普通数据库下集合的数据操作支持精确查询、相似度检索、插入/替换数据、更新数据和删除数据。
精确查询
基于数据的标量字段(指一个单独的数值,例如文本、数值或日期等字段),精确检索具体数据的查询方式。例如,根据 id(Document ID)查询对应向量数据,或者根据文件名查询。适用于根据单个属性进行数据查询的场景。具体支持如下功能。
支持按文件ID或文件名精确查询(单次最多20个)。
支持指定标量字段的 Filter 条件表达式过滤文件信息。
支持指定查询起始位置和返回数量,查询该范围的文件。
支持指定多个文件 id(DocumentSet ID)或文件名,并搭配标量字段的 Filter 表达式一起过滤数据。
相似度检索
基于多维向量进行 相似性计算的检索方式,通过计算查询向量与数据库存储的向量之间的相似度,找到与查询的多维向量最相似的文档。具体支持如下功能。
支持指定多维向量数值,检索与指定的多维向量数值最相似的 Top K 条文档。
支持指定 id(Document ID),检索与该 id 的向量值最相似的 Top K 条文档。
支持输入原始文本,检索与该文本信息最相似的 Top K 条文档。
支持指定 id、多维向量或原始文本,搭配标量字段的 Filter 表达式一并检索与 id、多维向量、原始文本相似的文档。
支持批量进行相似度检索,即支持输入多条向量数据值、多个 id 分别检索与每一个向量数值、每一个 id 相似的 Top K 条数据。
混合检索
支持稠密向量 Dense vector + 稀疏向量 Sparse vector 混合检索双路召回。Sparse vector 通过BM25算法完成分数计算达到类关键字检索效果,进一步提升业务召回效果,弥补在语义检索中对具体数字、编码、数学公式等不敏感以及语义过度泛化的问题。具体支持如下功能。
支持文本内容转化稀疏向量表示。
支持 RFF、Weight 两路权重合并排序。
插入/替换数据
用于给创建集合中插入向量数据。如果创建集合时,已开启 Embedding 并配置参数,则仅需要插入文本信息,Embedding 服务会自动将文本信息转换为向量数据,存入数据库。
更新数据
用于对通过主键(Document ID)与 Filter 表达式过滤检索 Document ,对 Document 的部分字段进行更新。同时,支持新增字段。
删除数据
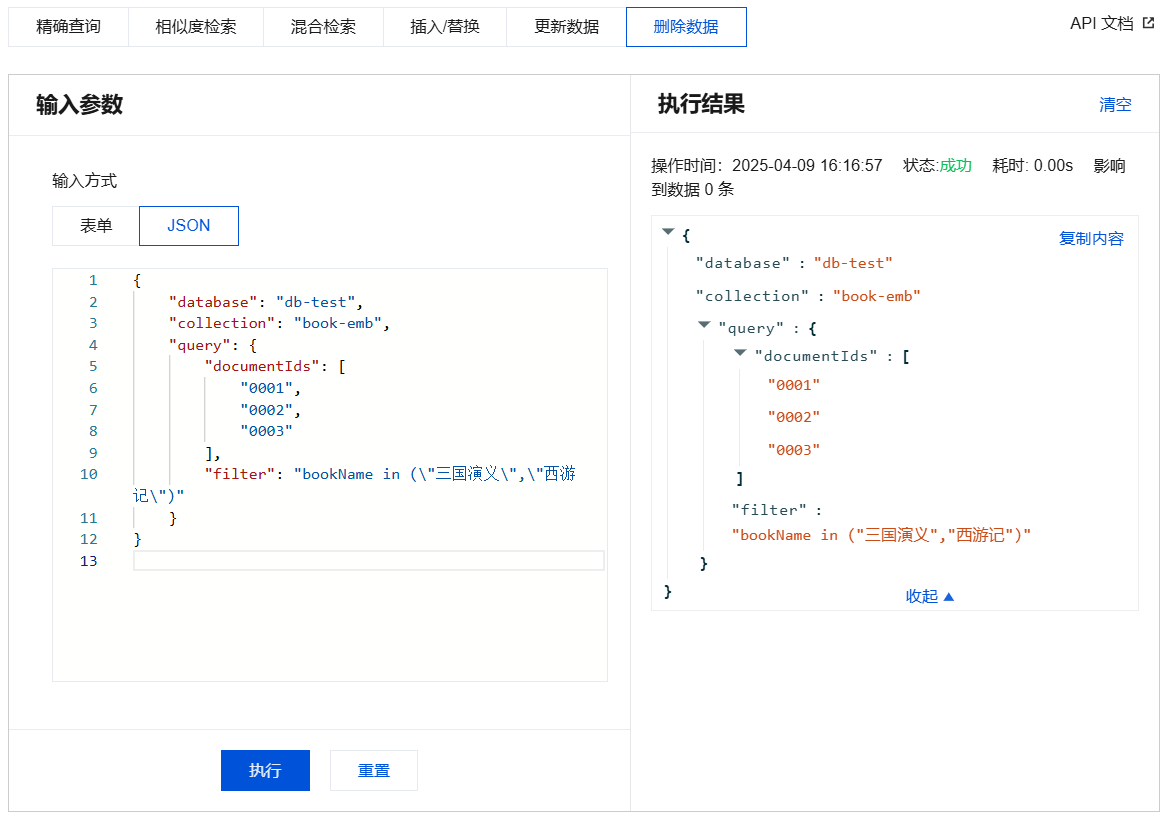
用于删除指定 id(Document ID)的文档,且支持设置 Filter 表达式,删除满足 Filter 表达式的数据。
前提条件
已 登录实例。
插入/替换数据
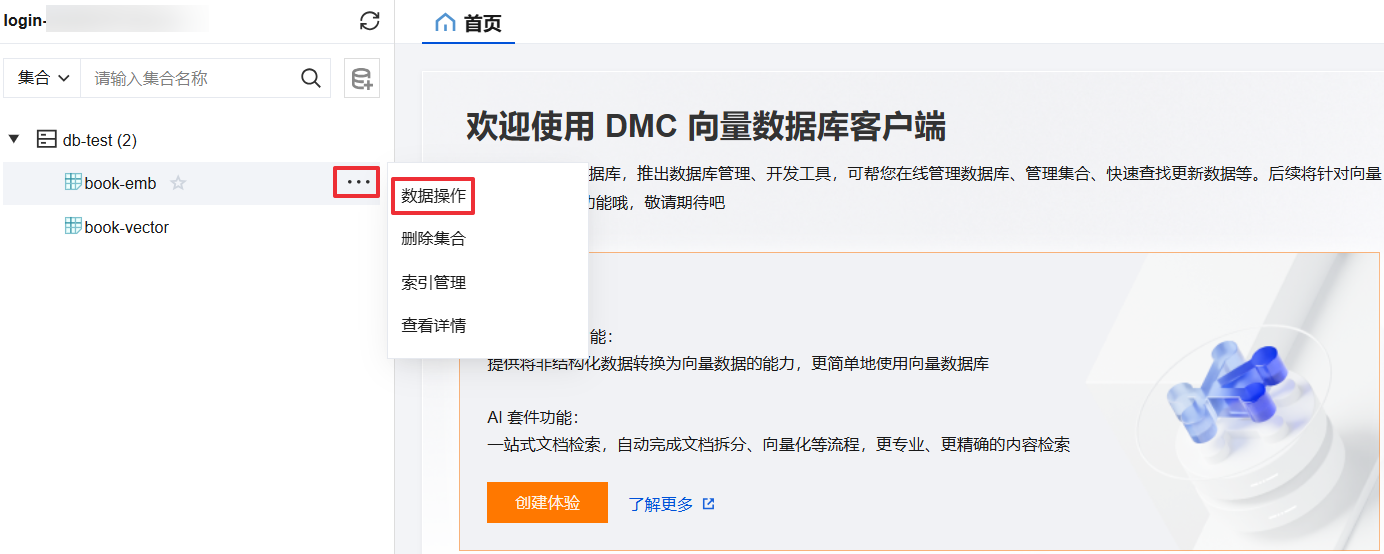
1. 在左侧库表栏,展开数据库和集合。
2. 打开数据操作页面。
方式一:单击集合名称。
方式二:鼠标悬停至待操作集合名称处,在右侧单击
3. 选择插入/替换页签。
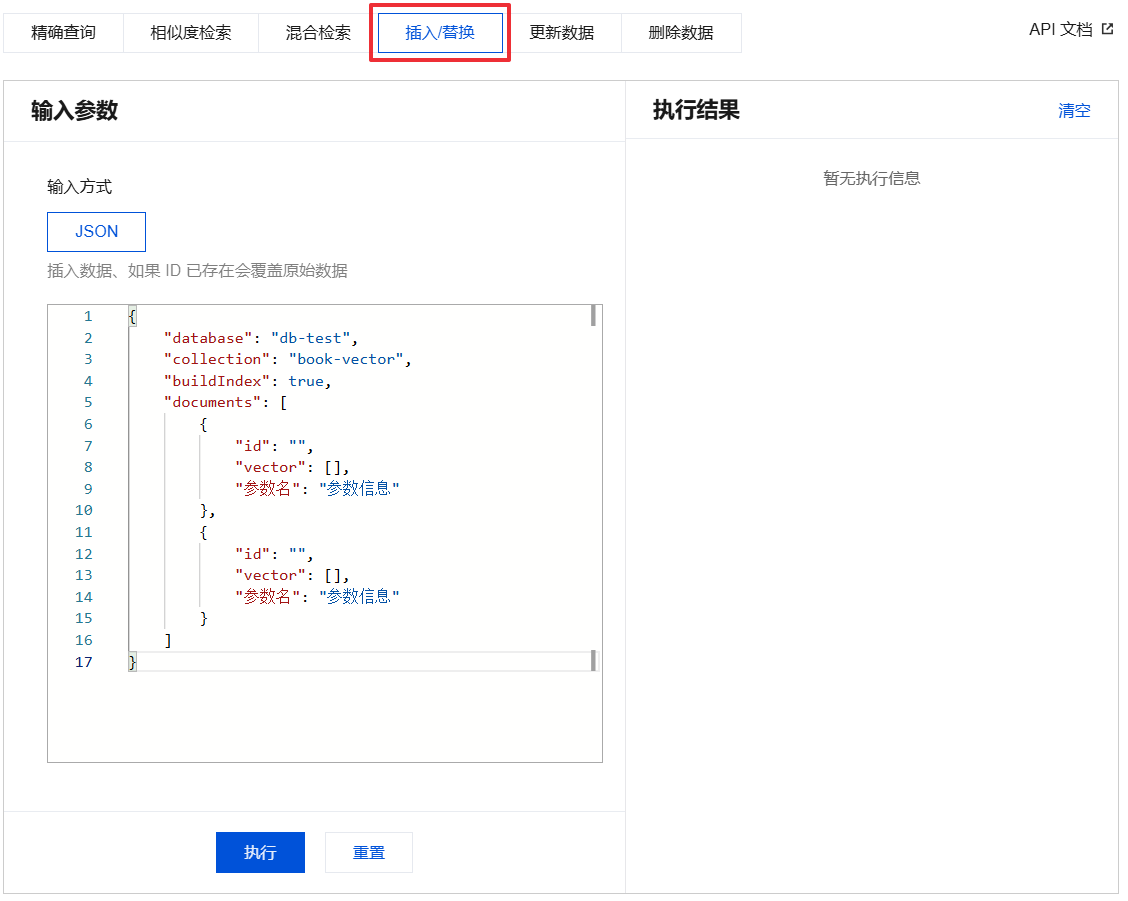
4. 配置输入参数。
输入方式:仅支持 JSON。
输入参数:参数说明如下表所示。
字段名 | 参数含义 | 子参数 | 是否必选 | 配置方法及要求 |
buildIndex
| 指定是否需要重新创建索引。 | - | 否 | 取值如下所示: true:重新创建索引。默认值是 true。 false:不重新创建索引。 |
documents | 指定要插入的 Document 数据,是一个数组,支持单次插入一条或者多条 Document,最大可插入 1000 条。 | id | 是 | Document 主键,长度限制为[1,128]。 |
| | vector | 否 | 表示文档的向量值,请务必使用32位浮点数存储向量数据。 |
| | 原始文本字段名 | 否 | 说明: 写入原始文本数据,系统会自动从该字段中提取原始文本信息,并将其转换为向量数据,并将原始文本以及转化后的向量数据一起存储在数据库中。 |
| | other_scalar_field | 否 | 其他标量字段,用于存储文档的其他信息。例如:请求示例中的 bookName、author、page。 |
5. 配置完成后,在输入参数下方单击执行。
在执行结果区域查看执行结果。
说明:
若需要重新输入 JSON 语句,请在下方单击重置后重新输入 JSON 语句。
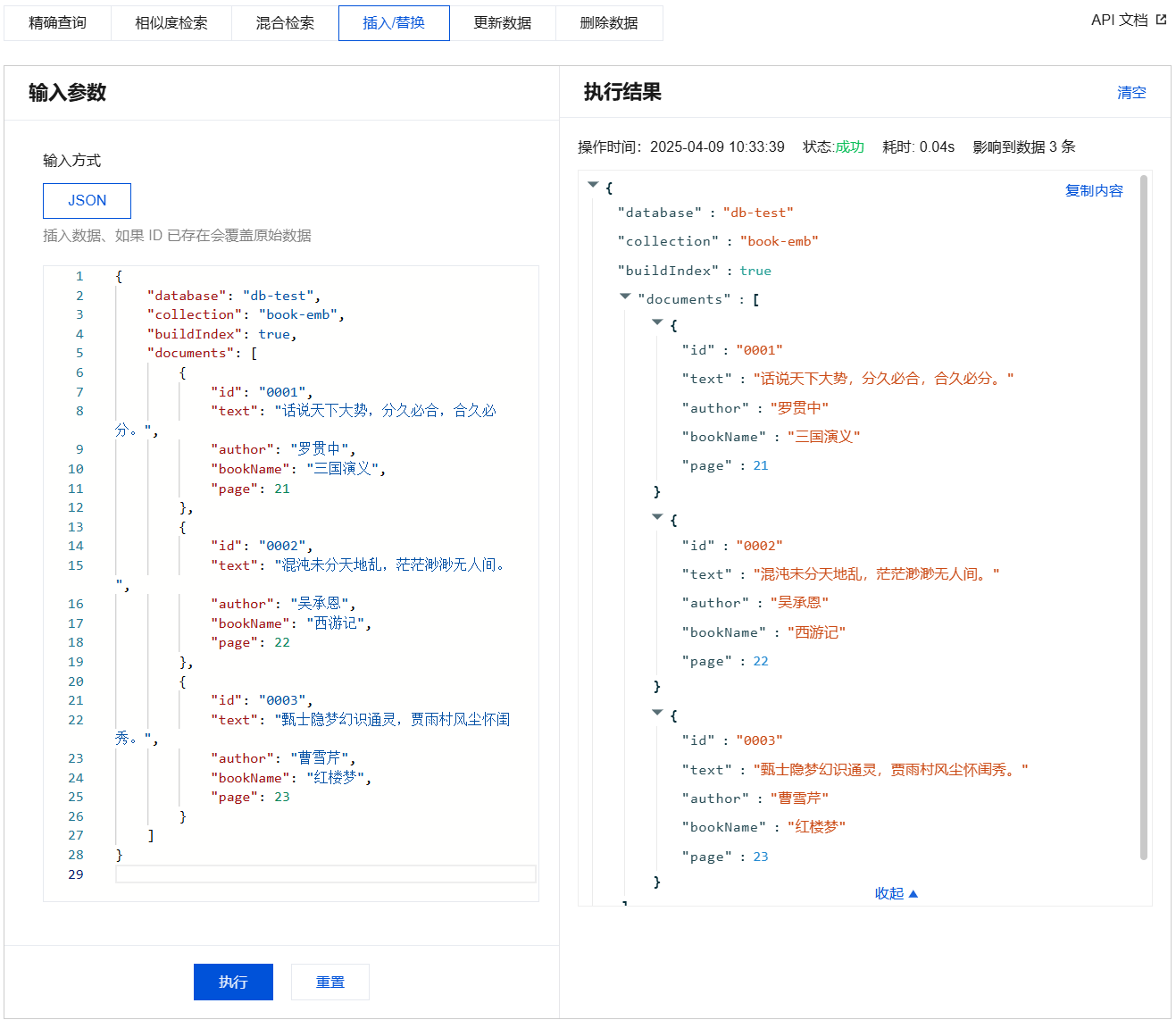
插入/替换数据输入参数及执行结果示例
{"database": "db-test","collection": "book-vector","buildIndex": true,"documents": [{"id": "0001","vector": [0.2123,0.23,0.213],"author": "罗贯中","bookName": "三国演义","page": 21},{"id": "0002","vector": [0.2123,0.22,0.213],"author": "吴承恩","bookName": "西游记","page": 22},{"id": "0003","vector": [0.2123,0.21,0.213],"author": "曹雪芹","bookName": "红楼梦","page": 23}]}

{"database": "db-test","collection": "book-emb","buildIndex": true,"documents": [{"id": "0001","text": "话说天下大势,分久必合,合久必分。","author": "罗贯中","bookName": "三国演义","page": 21},{"id": "0002","text": "混沌未分天地乱,茫茫渺渺无人间。","author": "吴承恩","bookName": "西游记","page": 22},{"id": "0003","text": "甄士隐梦幻识通灵,贾雨村风尘怀闺秀。","author": "曹雪芹","bookName": "红楼梦","page": 23}]}
精确查询
1. 在左侧库表栏,展开数据库和集合。
2. 打开数据操作页面。
方式一:单击集合名称。
方式二:鼠标悬停至待操作集合,在右侧单击
3. 选择精确查询页签。
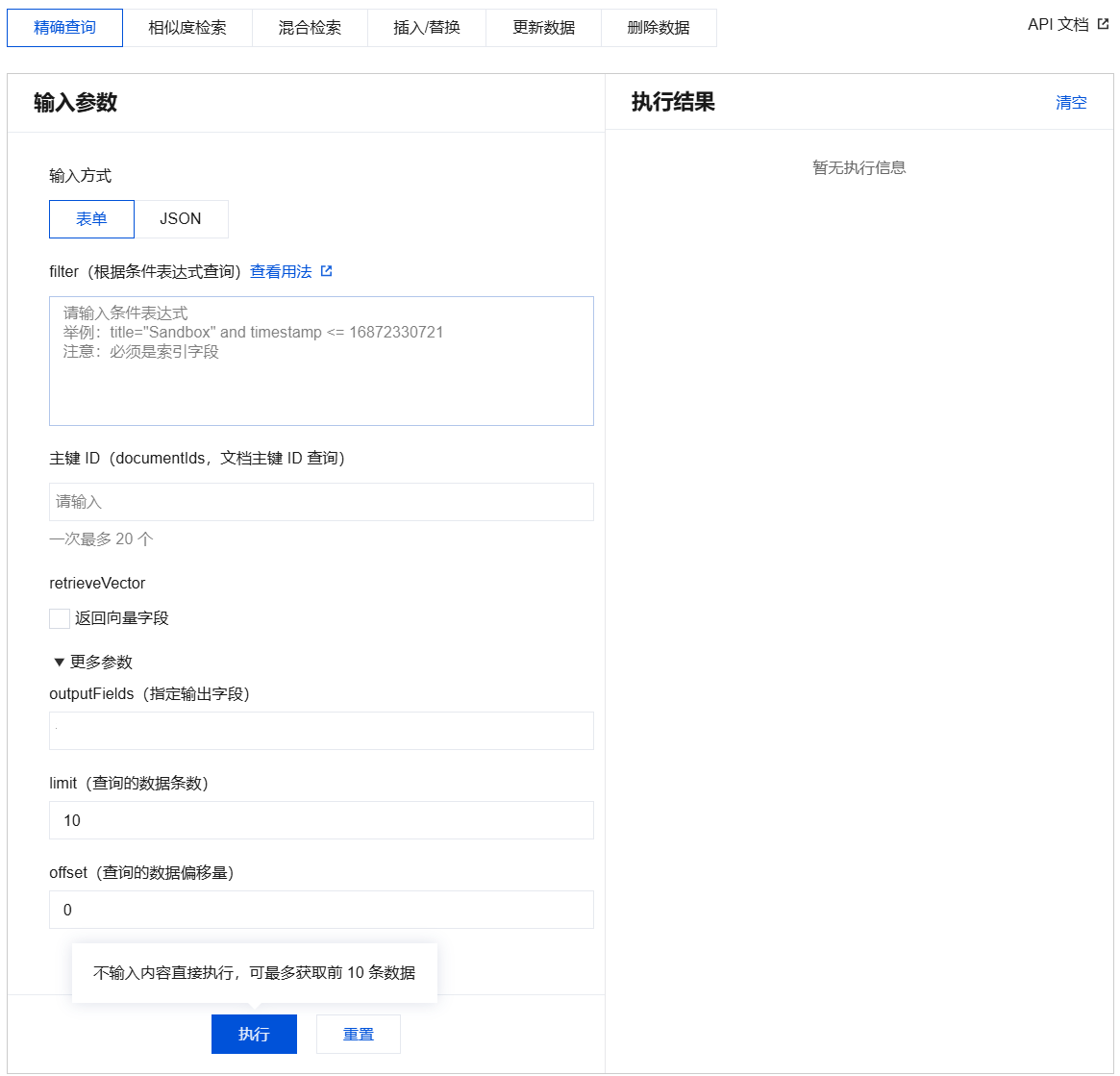
4. 配置输入参数。
输入方式:表单、JSON。
输入参数:参数字段说明如下表所示。
参数(字段)名 | 是否必选 | 默认值 | 说明 |
filter(根据条件表达式查询) | 否 | NULL | 使用创建 Collection 指定的 Filter 索引的字段设置查询过滤表达式。Filter 的表达式格式为 '<field_name><operator><value>',多个表达式之间支持 and(与)、or(或)、not(非)关系。具体信息,请参见 Filter 条件表达式。其中 <field_name>:表示要过滤的字段名。 <operator>:表示要使用的运算符。 string:匹配单个字符串值(=)、排除单个字符串值(!=)、匹配任意一个字符串值(in)、排除所有字符串值(not in)。其对应的 Value 必须使用英文双引号括起来。 uint64:大于(>)、大于等于(>=)、等于(=)、小于(<)、小于等于(<=)、不等于(!=)。例如,exipred_time > 1623388524。 array:数组类型,包含数组元素之一(include)、排除数组元素之一(exclude)、全包含数组元素(include all)。例如,name include (\\"Bob\\", \\"Jack\\")。 json:json 类型的 Filter 表达式语法和 json 字段的键值类型保持一致。若访问 Json 对象中的键,使用点(.)符号连接。例如:Json 类型的字段 bookInfo ,其键 bookName 的 Filter 表达式如下所示。更多信息,请参见 Json 类型表达式。
<value>:表示要匹配的值。 示例: Filter('author="jerry"').And('page>20')。 |
documentIds(主键 ID) | 否 | 无 | 表示要查询的文档的所有 ID,支持批量查询,数组元素范围[1,20]。 |
retrieveVector(返回向量字段) | 否 | false | 标识是否需要返回检索结果的向量值。 true:需要。 false:不需要。默认为 false。 |
outputFields(指定输出字段) | 否 | 无 | 以数组形式配置需返回的字段。 说明: outputFields 与 retrieveVector 参数均可以配置是否输出向量值,二者任意一个配置需输出向量字段,则将输出向量字段。 输出 Json 字段时,outputFields 仅支持指定 Json 字段的名称,而不支持直接指定 Json 字段内部的键(key)。例如,写入 "a": {"b": "test", "c": 12},outputFields 只能指定返回整个 "a" 字段,而无法单独指定返回 "a.b" 。 |
limit(查询的数据条数)
| 否 | 10 | 每页返回的 Document 数量。仅输入方式选择 JSON 时展示。 数据类型:uint 64 取值范围:[1,16384] 注意: 输入方式选择 JSON 时,不配置 documentIds 和 filter 参数,则必须配置 offset 和 limit 参数,返回从 offset 开始的 limit 条数据,避免遍历所有数据而浪费不必要的资源。 |
offset(查询的数据偏移量)
| 否 | 0 | 设置分页偏移量,用于控制分页查询返回结果的起始位置,方便用户对数据进行分页展示和浏览。 取值:为 limit 整数倍。 计算公式:offset=limit*(page-1)。 例如:当 limit = 10,page = 2 时,分页偏移量 offset = 10 * (2 - 1) = 10,表示从查询结果的第11条记录开始返回数据。 |
5. 配置完成后,在输入参数下方单击执行。
在执行结果区域查看执行结果。
说明:
当输入方式选择表单,不输入任何参数,单击执行,可最多获取该集合内的前10条数据。
精确查询输入参数及执行结果示例
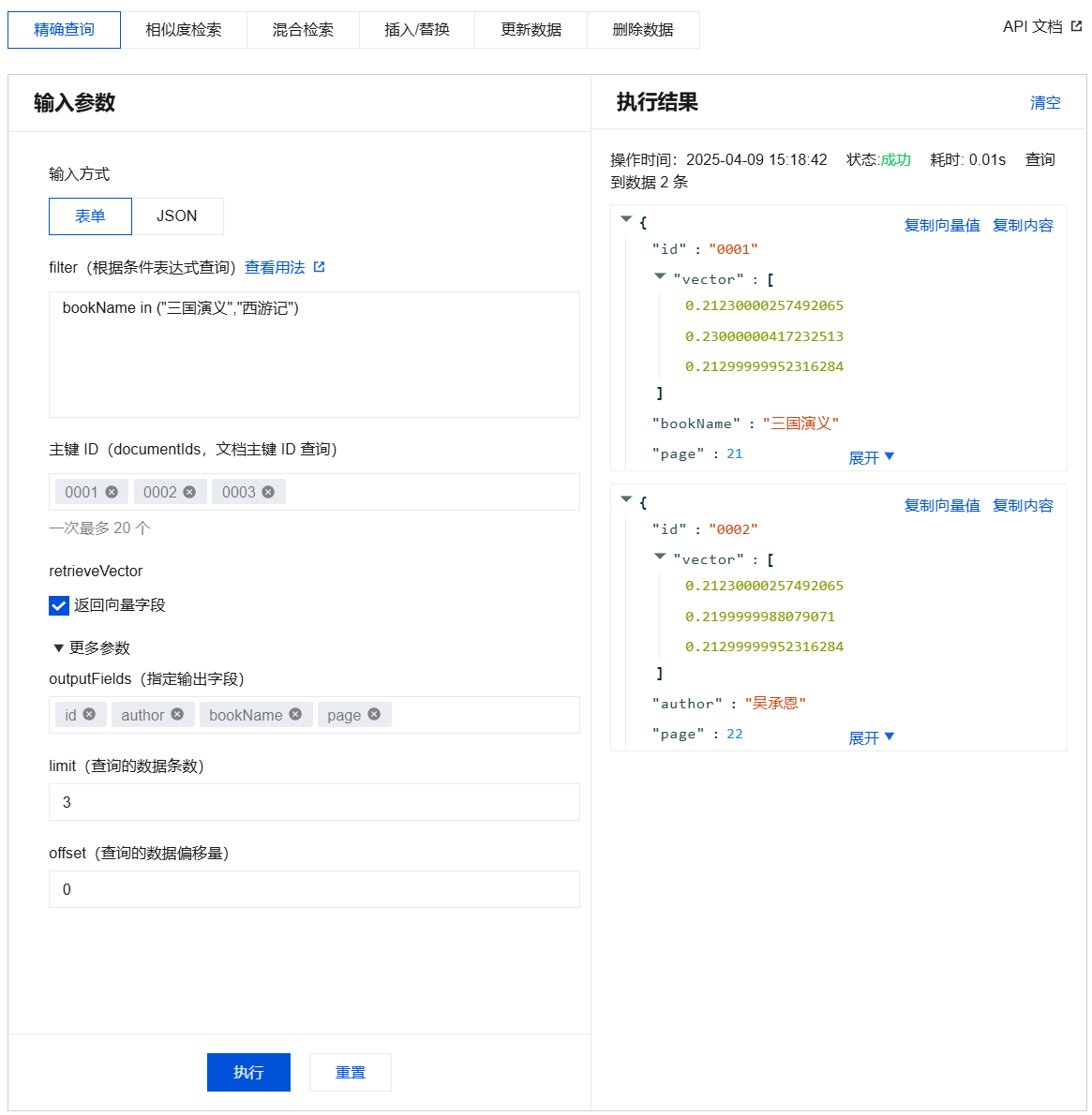
{"database": "db-test","collection": "book-vector","query": {"documentIds": ["0001","0002","0003"],"retrieveVector": true,"filter": "bookName in (\\"三国演义\\",\\"西游记\\")","limit": 3,"offset": 0,"outputFields": ["id","author","bookName","page"]}}
相似度检索
1. 在左侧库表栏,展开数据库和集合。
2. 打开数据操作页面。
方式一:单击集合名称。
方式二:鼠标悬停至待操作集合,在右侧单击
3. 选择相似度检索页签。
4. 配置输入参数。
输入方式:表单、JSON。
输入参数:参数字段说明如下表所示。
参数名称 | 参数含义 | 子参数 | 是否必选 | 配置方法及要求 |
search |
表示查询条件。
| vectors(向量检索) | 是 说明: vectors、 documentIds、embeddingItems 三个字段,必须选择或配置其中一个。 | 表示待查询的向量。 表单:只允许输入一个。 JSON:数组元素数量最大为20。 |
| | documentIds(文档主键 ID) | | 表示待查询的文档 ID。 表单:只允许输入一个 ID。 JSON:数组元素数量最大为20。 |
| |
embeddingItems(文本检索) | | 输入文本信息,用于检索与该文本信息相似的数据。 类型:字符串数组。 范围:数组元素数量最大为20 。 |
| | params(更多参数) | 否 | FLAT :无需指定参数。 HNSW:需配置参数 ef,指定需要访问向量的数目。取值范围[1,32768],默认为10。 IVF 系列:需设置参数 nprobe ,指定所需查询的单位数量。取值范围[1,nlist],其中 nlist 在创建集合时已设置。 |
| | filter | 否 | 查询过滤条件。filter 的表达式格式为 <field_name><operator><value>,多个表达式之间支持 and(与)、or(或)、not(非)关系。具体信息,请参见 混合检索。其中: <field_name>:表示要过滤的字段名。 <operator>:表示要使用的运算符。 string:匹配单个字符串值(=)、排除单个字符串值(!=)、匹配任意一个字符串值(in)、排除所有字符串值(not in)。其对应的 Value 必须使用英文双引号括起来。 uint64:大于(>)、大于等于(>=)、等于(=)、小于(<)、小于等于(<=)、不等于(!=)。例如:expired_time > 1623388524。 array:数组类型,包含数组元素之一(include)、排除数组元素之一(exclude)、全包含数组元素(include all)。例如,name include (\\"Bob\\", \\"Jack\\")。 json:json 类型的 Filter 表达式语法和 json 字段的键值类型保持一致。若访问 Json 对象中的键,使用点(.)符号连接。例如:Json 类型的字段 bookInfo ,其键 bookName 的 Filter 表达式如下所示。更多信息,请参见 Json 类型表达式。
<value>:表示要匹配的值。 示例: uint64_val > 30、game_tag="Detective" |
| | retrieveVector | 否 | 标识是否需要返回检索结果的向量值。 true:需要。 false:不需要。默认为 false。 |
| | limit | 否 | 指定返回最相似的 Top K 条数据的 K 的值。K 为大于0的正整数。 |
| | outputFields | 否 | 指定需要输出的字段。若不设置,将返回所有字段。 说明: retrieveVector 和 outputFields 只要有其中一个配置输出向量字段即可输出 vector。 输出 Json 字段时,outputFields 仅支持指定 Json 字段的名称,而不支持直接指定 Json 字段内部的键(key)。例如,写入"a": {"b": "test", "c": 12},outputFields 只能指定返回整个 "a" 字段,而无法单独指定返回 "a.b" 。 |
5. 配置完成后,在输入参数下方单击执行。
在执行结果区域查看执行结果。
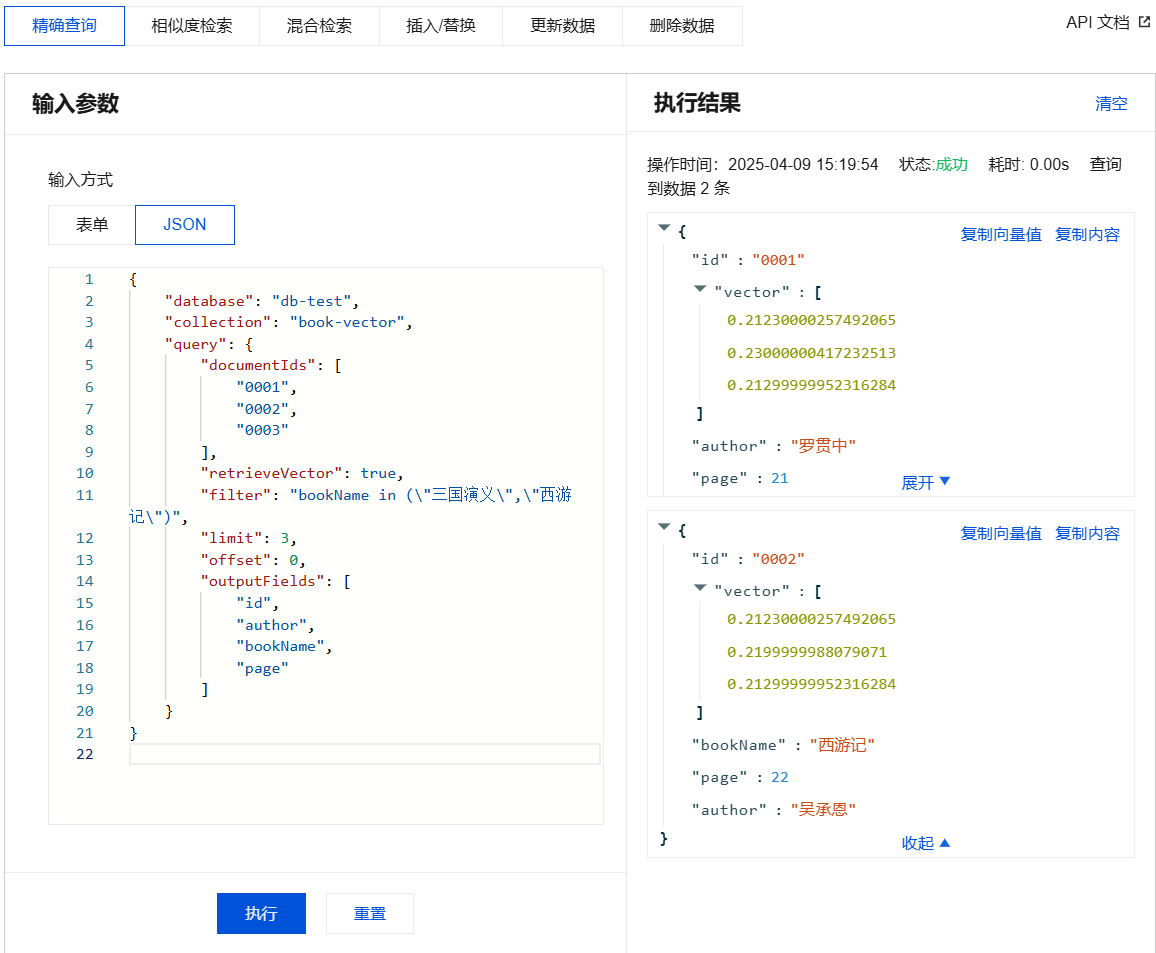
相似度检索输入参数及执行结果示例
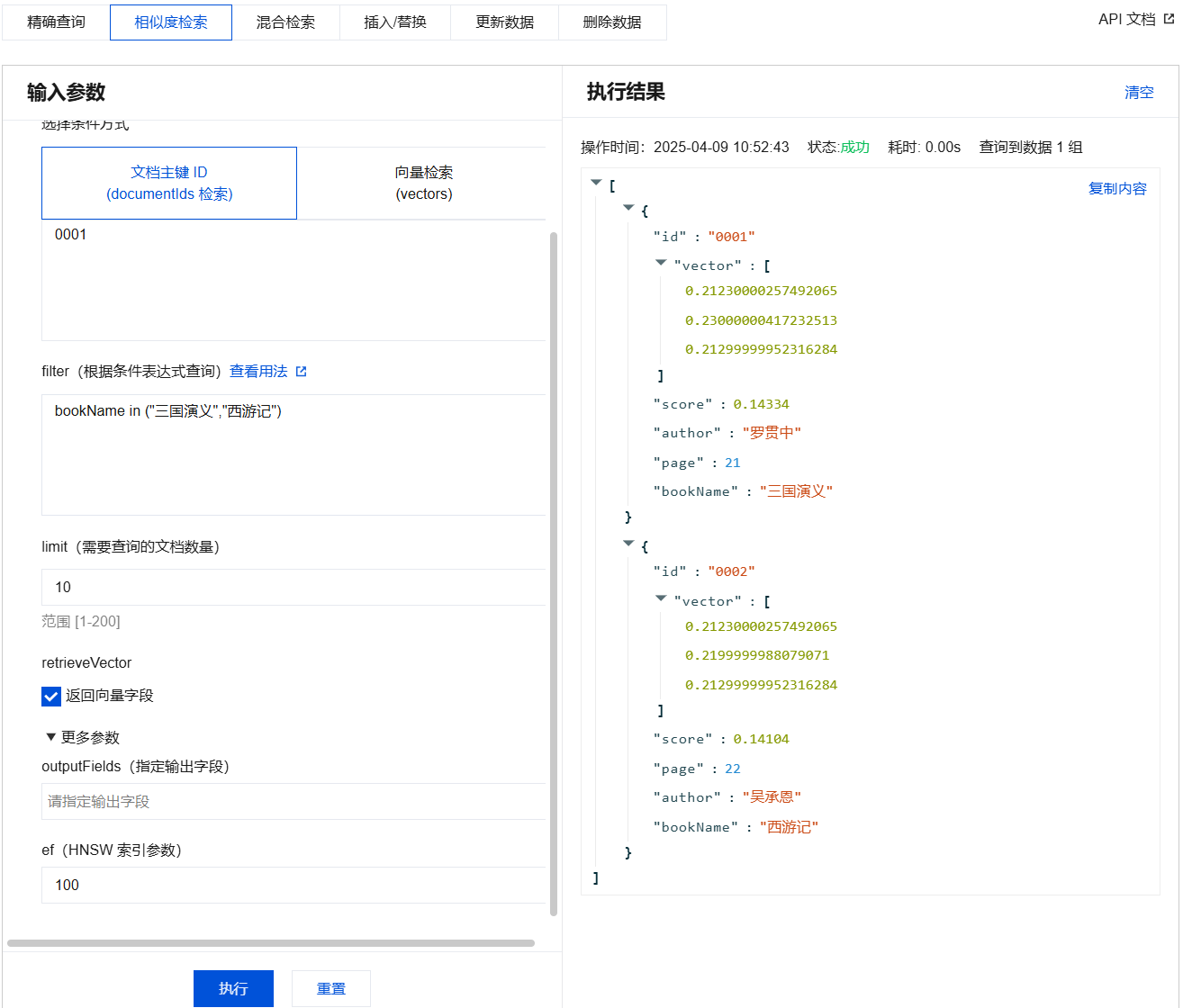
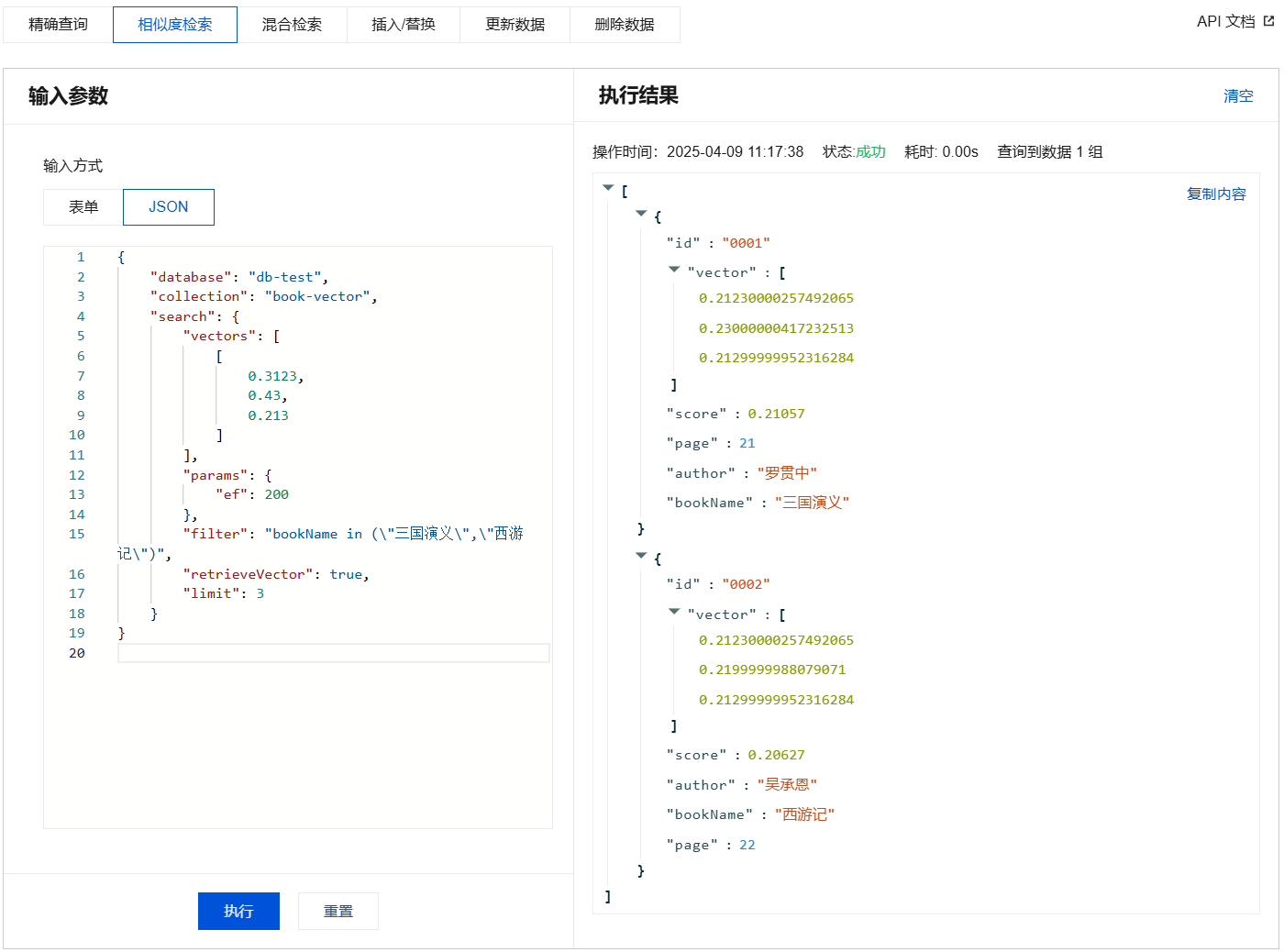
{"database": "db-test","collection": "book-vector","search": {"documentIds": ["0001","0002","0003"],"params": {"ef": 200},"retrieveVector": true,"filter": "bookName in (\\"三国演义\\",\\"西游记\\")","limit": 3}}
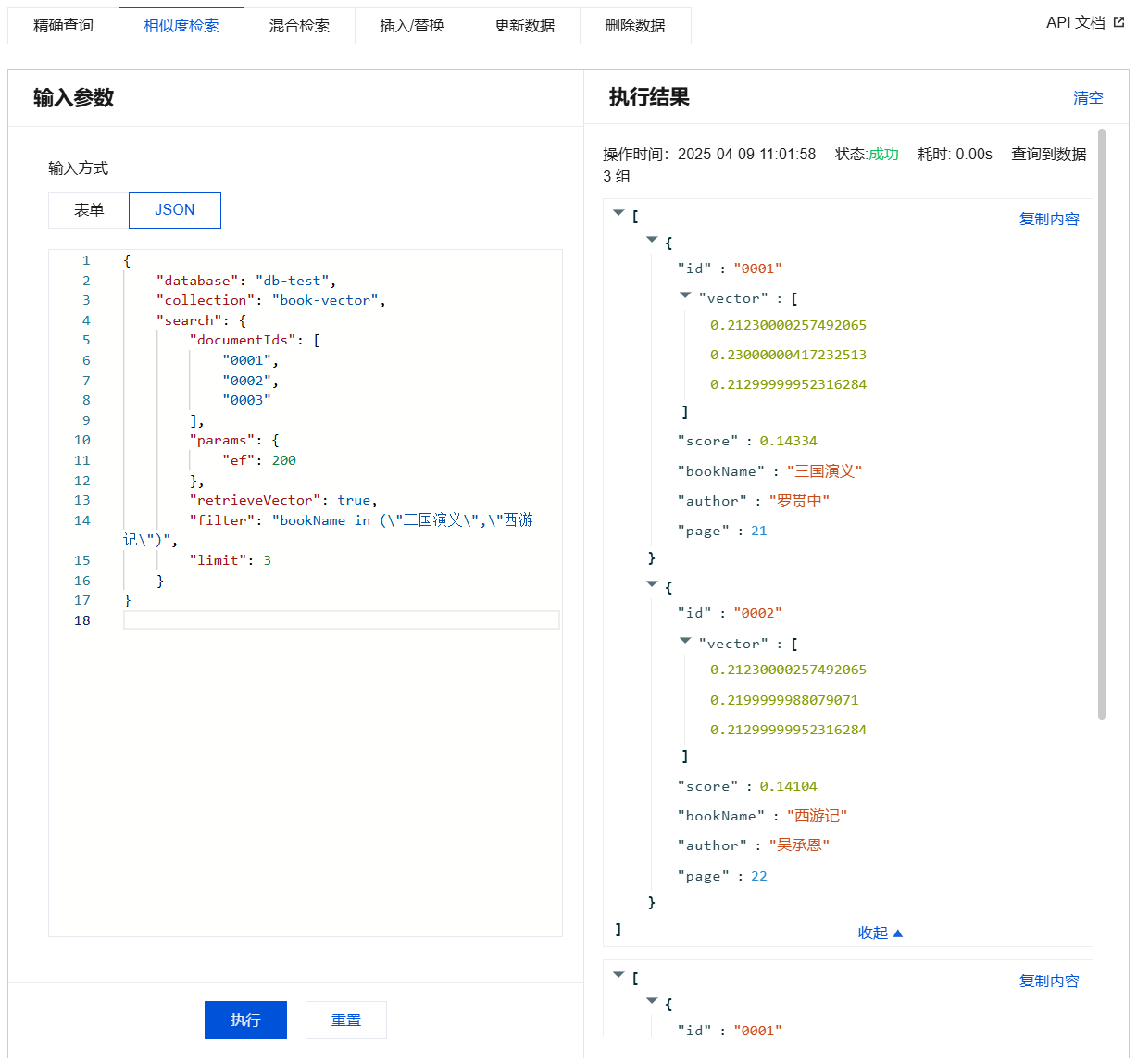
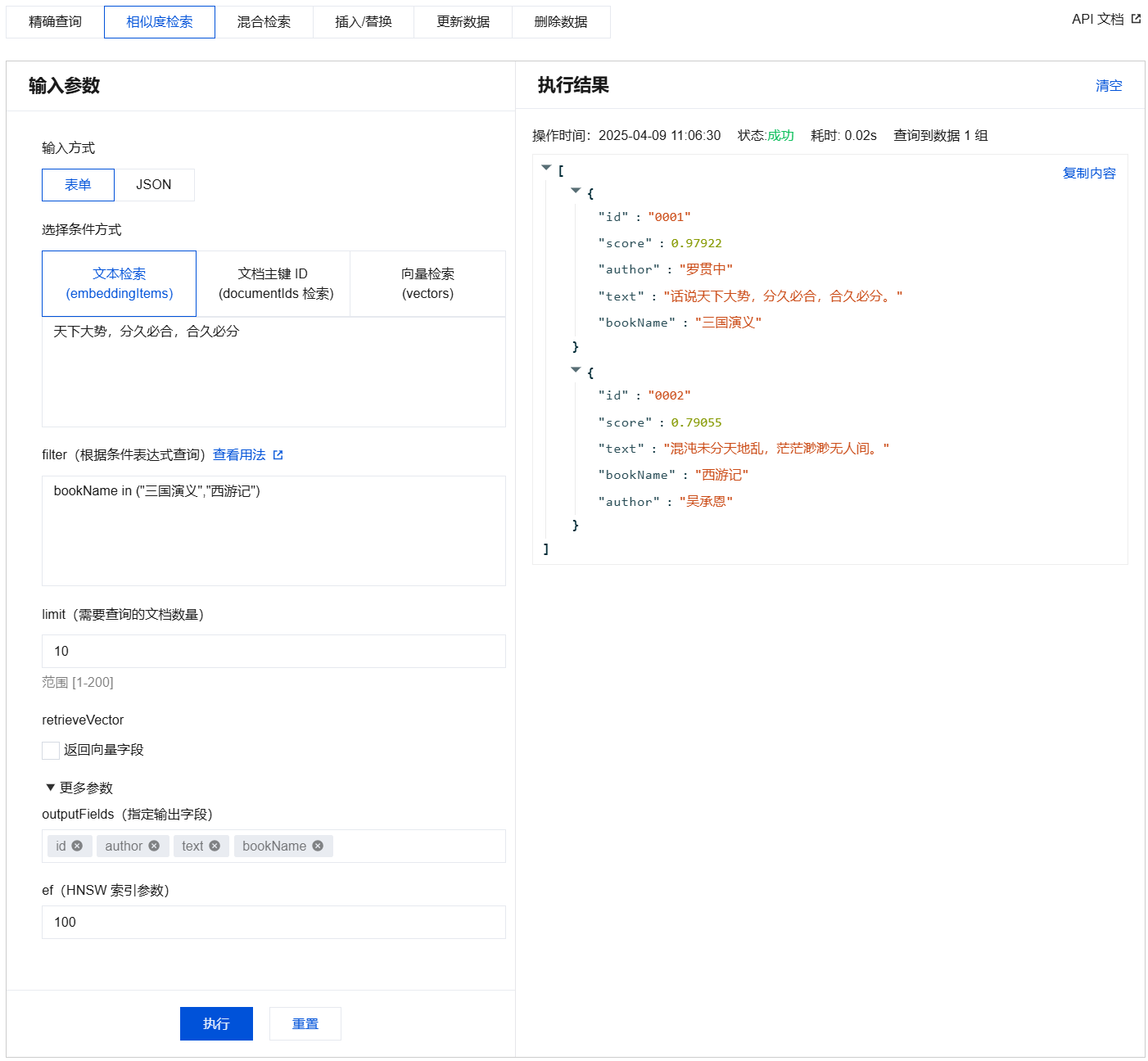
{"database": "db-test","collection": "book-emb","search": {"embeddingItems": ["天下大势,分久必合,合久必分"],"limit": 3,"params": {"ef": 200},"retrieveVector": false,"filter": "bookName in (\\"三国演义\\",\\"西游记\\")","outputFields": ["id","author","text","bookName"]}}
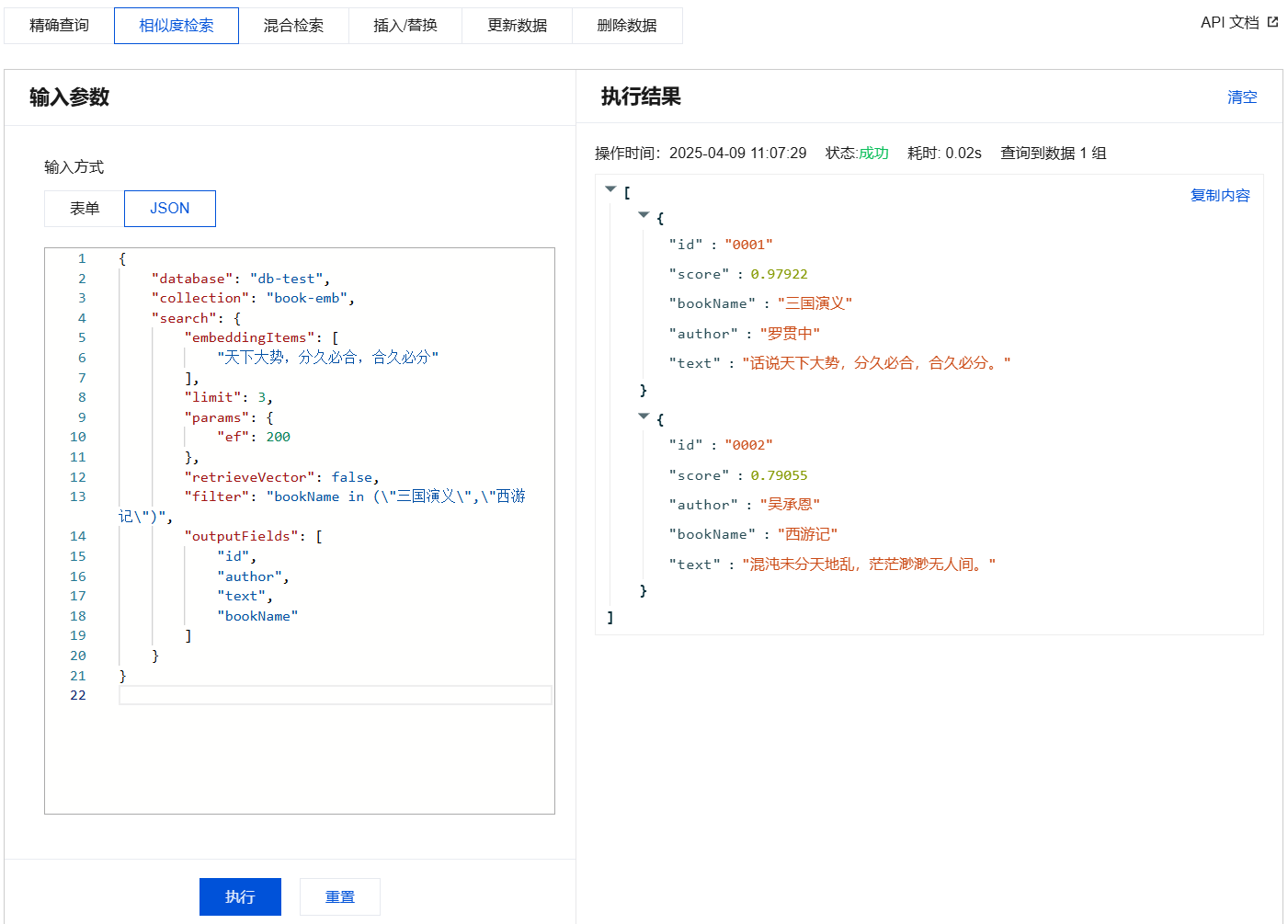
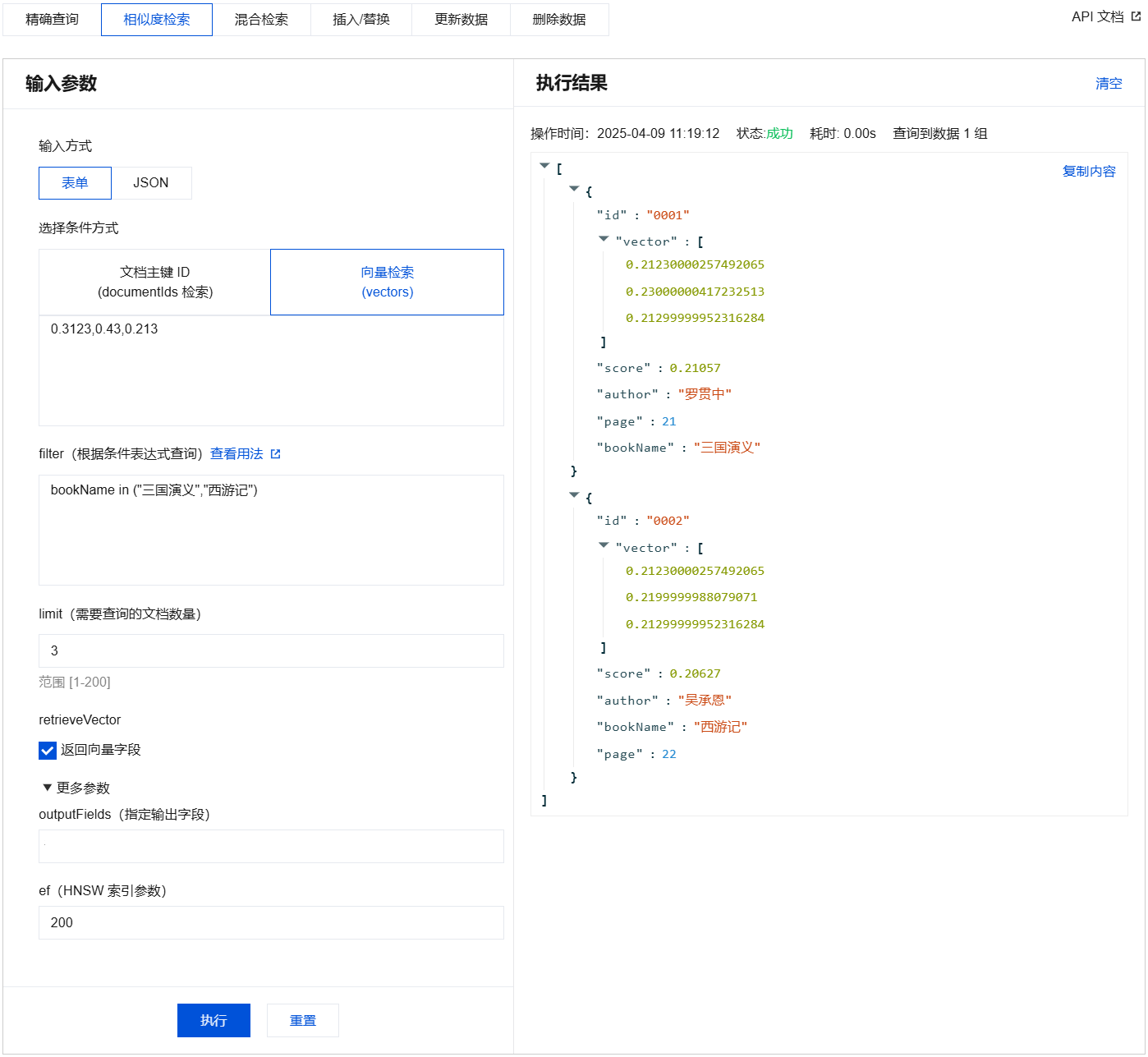
{"database": "db-test","collection": "book-vector","search": {"vectors": [[0.3123,0.43,0.213]],"params": {"ef": 200},"filter": "bookName in (\\"三国演义\\",\\"西游记\\")","retrieveVector": true,"limit": 3}}
混合检索
1. 在左侧库表栏,展开数据库和集合。
2. 打开数据操作页面。
方式一:单击集合名称。
方式二:鼠标悬停至待操作集合,在右侧单击
3. 选择混合检索页签。
4. 配置输入参数。
输入方式:仅支持 JSON。
输入参数:参数字段说明如下表所示。
参数名称 | 参数含义 | 子参数 | 是否必选 | 配置方法及要求 |
database | 指定要查询的 Database 名称。 | - | 是 | 获取集群中的数据库列表,复制需查询数据的集合所属的数据库名。 |
collection | 指定要查询的 Collection 名称。 | - | 是 | 获取集群中的集合列表,复制需查询数据的集合名。 |
search | 配置检索条件 | ann | 是 | 配置检索信息。 fieldName:检索的字段名,支持设置为:vector 或 text。 说明: 其中,vector 为向向量数据的字段名,不可更改;text 为创建 Collection 时,开启 Embedding 功能自定义的原始文本字段名,请以实际定义为准,二者只能选择其中之一。 data:检索的数据列表,当前仅支持输入一条向量或原始文本。 params:检索参数,与索引类型相关。 HNSW 类型:需配置参数 ef,指定需要访问向量的数目。取值范围[1,32768],默认为10。 IVF 系列:需设置参数 nprobe,指定所需查询的单位数量。取值范围[1,nlist],其中 nlist 在创建 Collection 时已设置。 limit:指定稠密向量返回的数量。 |
| | match | 否 | 稀疏向量检索配置。 fieldName:检索的字段名,例如:sparse_vector。 data:检索的稀疏向量,仅支持输入一个。 |
| | rerank | 否 | 检索中重排序(rerank)的配置。参数 method 指定 Rerank 的方法,枚举如下值: weighted:基于不同字段的加权组合来进行排序。 fieldList:列出用于加权计算的字段列表。例如,"fieldList": ['vector', 'sparse_vector']表示密集型与稀疏型加权计算。 weight:定义了 "fieldList" 中每个字段的权重,例如,"weight": [0.9, 0.1]表示"vector" 字段的权重是 0.9,"sparse_vector" 字段的权重是0.1。 rrf:一种融合多个搜索方法的排名结果,通过为每个文档分配倒数排名分数并合并这些分数来生成一个新的综合排名,从而提高搜索结果的准确性和相关度。k 是一个用于计算倒数排名分数的常数,其作用是调整分数计算公式,以控制排名分数的分布。默认值为60。 |
| | filter | 否 | 设置标量字段的 Filter 表达式。格式为 <field_name><operator><value>,多个表达式之间支持 and(与)、or(或)、not(非)关系。具体信息,请参见 混合检索。其中: <field_name>:表示要过滤的字段名。 <operator>:表示要使用的运算符。 string :匹配单个字符串值(=)、排除单个字符串值(!=)、匹配任意一个字符串值(in)、排除所有字符串值(not in)。其对应的 Value 必须使用英文双引号括起来。 uint64:大于(>)、大于等于(>=)、等于(=)、小于(<)、小于等于(<=)、等于(!=)。例如:expired_time > 1623388524。 array:数组类型,包含数组元素之一(include)、排除数组元素之一(exclude)、全包含数组元素(include all)。例如,name include (\\"Bob\\", \\"Jack\\")。 json:json 类型的 Filter 表达式语法和 json 字段的键值类型保持一致。若访问 Json 对象中的键,使用点(.)符号连接。例如:Json 类型的字段 bookInfo ,其键 bookName 的 Filter 表达式如下所示。更多信息,请参见 Json 类型表达式。
<value>:表示要匹配的值。 示例: uint64_val > 30、game_tag="Detective" |
| | retrieveVector | 否 | 表示是否需要返回检索结果的向量值。 true:需要。 false:不需要。默认为 false。 |
| | limit | 是 | 指定返回最相似的 Top K 条数据的 K 的值。K 为大于0的正整数。 |
| | outputFields | 否 | 指定需要输出的字段。若不设置,将返回所有字段。 说明: retrieveVector 和 outputFields 只要有其中一个配置输出向量字段即可输出 vector。 输出 Json 字段时,outputFields 仅支持指定 Json 字段的名称,而不支持直接指定 Json 字段内部的键(key)。例如,写入 "a": {"b": "test", "c": 12},outputFields 只能指定返回整个 "a" 字段,而无法单独指定返回 "a.b" 。 |
5. 配置完成后,在输入参数下方单击执行。
在执行结果区域查看执行结果。
混合检索输入参数及执行结果示例
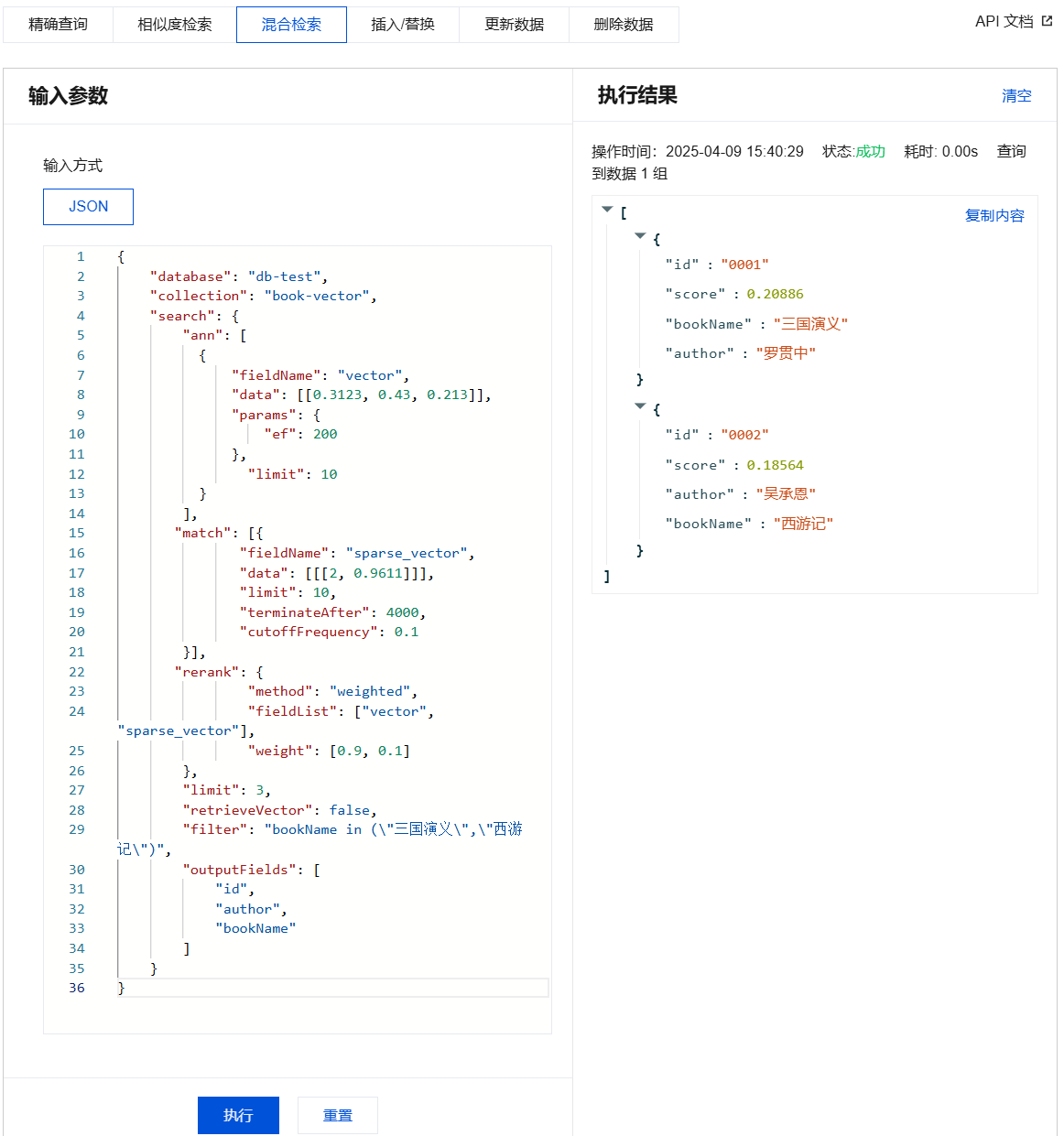
{"database": "db-test","collection": "book-vector","search": {"ann": [{"fieldName": "vector","data": [[0.3123, 0.43, 0.213]],"params": {"ef": 200},"limit": 10}],"match": [{"fieldName": "sparse_vector","data": [[[2, 0.9611]]],"limit": 10,"terminateAfter": 4000,"cutoffFrequency": 0.1}],"rerank": {"method": "weighted","fieldList": ["vector", "sparse_vector"],"weight": [0.9, 0.1]},"limit": 3,"retrieveVector": false,"filter": "bookName in (\\"三国演义\\",\\"西游记\\")","outputFields": ["id","author","bookName"]}}
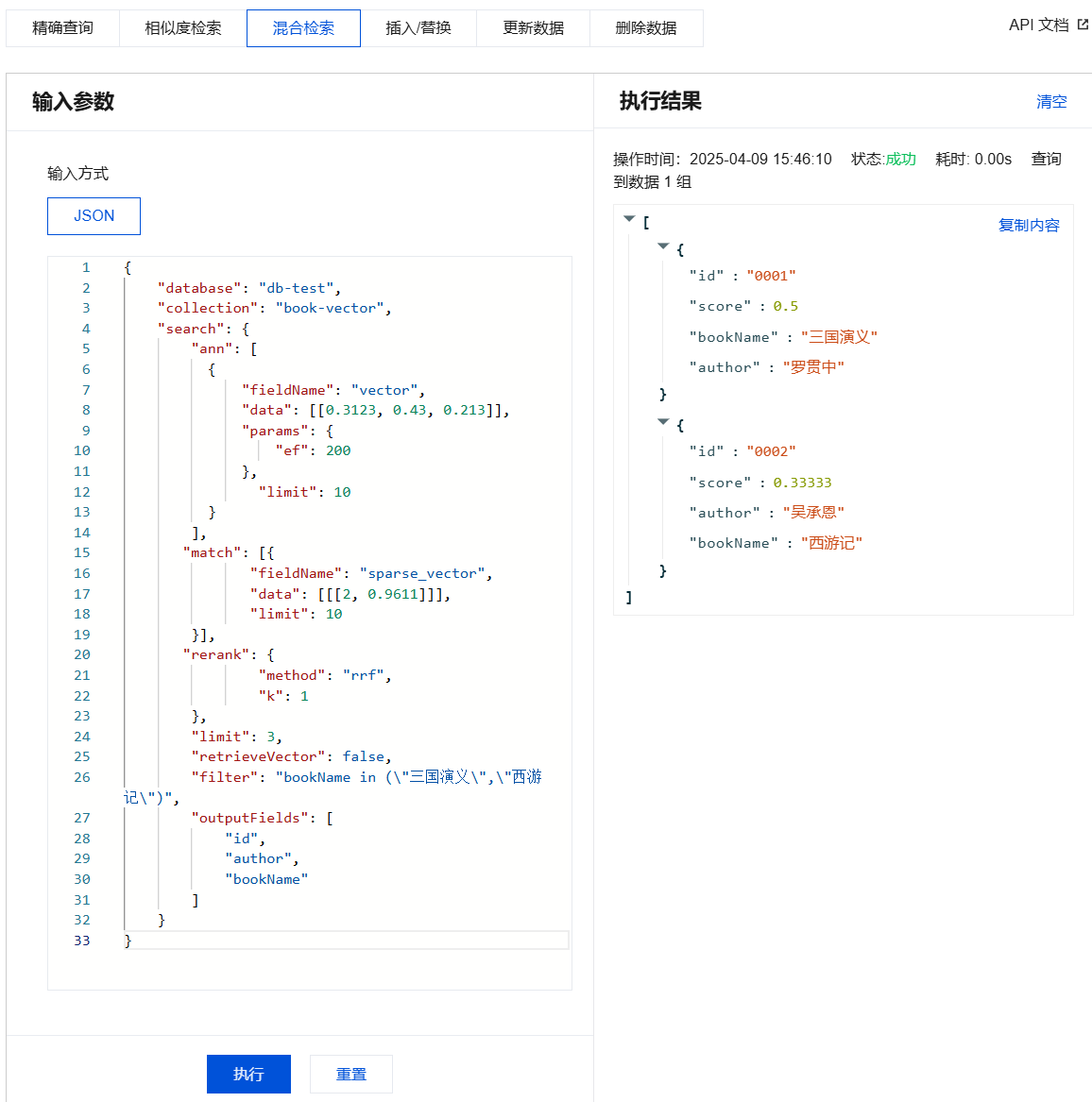
{"database": "db-test","collection": "book-vector","search": {"ann": [{"fieldName": "vector","data": [[0.3123, 0.43, 0.213]],"params": {"ef": 200},"limit": 10}],"match": [{"fieldName": "sparse_vector","data": [[[2, 0.9611]]],"limit": 10}],"rerank": {"method": "rrf","k": 1},"limit": 3,"retrieveVector": false,"filter": "bookName in (\\"三国演义\\",\\"西游记\\")","outputFields": ["id","author","bookName"]}}
更新数据
1. 在左侧库表栏,展开数据库和集合。
2. 打开数据操作页面。
方式一:单击集合名称。
方式二:鼠标悬停至待操作集合,在右侧单击
3. 选择更新数据页签。
4. 配置输入参数。
输入方式:仅支持 JSON。
输入参数:参数字段说明如下表所示。
参数名称 | 参数含义 | 子参数 | 是否必选 | 配置方法及要求 |
query | 设置查询条件检索需更新的文档 | documentIds | 是 | 表示要更新的文档的所有 ID,支持批量查询,数组元素范围[1,20]。 |
| | filter | 否 | 使用创建 Collection 指定的 Filter 索引的字段设置查询过滤表达式。Filter 的表达式格式为 '<field_name><operator><value>',多个表达式之间支持 and(与)、or(或)、not(非)关系。具体信息,请参见 Filter 条件表达式。 <field_name>:表示要过滤的字段名。 <operator>:表示要使用的运算符。 string :匹配单个字符串值(=)、排除单个字符串值(!=)、匹配任意一个字符串值(in)、排除所有字符串值(not in)。其对应的 Value 必须使用英文双引号括起来。 uint64:大于(>)、大于等于(>=)、等于(=)、小于(<)、小于等于(<=)、不等于(!=)。例如:expired_time > 1623388524。 array:数组类型,包含数组元素之一(include)、排除数组元素之一(exclude)、全包含数组元素(include all)。例如,name include (\\"Bob\\", \\"Jack\\")。 json:json 类型的 Filter 表达式语法和 json 字段的键值类型保持一致。若访问 Json 对象中的键,使用点(.)符号连接。例如:Json 类型的字段 bookInfo ,其键 bookName 的 Filter 表达式如下所示。更多信息,请参见 Json 类型表达式。
<value>:表示要匹配的值。 示例: uint64_val > 30、game_tag="Detective" |
update | 设置需更新的字段 | vector | 否 | 更新 vector 字段的向量数据。 说明: |
| | text | 否 | string:字符型。 float:浮点型数据。 说明: |
| | old_field | 否 | 当前已存在的字段,更新字段对应的数据。 类型:string 字符长度要求:[1,256]。 |
| | new_field | 否 | 新增字段,并给新字段赋值。 类型:string。 字符长度要求:[1,256]。 |
5. 配置完成后,在输入参数下方单击执行。
在执行结果区域查看执行结果。
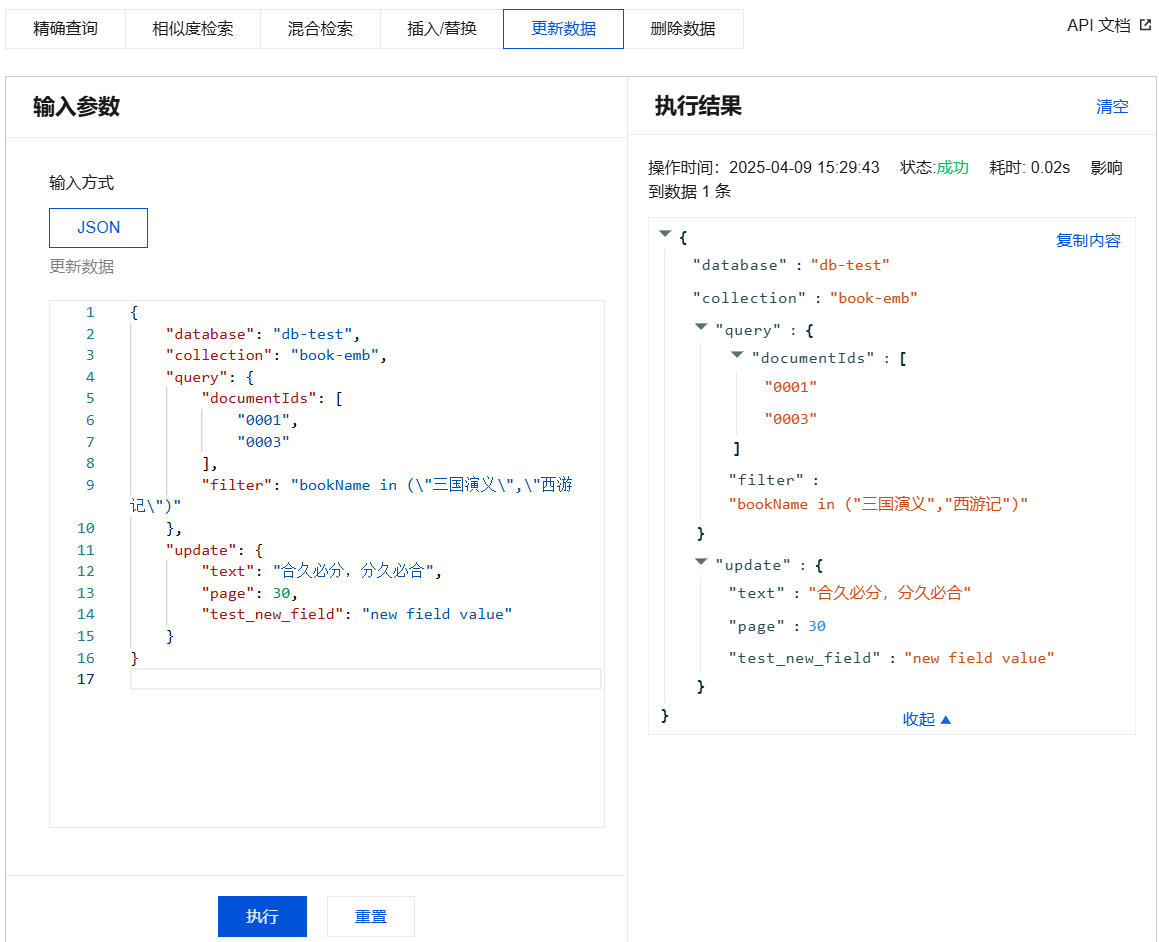
更新数据输入参数及执行结果示例
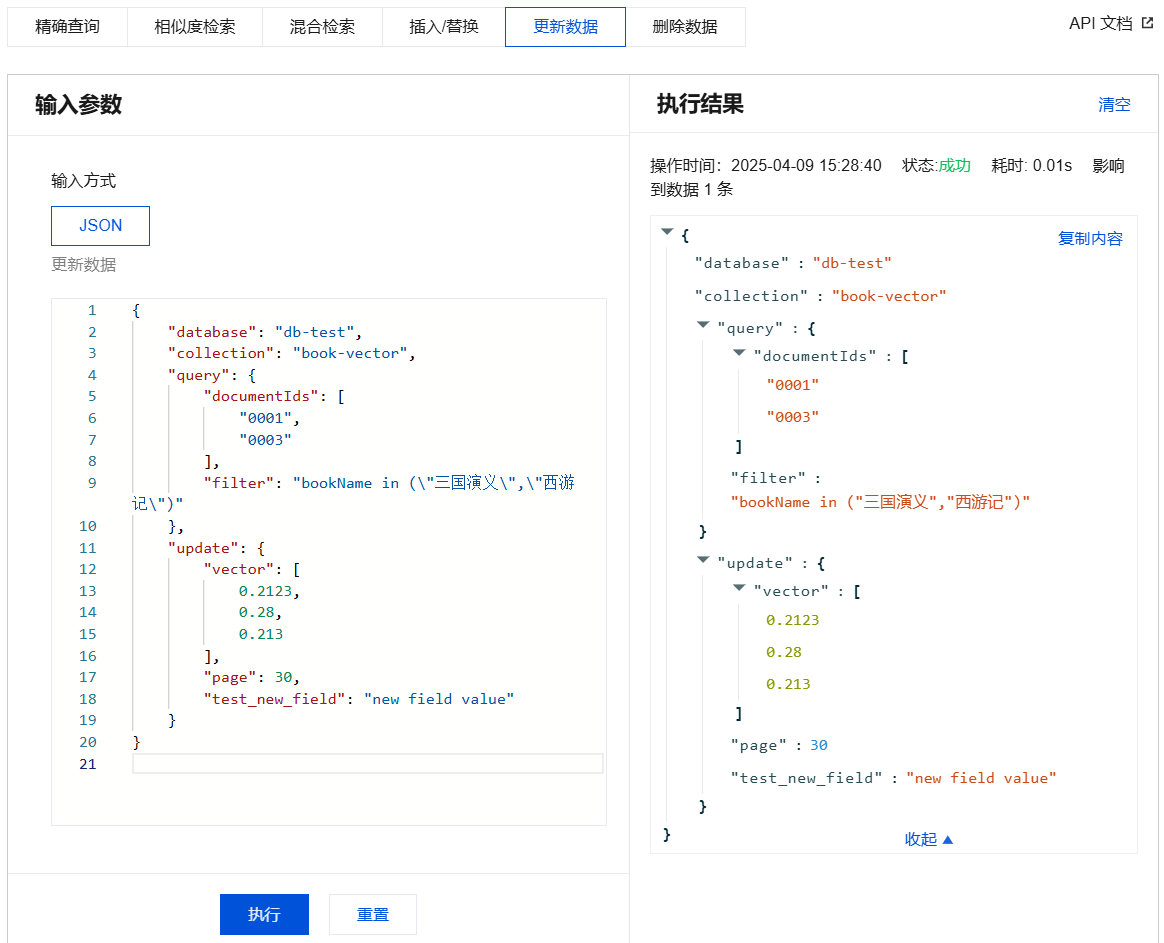
{"database": "db-test","collection": "book-vector","query": {"documentIds": ["0001","0003"],"filter": "bookName in (\\"三国演义\\",\\"西游记\\")"},"update": {"vector": [0.2123,0.28,0.213],"page": 30,"test_new_field": "new field value"}}
{"database": "db-test","collection": "book-emb","query": {"documentIds": ["0001","0003"],"filter": "bookName in (\\"三国演义\\",\\"西游记\\")"},"update": {"text": "合久必分,分久必合","page": 30,"test_new_field": "new field value"}}
删除数据
1. 在左侧库表栏,展开数据库和集合。
2. 打开数据操作页面。
方式一:单击集合名称。
方式二:鼠标悬停至待操作集合,在右侧单击
3. 选择删除数据页签。
4. 配置输入参数。
输入方式:表单、JSON。
输入参数:参数字段说明如下表所示。
参数(字段)名 | 是否必选 | 说明 |
filter(根据条件表达式查询) | 否 | 使用创建 Collection 指定的 Filter 索引的字段设置查询过滤表达式。Filter 的表达式格式为 '<field_name><operator><value>',多个表达式之间支持 and(与)、or(或)、not(非)关系。具体信息,请参见 Filter 条件表达式。 <field_name>:表示要过滤的字段名。 <operator>:表示要使用的运算符。 string :匹配单个字符串值(=)、排除单个字符串值(!=)、匹配任意一个字符串值(in)、排除所有字符串值(not in)。其对应的 Value 必须使用英文双引号括起来。 uint64:大于(>)、大于等于(>=)、等于(=)、小于(<)、小于等于(<=)、不等于(!=)。例如:expired_time > 1623388524。 array:数组类型,包含数组元素之一(include)、排除数组元素之一(exclude)、全包含数组元素(include all)。例如,name include (\\"Bob\\", \\"Jack\\")。 json:json 类型的 Filter 表达式语法和 json 字段的键值类型保持一致。若访问 Json 对象中的键,使用点(.)符号连接。例如:Json 类型的字段 bookInfo ,其键 bookName 的 Filter 表达式如下所示。更多信息,请参见 Json 类型表达式。
<value>:表示要匹配的值。 示例: uint64_val > 30、game_tag="Detective" |
documentIds(主键 ID) | 否 | 表示要删除的 Document 的 ID,可以批量删除,数据元素最大值为20。 说明: 至少配置 documentIds 或 filter 参数中的一个,同时配置 documentIds 与 filter 参数,删除数据将会取二者交集。 |
5. 配置完成后,在输入参数下方单击执行。
在执行结果区域查看执行结果。
删除数据输入参数及执行结果示例
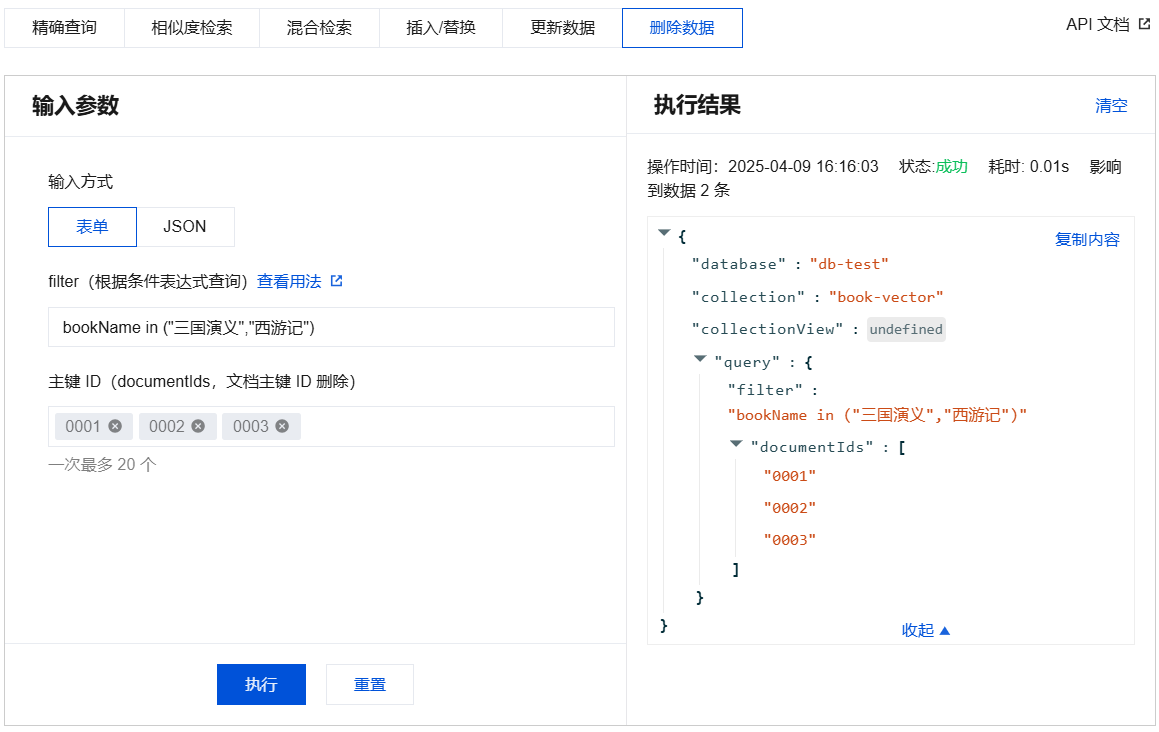
{"database": "db-test","collection": "book-emb","query": {"documentIds": ["0001","0002","0003"],"filter": "bookName in (\\"三国演义\\",\\"西游记\\")"}}