背景
容器服务的超级节点,相较普通节点,支持快速弹性伸缩,将以往多个节点转为一个节点进行管理,使得管理承载的容器资源更为简单。然而,容器节点可能会遇到硬件故障、资源不足、网络故障等问题,导致容器实例无法正常运行。
为了提高容器服务的可靠性和稳定性,需进行超级节点故障演练。通过演练,可以验证系统在容器节点出现故障时能否正常运行,提前暴露此故障场景下的一系列问题,以便优化系统架构并做好应急预案。
演练实施
步骤一:演练准备
在可用的标准集群容器超级节点上,部署测试服务。
在可用的 Serverless 集群容器超级节点上,部署测试服务。
步骤二:创建演练
1. 登录 智能顾问控制台 > 架构治理,进入治理模式,点击混沌演练。(详细创建演练方式请参阅 使用智能顾问进行混沌演练 )
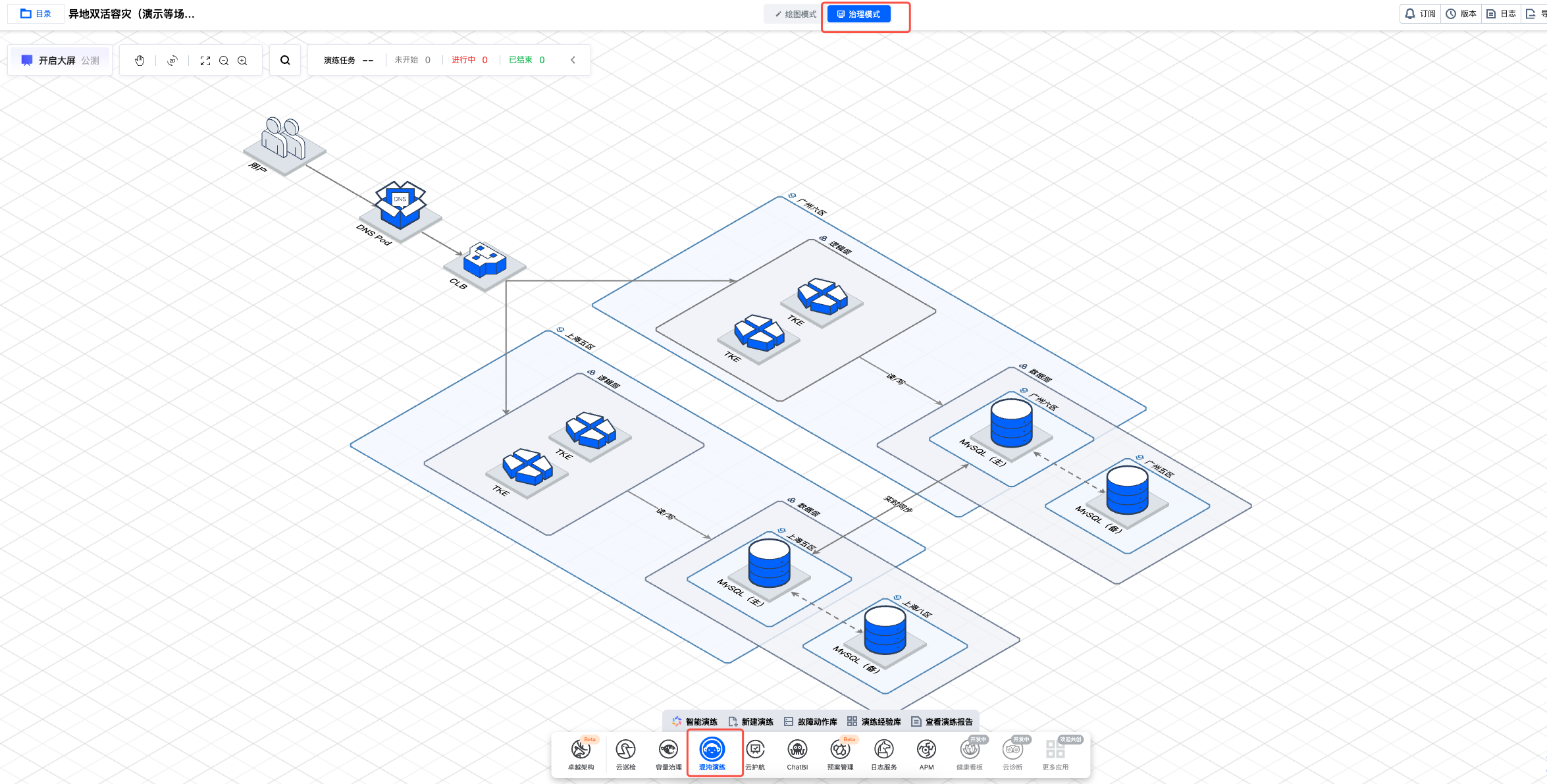
2. 点击新建演练,填写演练基本信息,完成后点击下一步。
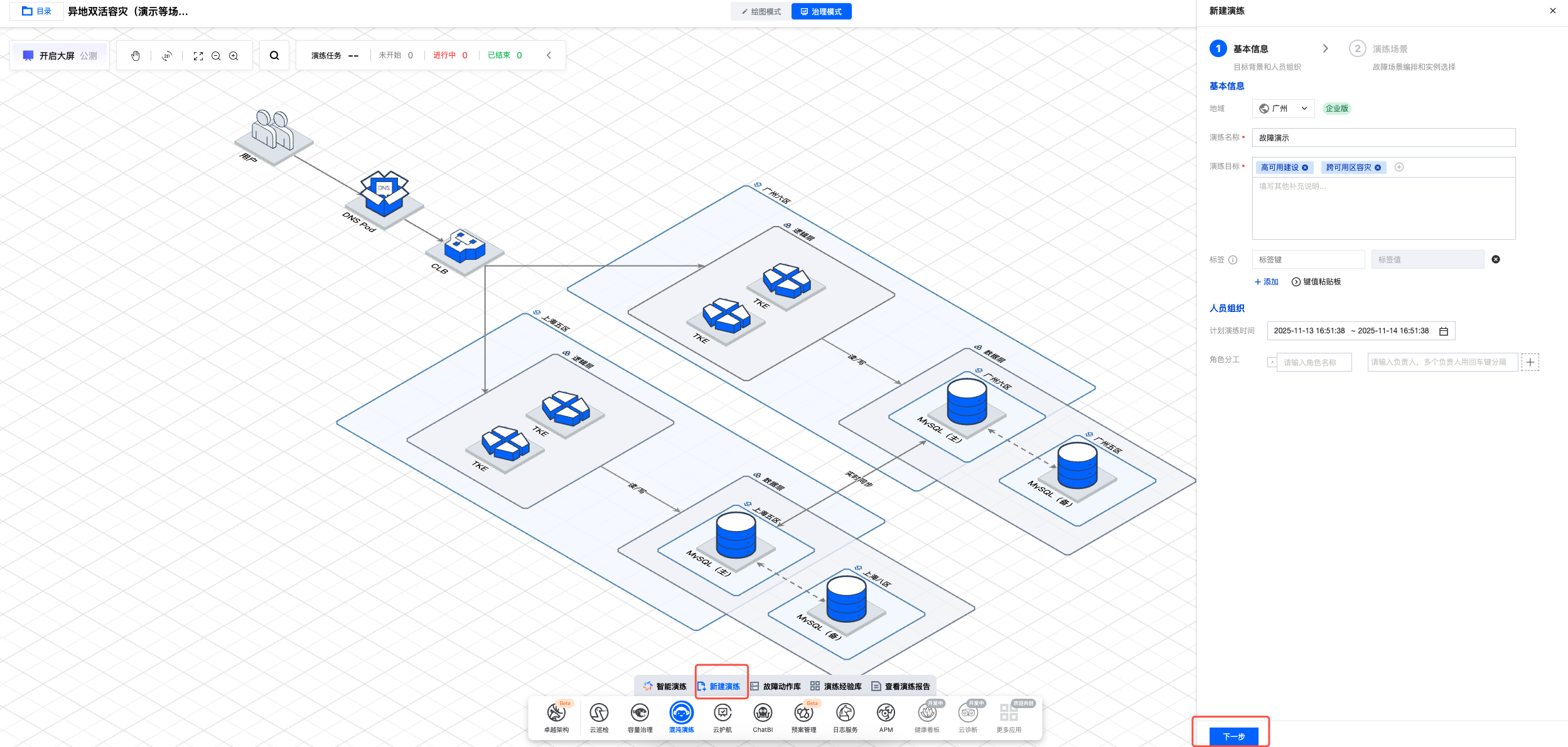
3. 创建两个动作组,在演练实例中,分别选择容器-标准集群超级节点、 Serverless 集群超级节点,选择后点击搜索添加,添加实例资源。亦可通过架构图添加方式,直接点击架构图上的 TKE 资源,选择实例进行添加。
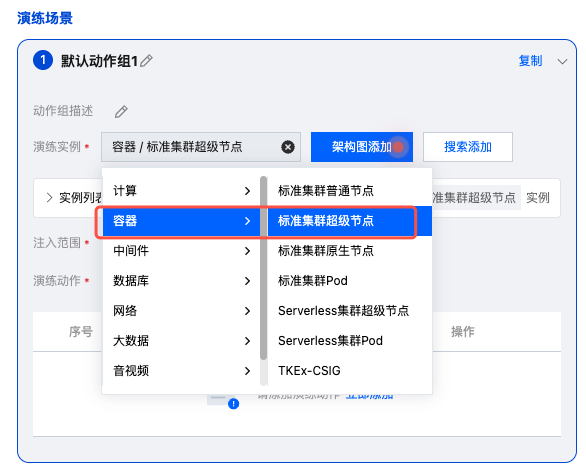
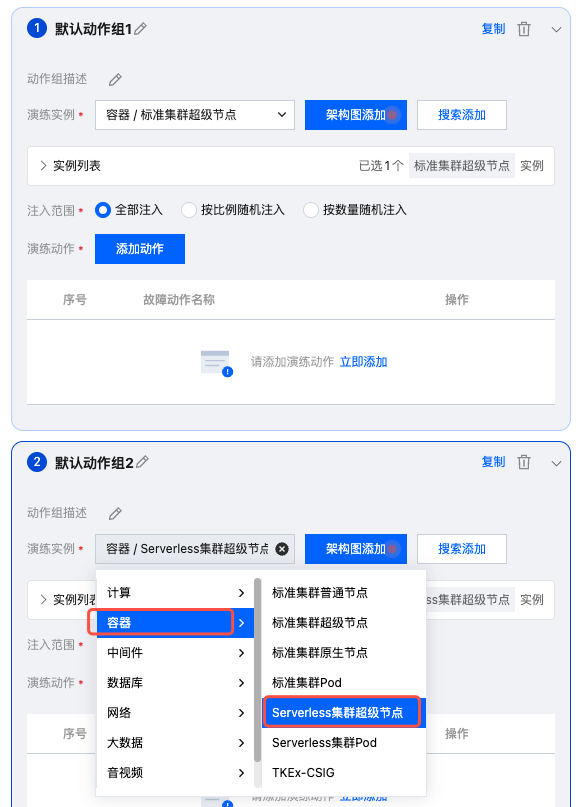
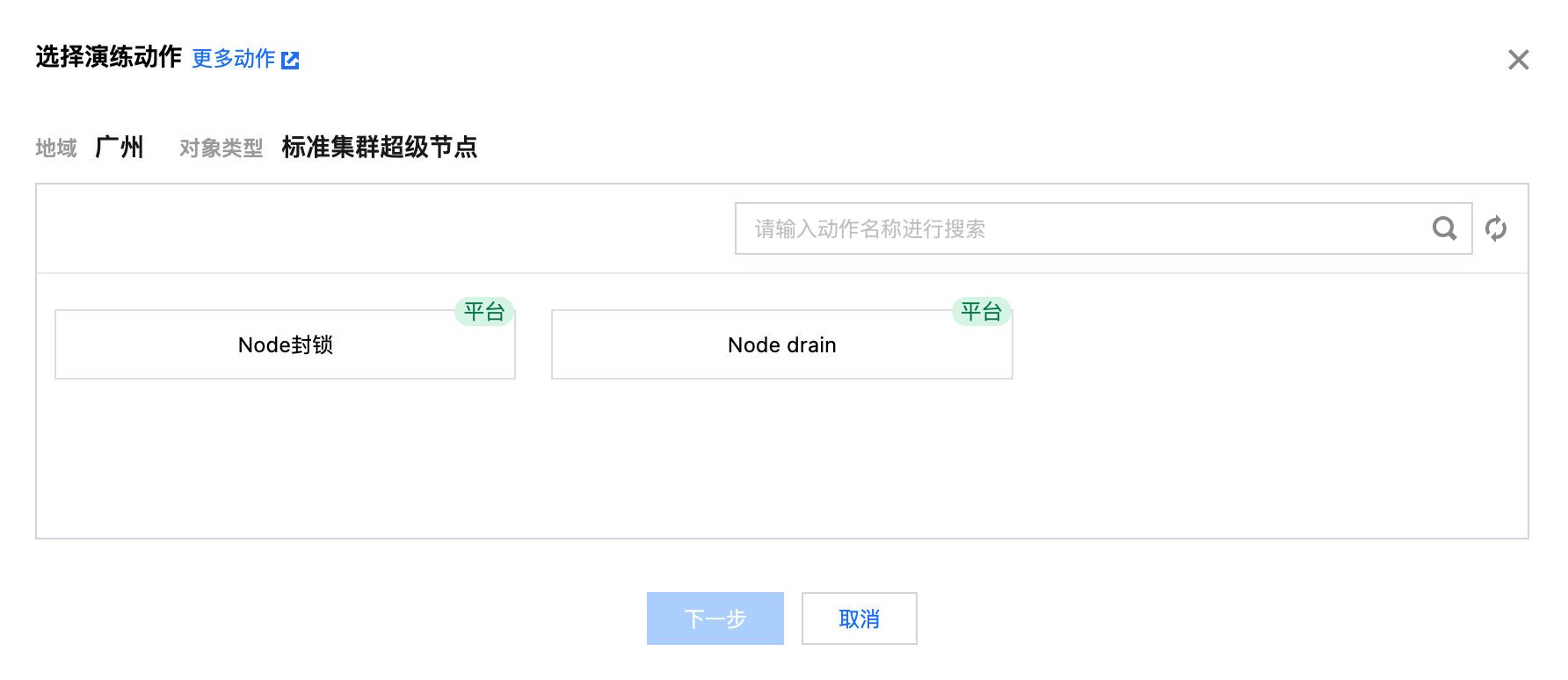
4. 为两个动作组分别添加实例后,点击添加动作,选择故障动作:Node封锁、Node drain(Node驱逐)。点击下一步配置动作参数。
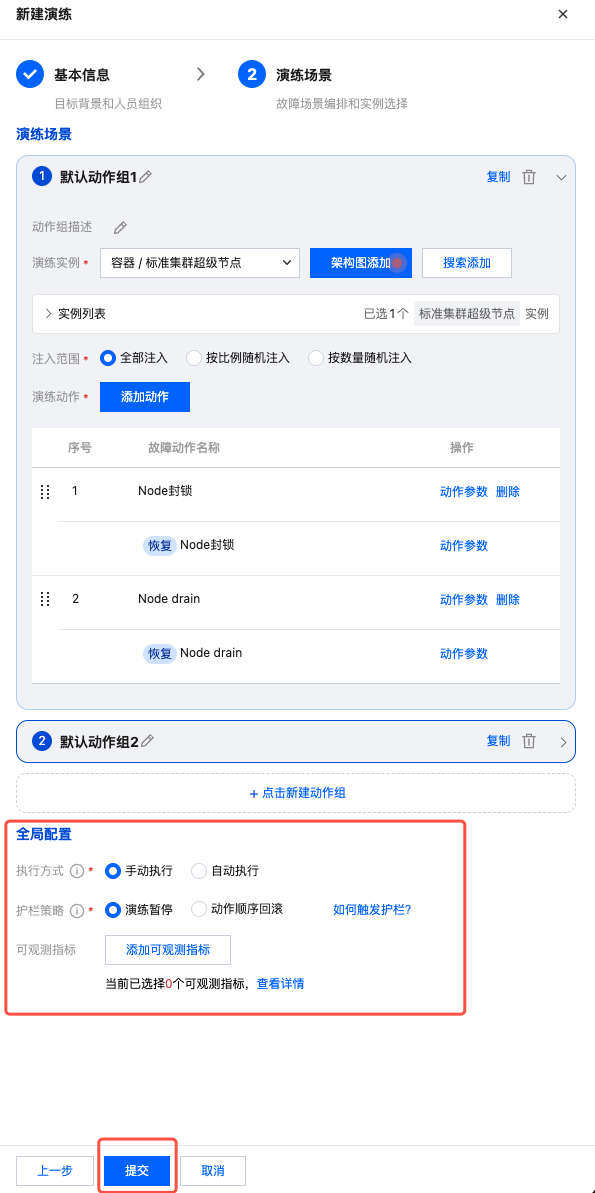
5. 参数配置完成之后,在全局配置中选择执行方式、护栏策略,及添加可观测指标。配置完成后,点击提交,即可完成演练任务创建。
步骤三:执行演练
1. 进入演练详情,前往动作组,按照已编排完成的动作顺序依次点击执行。

2. 执行 Node 封锁和 Node 封锁恢复。
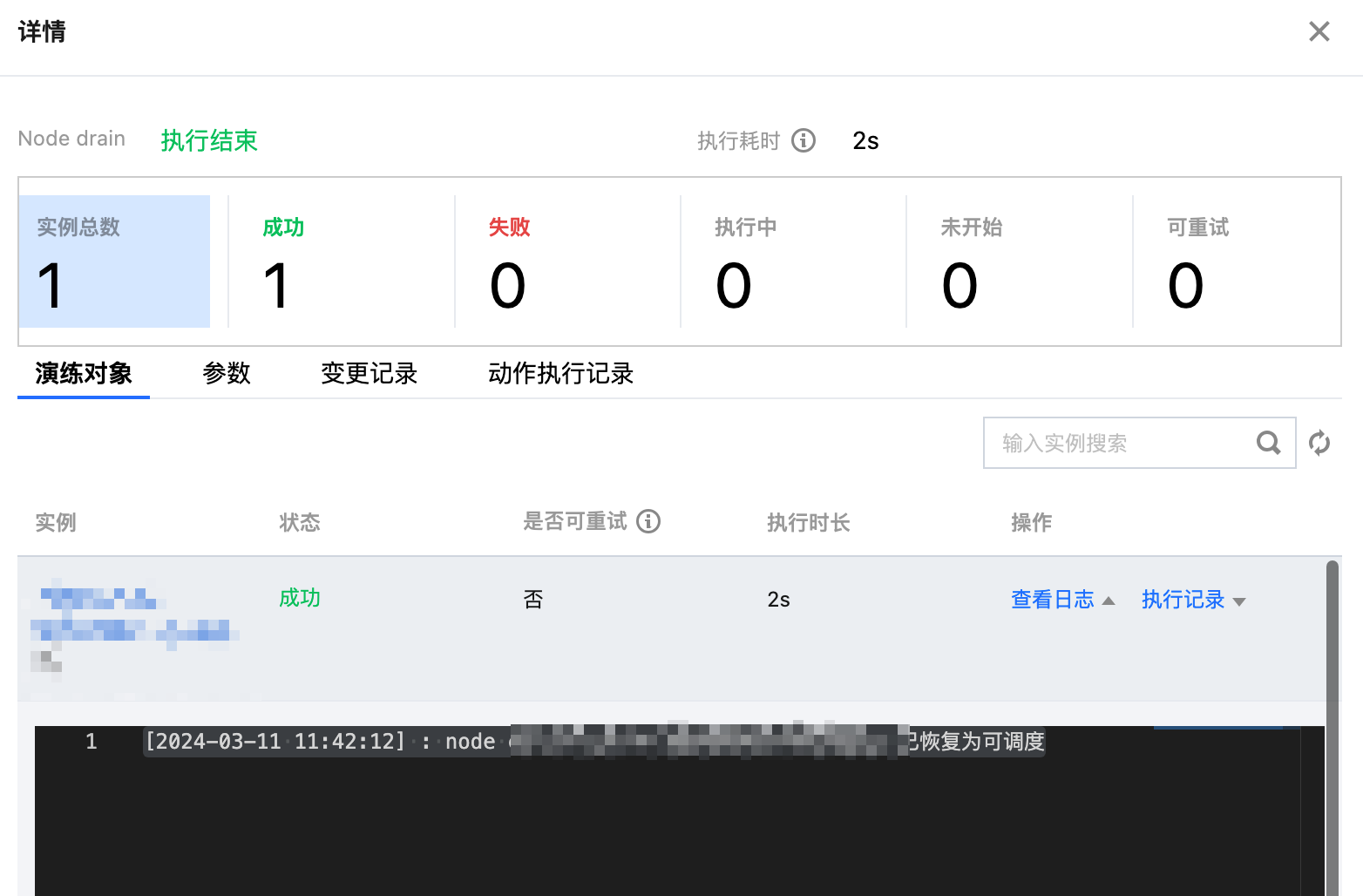
2.1 执行 Node 封锁故障动作,查看动作卡片中的执行日志,并观察节点状态,发现已经被封锁,无法被调度。
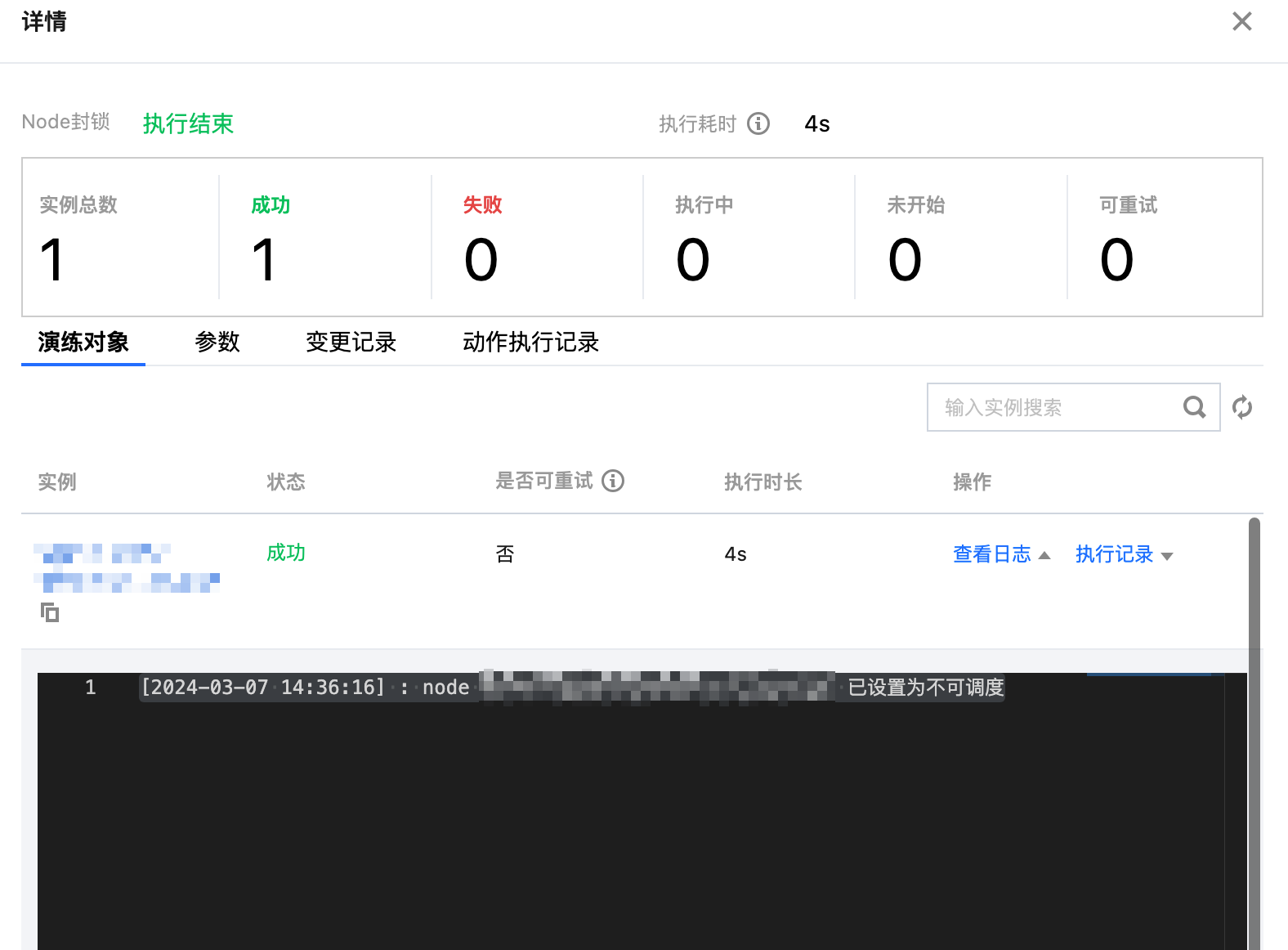
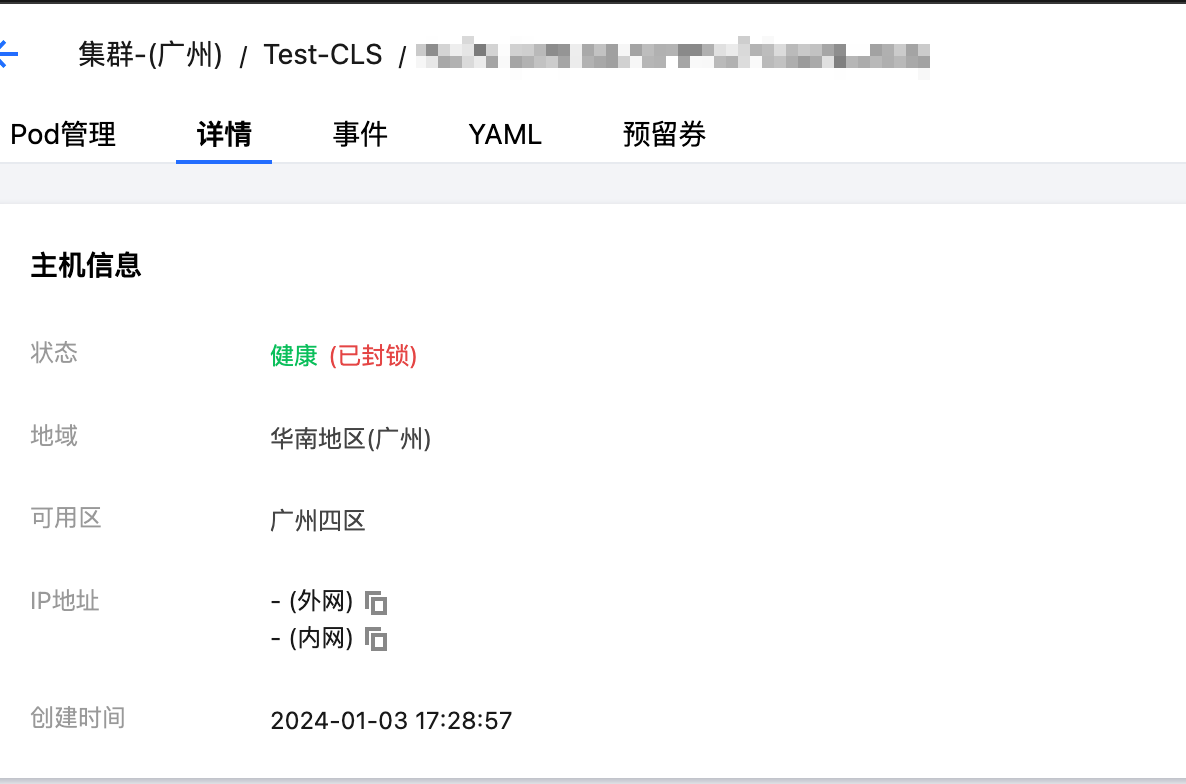
2.2 执行 Node 封锁的故障恢复动作,解除节点封锁,观察节点状态。
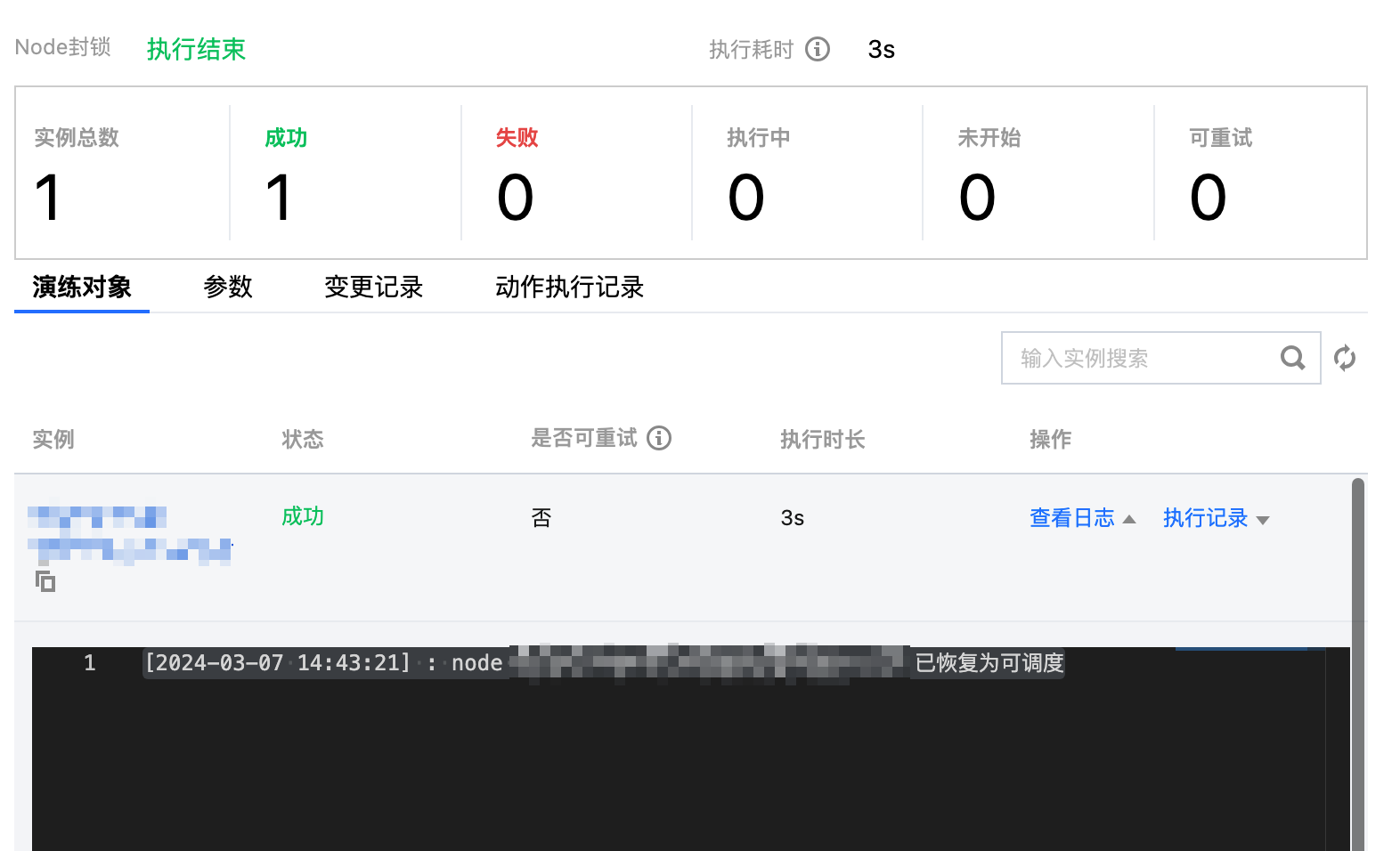
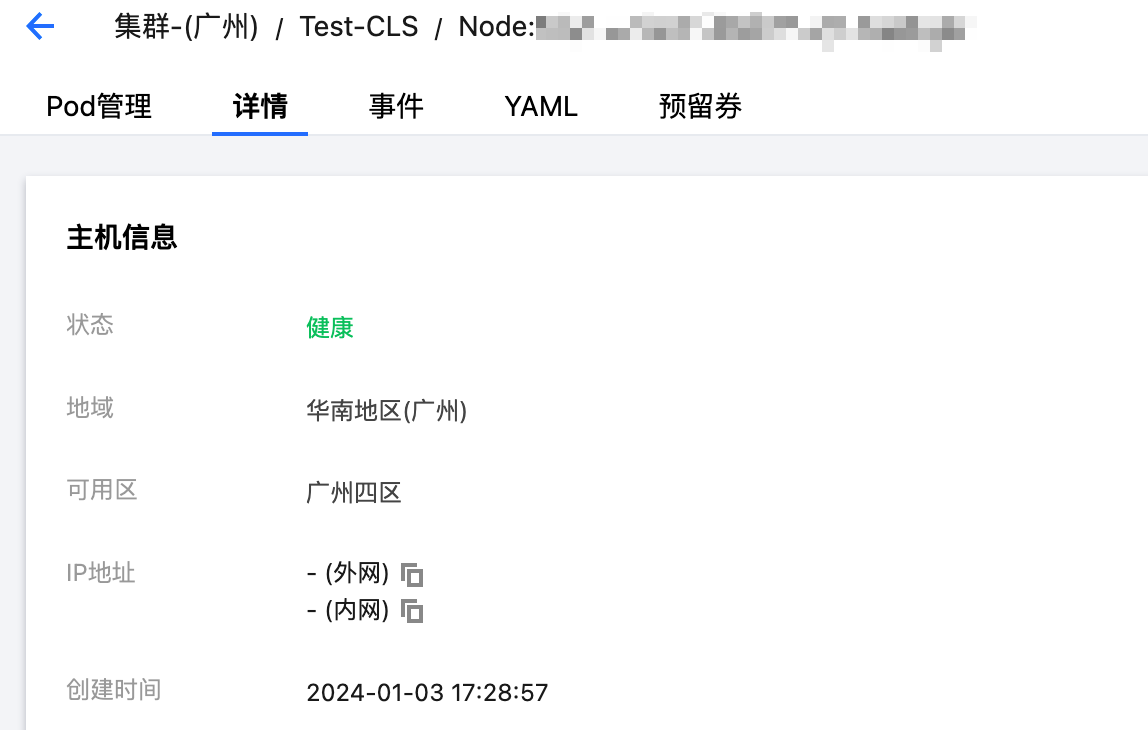
3. 执行 Node drain 和 Node drain 恢复。
3.1 查看节点当前 Pod 列表,检查服务的高可用策略,保证服务所在 Pod 在被节点驱逐后其他节点有足够重启 Pod 的资源容量。
3.2 执行 Node drain 故障动作,造成节点内资源驱逐,动作卡片中会提示出被驱逐的 Pod,方便观察被影响到的服务,并对超级节点进行封锁,不可再被调度。同时经由集群调度,被驱逐的 Pod 在其他 Node 重建恢复服务。
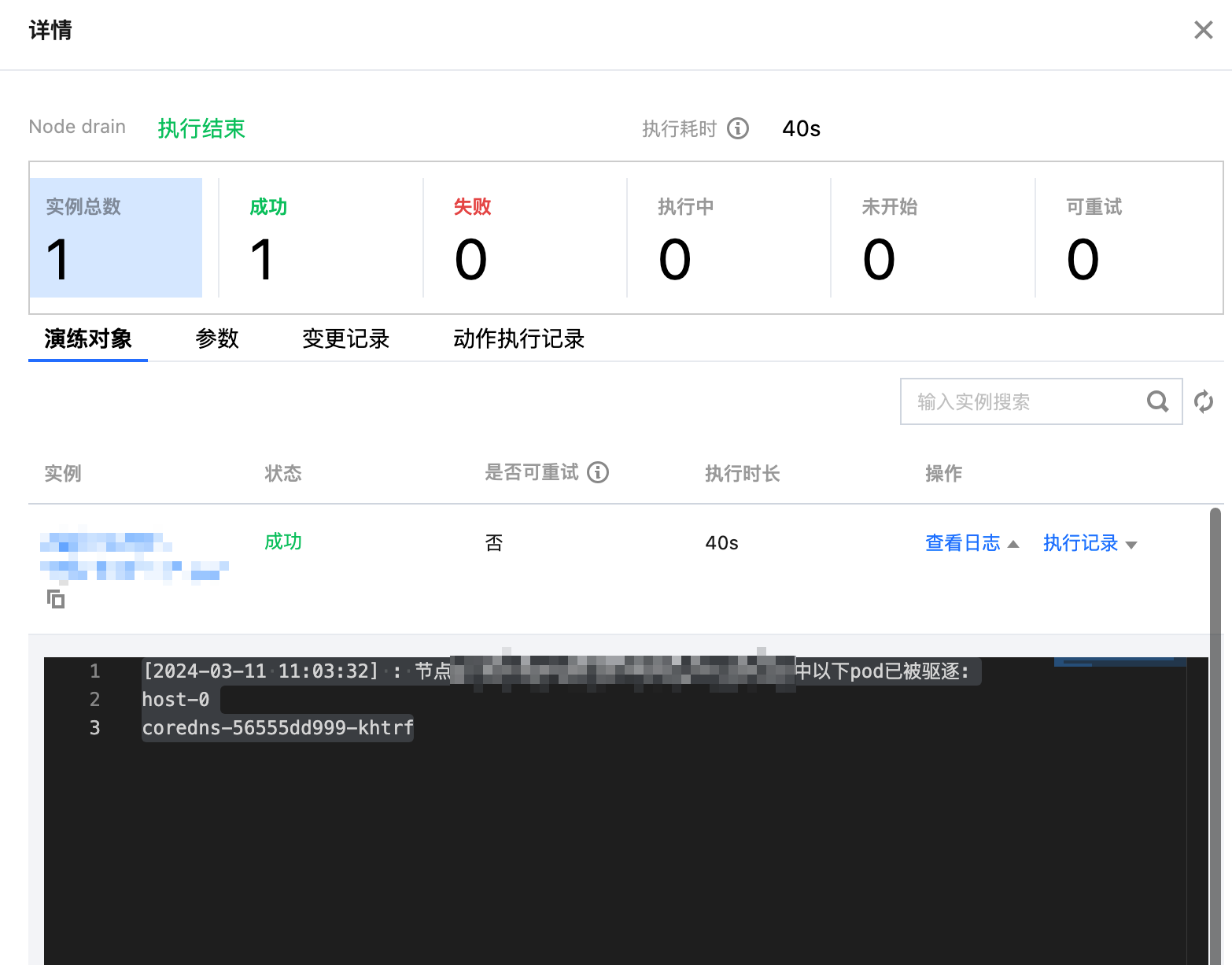

3.3 执行故障恢复。节点解除封锁,恢复可调度状态。