的值。 示例: Filter('author="jerry"').And('page>20') |
update (设置需更新的字段) | old_field | 否 | 当前已存在的字段,更新字段对应的数据。 类型:string 字符长度要求:[1,256]。 |
| new_field | 否 | 新增字段,并给新字段赋值。 类型:string。 字符长度要求:[1,256]。 |
5. 配置完成后,在输入参数下方单击执行。
在执行结果区域查看执行结果。
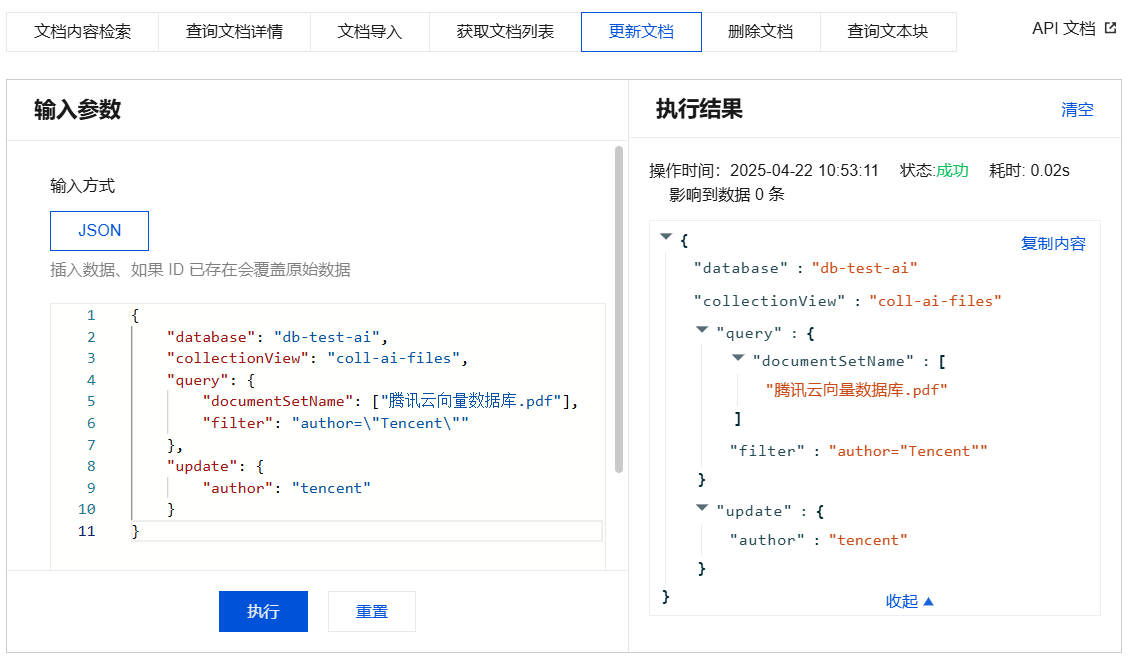
更新文档输入参数及执行结果示例
{"database": "db-test-ai","collectionView": "coll-ai-files","query": {"documentSetName": ["腾讯云向量数据库.pdf"],"filter": "author=\\"Tencent\\""},"update": {"author": "tencent"}}
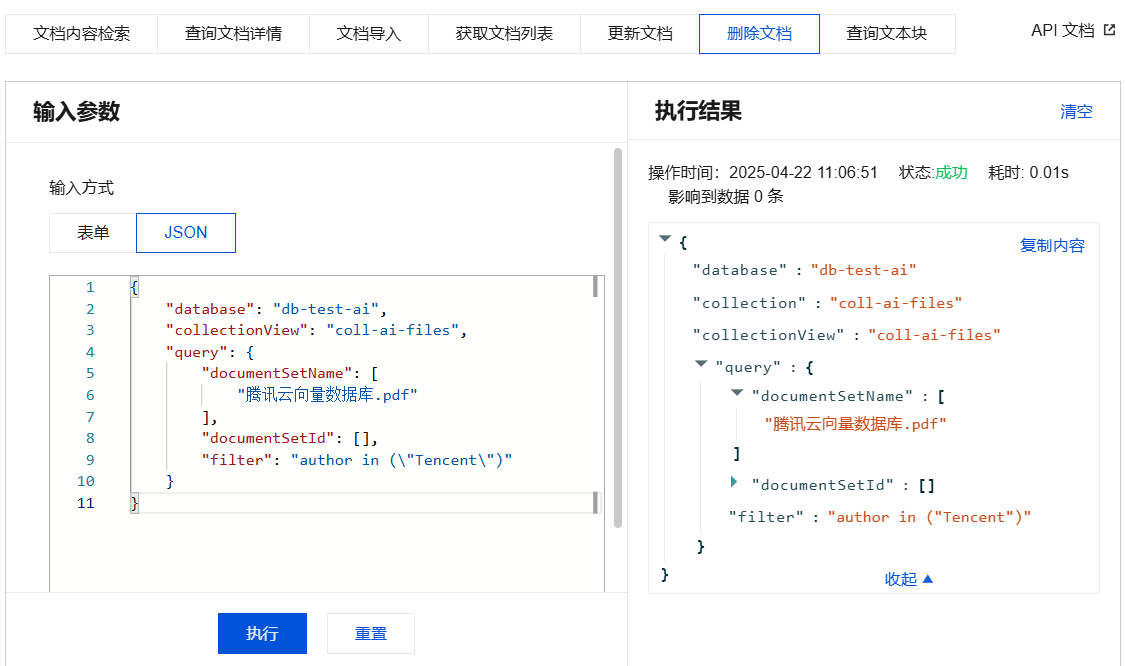
删除文档
1. 在左侧库表栏,展开 AI 类数据库和集合视图。
2. 打开数据操作页面。
方式一:单击集合视图名称。
方式二:鼠标悬停至待操作集合视图名称处,在右侧单击
3. 选择删除文档页签。
4. 配置输入参数。
输入方式:表单、JSON。
输入参数:参数字段说明如下表所示。
参数名称 | 子参数 | 是否必选 | 说明 |
database | - | 是 | 指定需删除文档的 Database 名称。 |
collectionView | - | 是 | 指定需删除文档的 CollectionView 名称。 |
query | documentSetName(指定文档名查询) | 否 | 指定需删除的文档名称。 说明: 同时配置 documentSetName 与 filter 参数,删除数据将会取二者的并集。 |
| documentSetId(指定文档 ID 查询) | 否 | 指定需删除的文档 ID,可以批量删除,数据元素最大值为20。 说明: 同时配置 documentSetId 与 filter 参数,删除数据将会取二者的并集。 |
| filter(根据条件表达式查询) | 否 | 使用创建 CollectionView 指定的 Filter 索引的字段设置查询过滤表达式。 <field_name>:表示要过滤的字段名。 <operator>:表示要使用的运算符。 string :匹配单个字符串值(=)、排除单个字符串值(!=)、匹配任意一个字符串值(in)、排除所有字符串值(not in)。其对应的 Value 必须使用英文双引号括起来。 uint64:大于(>)、大于等于(>=)、等于(=)、小于(<)、小于等于(<=)。例如:expired_time > 1623388524。 array:数组类型,包含数组元素之一(include)、排除数组元素之一(exclude)、全包含数组元素(include all)。例如,name include (\\"Bob\\", \\"Jack\\")。 <value>:表示要匹配的值。 示例: Filter('author="jerry"').And('page>20') |
5. 配置完成后,在输入参数下方单击执行。
在执行结果区域查看执行结果。
删除文档输入参数及执行结果示例
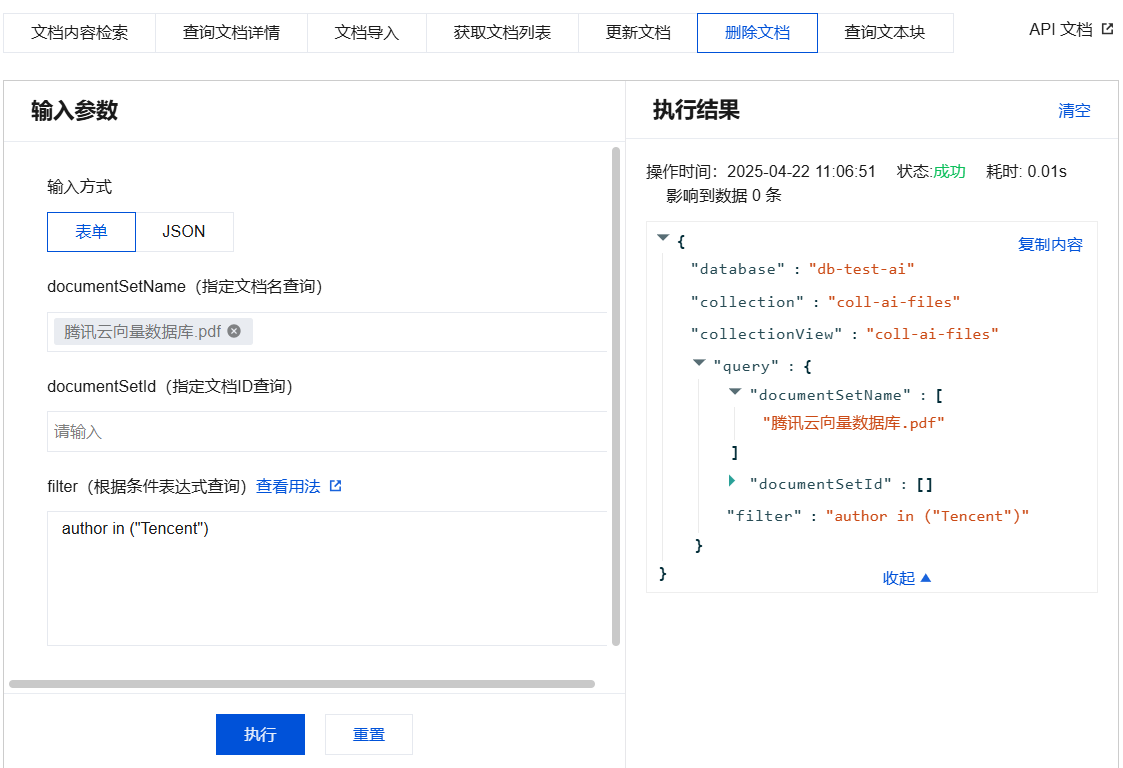
{"database": "db-test-ai","collectionView": "coll-ai-files","query": {"documentSetName": ["腾讯云向量数据库.pdf"],"documentSetId": [],"filter": "author in (\\"Tencent\\")"}}