数据集成提供了 Kafka 的读取和写入能力,本文为您介绍使用 Kafka 进行实时数据同步的前置环境配置以及当前能力支持情况。
支持版本
目前数据集成已支持 Kafka 单表及整库级实时读写,使用实时同步能力需遵循以下版本限制:
说明:
Kafka 类型的数据源支持开源自建的 Kafka 和腾讯云消息队列 CKafka
类型 | 版本 |
Kafka | 2.4.1、2.7.1、2.8.1、2.8.2 |
使用限制
Kafka 整库来源端需满足 canal-json、debezium、ogg-json 序列化格式。
一个整库任务支持多个 Topic,需要切换至手写模式并用逗号分割。
canal-json/debezium 格式需要包含 mysqltype,sqltype, primarykey 字段。
Kafka 为来源端时仅支持将新增列、删除列、新增表事件同步到目标端。
Kafka环境准备
Kafka 客户端与服务端建立连接的过程如下所示:
1. 客户端使用您指定的 bootstrap.servers 地址连接 Kafka 服务端,Kafka 服务端根据配置向客户端返回集群中各台 broker 的元信息,包括各台 broker 的连接地址。
2. 客户端使用第一步 broker 返回的连接地址连接各台 broker 进行读取或写入:
我们需要注意当 bootstrap.servers 地址可以连通时,仍然报网络问题连通性问题时,您可以参考以下方式进行排查。
排查下 Kafka 服务端返回的 broker 连接地址是否连通性存在问题。
检查 Kafka broker 配置文件 server.properties 中 listeners 和 advertised.listeners 的地址是否可以和集成资源组网络连通。
3. Kafka 目标端支持 Topic 自动创建,支持指定 Partition 分区策略。如需使用自动创建 Topic 能力,请提前在 Kafka 服务端设置:
auto.create.topics.enable=true
开启自动创建 Topic 功能后,目标 Topic 需遵守 CKafka/kafka Topic 命名规则,以防止任务运行时 Topic 创建失败。
Kafka 开启自动创建 Topic 时,请合理配置好分区数,避免造成性能问题。
实时整库同步读取配置
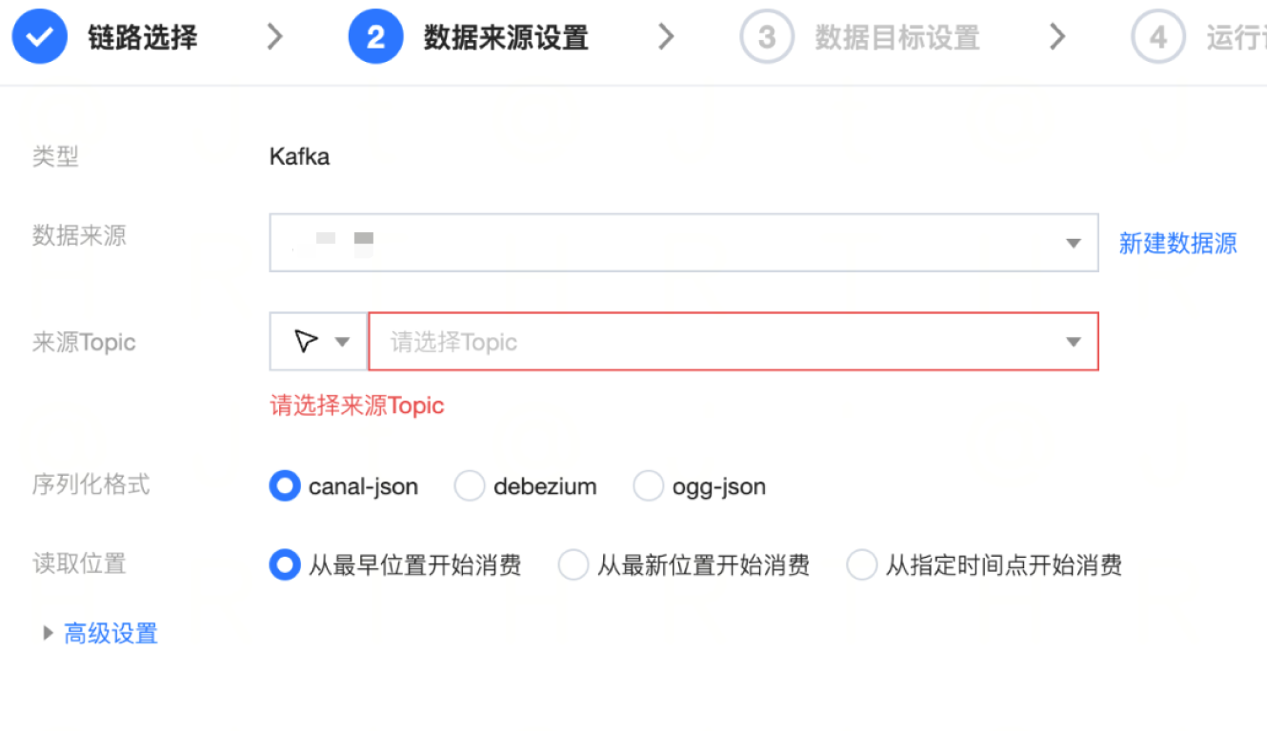
参数 | 说明 |
数据来源 | 选择需要同步的 Kafka 数据源。 Kafka 读取端数据源类型支持 Kafka、Ckafka。 |
来源 Topic | 选择或输入任务计划消费的 Topic 名称。 |
序列化格式 | 设置 Kafka 内原始消息格式,目前支持解析 canal-json、debezium、ogg-json。 说明: 设置格式需与消息实际格式保持一致。 |
读取位置 | 设置 Kafka 数据读取位点: 从最早开始:earlist。 从最新开始:latest。 从指定时间开始:设定具体任务启动时间位点。 |
高级设置(可选) | 可根据业务需求配置参数。 |
实时整库同步写入配置
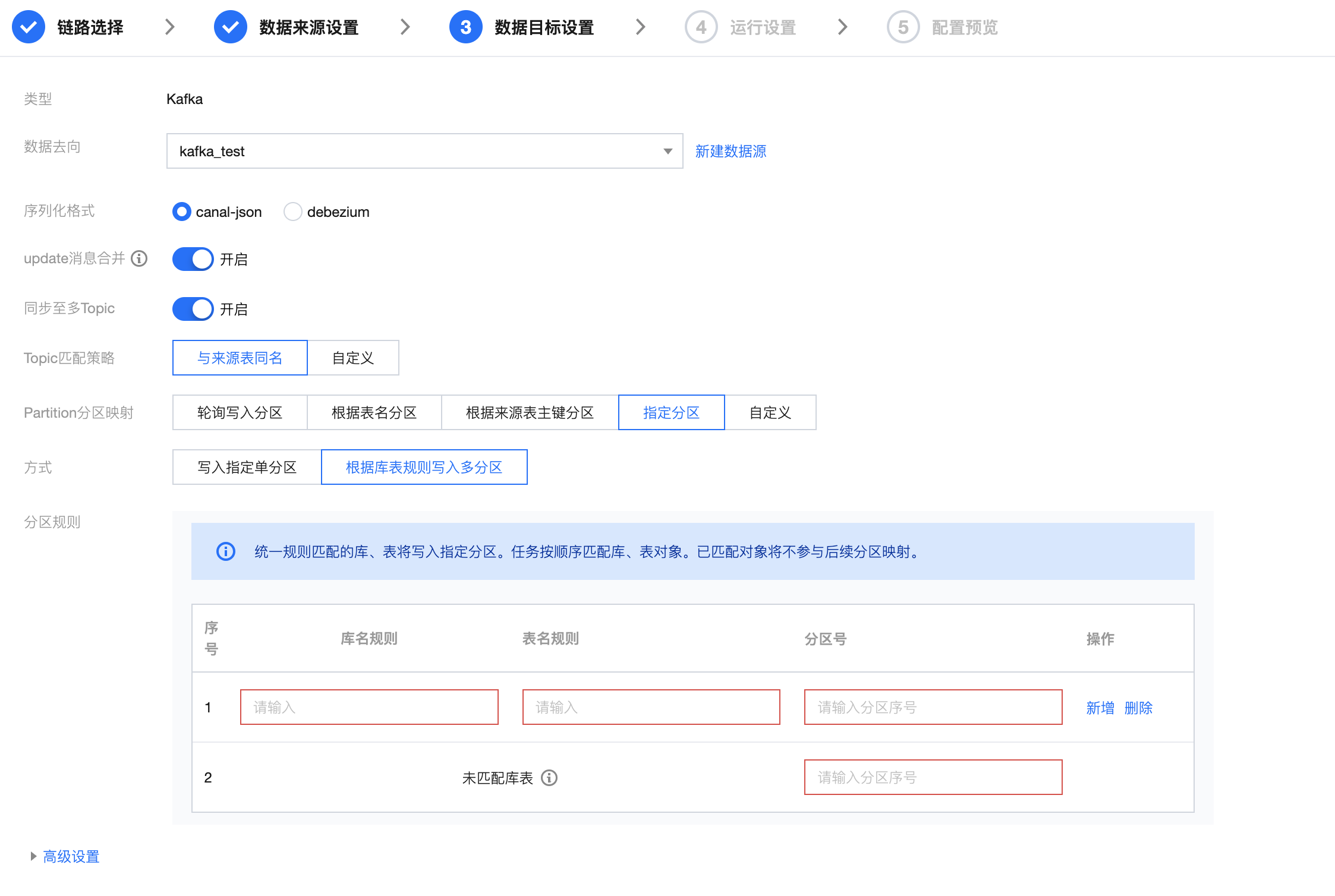
参数 | 说明 |
数据源 | 选择需要同步的目标数据源。Kafka 目标端数据源类型支持 Kafka、Ckafka。 |
序列化格式 | 支持 canal-json 和 debezium 两种格式 |
Update 消息合并 | 开关关闭:源端一条记录的一次 Update 变更,对应两条 Kafka 记录,分别为变更前和变更后的数据。 开关打开:源端一条记录的一次 Update 变更,对应一条 Kafka 记录,同时包含变更前和变更后的数据。 |
同步至多 Topic | 默认打开:此选项下可实现来源数据与目标 Topic 多对多映射,任务执行过程中将根据策略匹配对应 Topic 的名称。若Topic不存在时系统将根据 Topic 名匹配规则自动创建 Topic。 关闭:手动输入或者选择目标 Topic 名称,后续所有数据将统一写入该 Topic 内。 |
Topic 匹配策略 | 与来源表同名:默认使用与来源表同名的 Topic 。 自定义:根据定义策略规则匹配 Topic 。 |
分区规则 | 配置 topic partition 分区映射(轮询写入分区、根据表名分区、根据来源表主键分区、指定分区、自定义): 轮询写入分区:轮询(Round Robin)上游数据写入到每个 partition。 根据表名写入分区:根据上游数据中的表名 hash 映射写入每个 partition。 根据来源表主键分区:根据上游数据中的主键数据内容 hash 映射写入每个 partition。 指定分区: 写入指定单分区:输入分区序号,所有消息仅写入到固定分区。 根据表规则写入多分区:支持输入库、表正则进行对象匹配,符合匹配规则的对象写入到指定分区中,规则之间顺序执行,已匹配库表不参与后续规则匹配。 自定义:支持使用 “内置参数” 拼接写入分区规则,设定后将根据分区规则对应的值对消息进行 hash 分区。 |
高级设置(可选) | 可根据业务需求配置参数。 |
实时单表同步读取配置
1. 在数据集成页面左侧目录栏单击实时同步。
2. 在实时同步页面上方选择单表同步新建(可选择表单和画布模式)并进入配置页面。
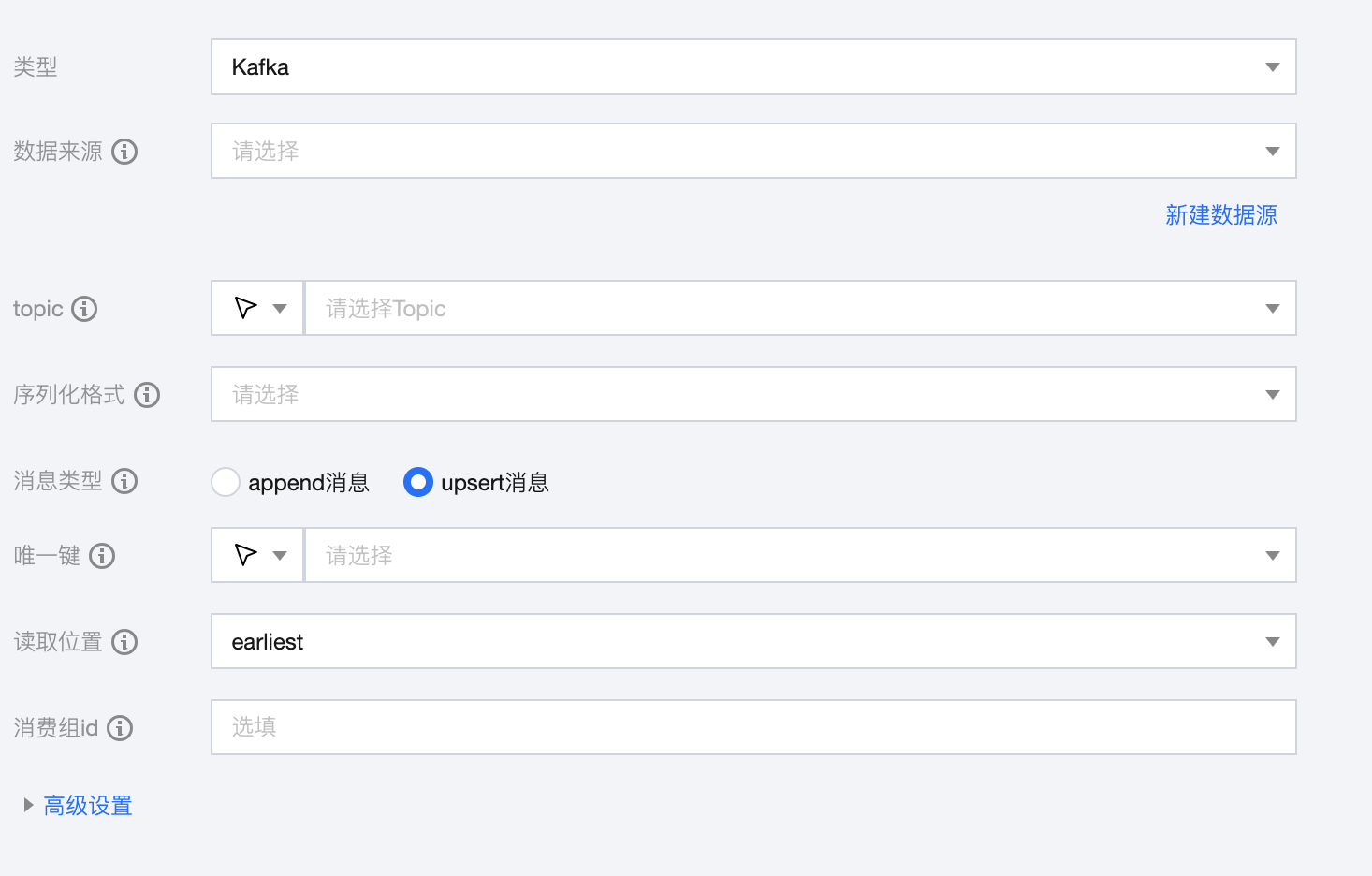
参数 | 描述 |
数据来源 | Kafka 读取端数据源类型支持 Kafka。Kafka 读取端数据源类型支持 Kafka、Ckafka。 |
Topic | Kafka 数据源中的 Topic。 |
序列化格式 | Kafka 消息序列化格式类型,支持:canal-json、ogg-json、json、avro、csv、raw。 注意: 当 Kafka 里的数据是嵌套 json 时,默认不支持同步,需要在高级参数里添加 source.nested.json.enabled=true。 该参数支持同步嵌套 json,但是会影响同步性能,非必要情况下不建议开启。 嵌套 json 示例:
添加字段时需要用 a->b 格式当做字段名,以上 json 示例对应的字段如下: 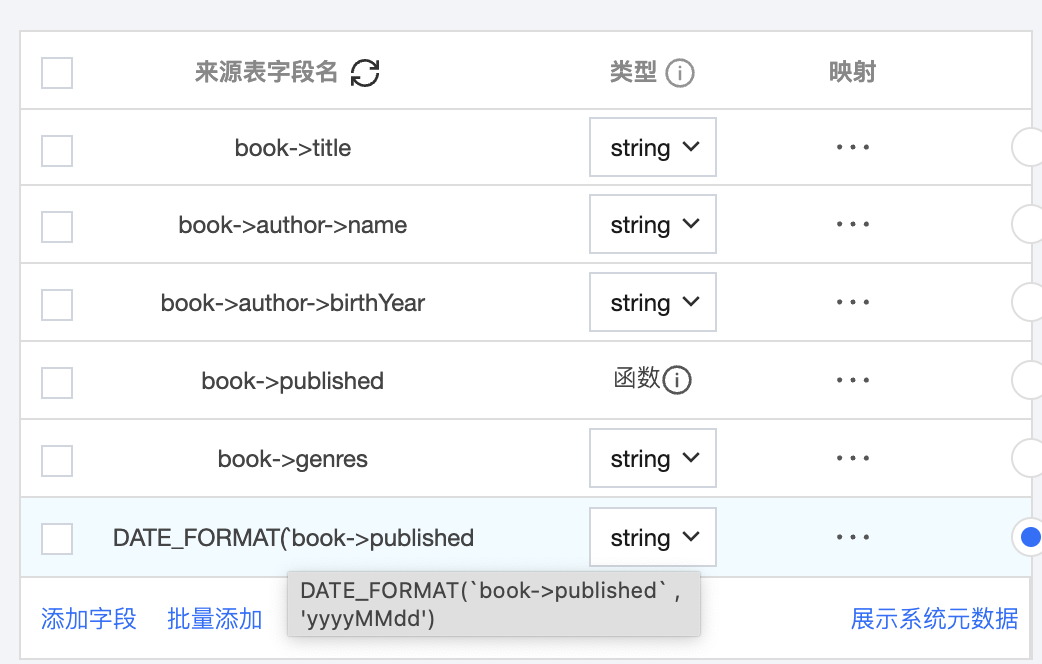 当需要对字段进行函数处理时,需要将字段名加上反引号``,例如`book->published` |
消息类型 | Append 消息:Kafka 内消息来源于 Append 消息流,通常消息中不携带唯一键。写入节点建议搭配 Append 写入模式。 Upsert 消息:Kafka 内消息来源于 Upsert 消息流,通常消息中携带唯一键,设置后消息可保证 Exactly-Once。写入节点建议搭配 Upsert 写入模式。 |
唯一键 | Upsert 写入模式下,需设置唯一键保证数据有序性 |
读取位置 | 启动同步任务时开始同步数据的起始位点。支持 earliest 和 latest |
消费组 ID | 请避免该参数与其他消费进程重复,以保证消费位点的正确性。如果不指定该参数,默认设定 group.id=WeData_ group_${任务id}。 |
高级设置(可选) | 可根据业务需求配置参数。 |
实时单表同步写入配置
1. 在数据集成页面左侧目录栏单击实时同步。
2. 在实时同步页面上方选择单表同步新建(可选择表单和画布模式)并进入配置页面。
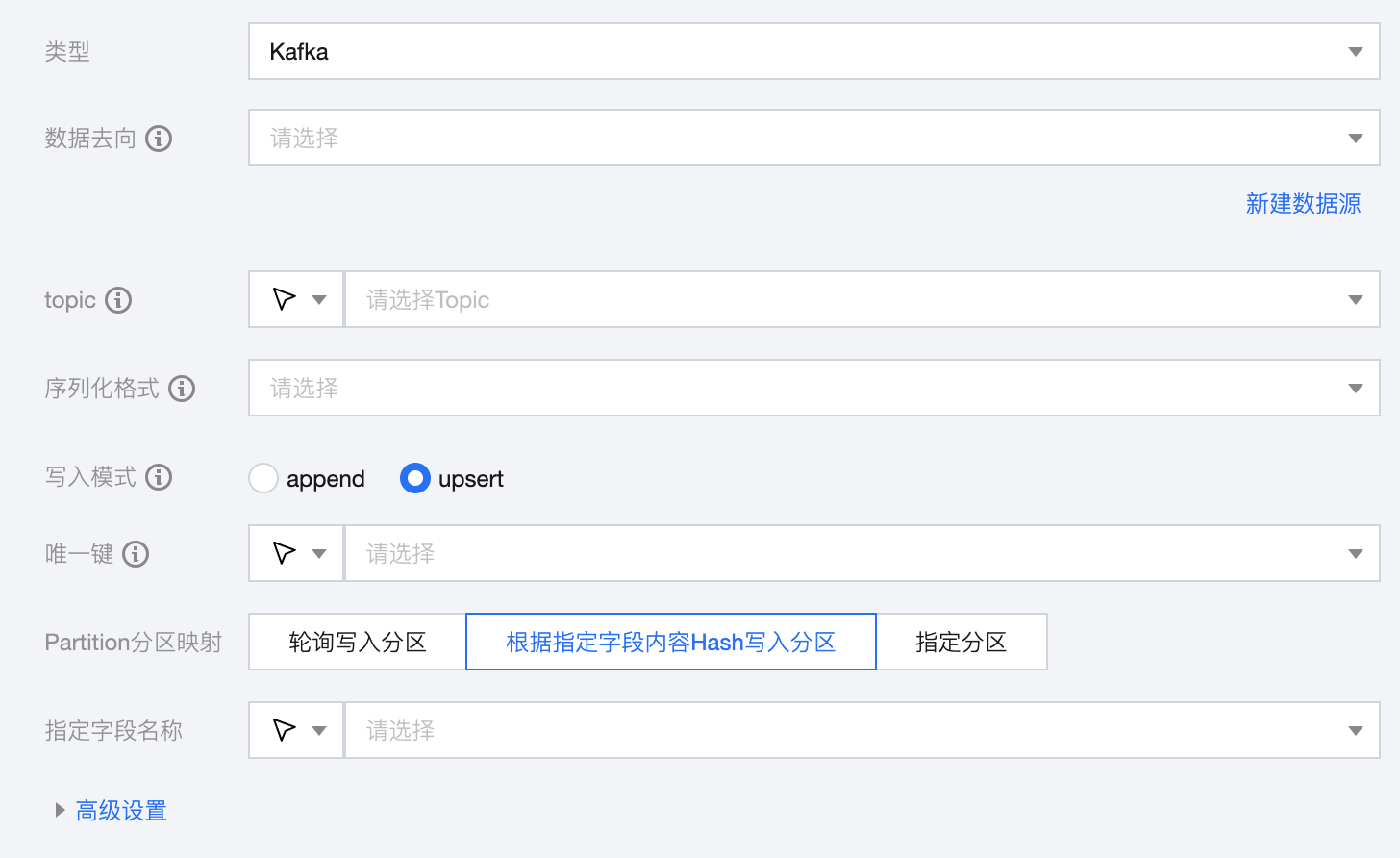
参数 | 描述 |
数据源 | Kafka 写入端数据源类型支持 Kafka。Kafka 目标端数据源类型支持 Kafka、Ckafka。 |
Topic | Kafka 数据源中的 Topic。 |
序列化格式 | Kafka 消息序列化格式类型,支持:canal-json、json、avro。 |
写入模式 | Upsert:更新写入。当主键不冲突时,可插入新行;当主键冲突时,则进行更新。适用于目标表有主键且需要根据源端数据实时更新的场景。会有一定的性能损耗。 Append:追加写入。无论是否有主键,以插入新行的方式追加写入数据,是否存在主键冲突取决于目标端。适用于无主键且允许数据重复的场景。无性能损耗。 |
唯一键 | Upsert 写入模式下,需设置唯一键保证数据有序性 |
Partition 分区映射 | 配置 topic partition 分区映射(轮询写入分区、根据指定字段内容 Hash 写入分区、指定分区): 轮询写入分区:轮询(Round Robin)上游数据写入到每个 partition。 根据指定字段内容 Hash : 写入分区:根据指定字段内容 Hash 映射写入每个 partition。 指定分区:输入分区序号,所有消息仅写入到固定分区。 |
高级设置(可选) | 可根据业务需求配置参数。 |
数据类型转换支持
内部类型 | Kafka 类型 |
SMALLINT | SMALLINT, TINYINT UNSIGNED, TINYINT UNSIGNED ZEROFILL |
INTEGER | INT, INTEGER, YEAR, SHORT, MEDIUMINT, SMALLINT UNSIGNED, SMALLINT UNSIGNED ZEROFILL |
BIGINT | BIGINT, INT UNSIGNED, MEDIUMINT UNSIGNED, MEDIUMINT UNSIGNED ZEROFILL, INT UNSIGNED ZEROFILL |
DECIMAL | BIGINT UNSIGNED, BIGINT UNSIGNED ZEROFILL, SERIAL, NUMERIC, NUMERIC UNSIGNED, NUMERIC UNSIGNED ZEROFILL, DECIMAL, DYNAMIC DECIMAL, DECIMAL UNSIGNED, DECIMAL UNSIGNED ZEROFILL, FIXED, FIXED UNSIGNED, FIXED UNSIGNED ZEROFILL |
FLOAT | FLOAT, FLOAT UNSIGNED, FLOAT UNSIGNED ZEROFILL |
DOUBLE | DOUBLE, DOUBLE UNSIGNED, DOUBLE UNSIGNED ZEROFILL, DOUBLE PRECISION, DOUBLE PRECISION UNSIGNED, ZEROFILL, REAL, REAL UNSIGNED, REAL UNSIGNED ZEROFILL |
TIMESTAMP | ATETIME, TIMESTAMP WITH LOCAL TIME ZONE, TIMESTAMP WITH TIME ZONE |
TIMESTAMP_WITH_TIMEZONE | TIMESTAMP, TIMESTAMP WITH LOCAL TIME ZONE, TIMESTAMP WITH TIME ZONE |
BLOB | BLOB, TINYBLOB, MEDIUMBLOB, LONGBLOB |
VARCHAR | JSON, VARCHAR, TEXT, TINYTEXT, MEDIUMTEXT, LONGTEXT |
附录:Canal-json/Debezium 数据格式样例
Canal-json
{"data": [{"id": "2","name": "scooter33","description": "Big 2-wheel scooter233","weight": "5.11"}],"database": "pacino99","es": 1589373560000,"id": 9,"isDdl": false,"mysqlType": {"id": "INTEGER","name": "VARCHAR(255)","description": "VARCHAR(512)","weight": "FLOAT"},"old": [{"weight": "5.12"}],"pkNames": ["id"],"sql": "","sqlType": {"id": 4,"name": 12,"description": 12,"weight": 7},"table": "products999","ts": 1589373560798,"type": "UPDATE"}
Debezium
{"schema": {"type": "struct","fields": [{"type": "struct","fields": [{"type": "int32","optional": false,"field": "id"},{"type": "string","optional": false,"field": "first_name"},{"type": "string","optional": false,"field": "last_name"},{"type": "string","optional": false,"field": "email"}],"optional": true,"name": "mysql-server-1.inventory2.customers2.Value","field": "before"},{"type": "struct","fields": [{"type": "int32","optional": false,"field": "id"},{"type": "string","optional": false,"field": "first_name"},{"type": "string","optional": false,"field": "last_name"},{"type": "string","optional": false,"field": "email"}],"optional": true,"name": "mysql-server-1.inventory2.customers2.Value","field": "after"},{"type": "struct","fields": [{"type": "string","optional": false,"field": "version"},{"type": "string","optional": false,"field": "connector"},{"type": "string","optional": false,"field": "name"},{"type": "int64","optional": false,"field": "ts_ms"},{"type": "boolean","optional": true,"default": false,"field": "snapshot"},{"type": "string","optional": false,"field": "db"},{"type": "string","optional": true,"field": "table"},{"type": "int64","optional": false,"field": "server_id"},{"type": "string","optional": true,"field": "gtid"},{"type": "string","optional": false,"field": "file"},{"type": "int64","optional": false,"field": "pos"},{"type": "int32","optional": false,"field": "row"},{"type": "int64","optional": true,"field": "thread"},{"type": "string","optional": true,"field": "query"}],"optional": false,"name": "io.debezium.connector.mysql.Source","field": "source"},{"type": "string","optional": false,"field": "op"},{"type": "int64","optional": true,"field": "ts_ms"}],"optional": false,"name": "mysql-server-1.inventory.customers.Envelope"},"payload": {"op": "c","ts_ms": 1465491411815,"before": null,"after": {"id": 12003,"first_name": "Anne322","last_name": "Kretchmar3222","email": "annek@noanswer.org3222"},"source": {"version": "1.9.6.Final","connector": "mysql","name": "mysql-server-1","ts_ms": 0,"snapshot": false,"db": "inventory333","table": "customers433","server_id": 0,"gtid": null,"file": "mysql-bin.000003","pos": 154,"row": 0,"thread": 7,"query": ""}}}



