数据集成提供了 DLC 实时整库和单表写入能力,本文为您介绍使用 DLC 进行实时数据同步的当前能力支持情况。
使用限制
当前仅支持 DLC Iceberg 格式的表。
选择 Upsert 模式同步时,DLC 表的表必须是 V2 表,并且开启设置 write.upsert.enabled=true。
选择 Upsert 模式同步时,必须指定主键,如果是一个分区表,分区字段也必须添加到主键中。
数据库环境准备
检查 WeData 是否有访问 DLC 的权限
1. 登录腾讯云控制台,进入 访问管理(CAM)页面。
2. 在左侧菜单中选择用户,找到您需要绑定策略的用户。
3. 单击该用户的名称,进入用户详情页。在权限栏搜索 QcloudWeDataExternalAccess,如果已经关联了该策略,下面步骤可以跳过。
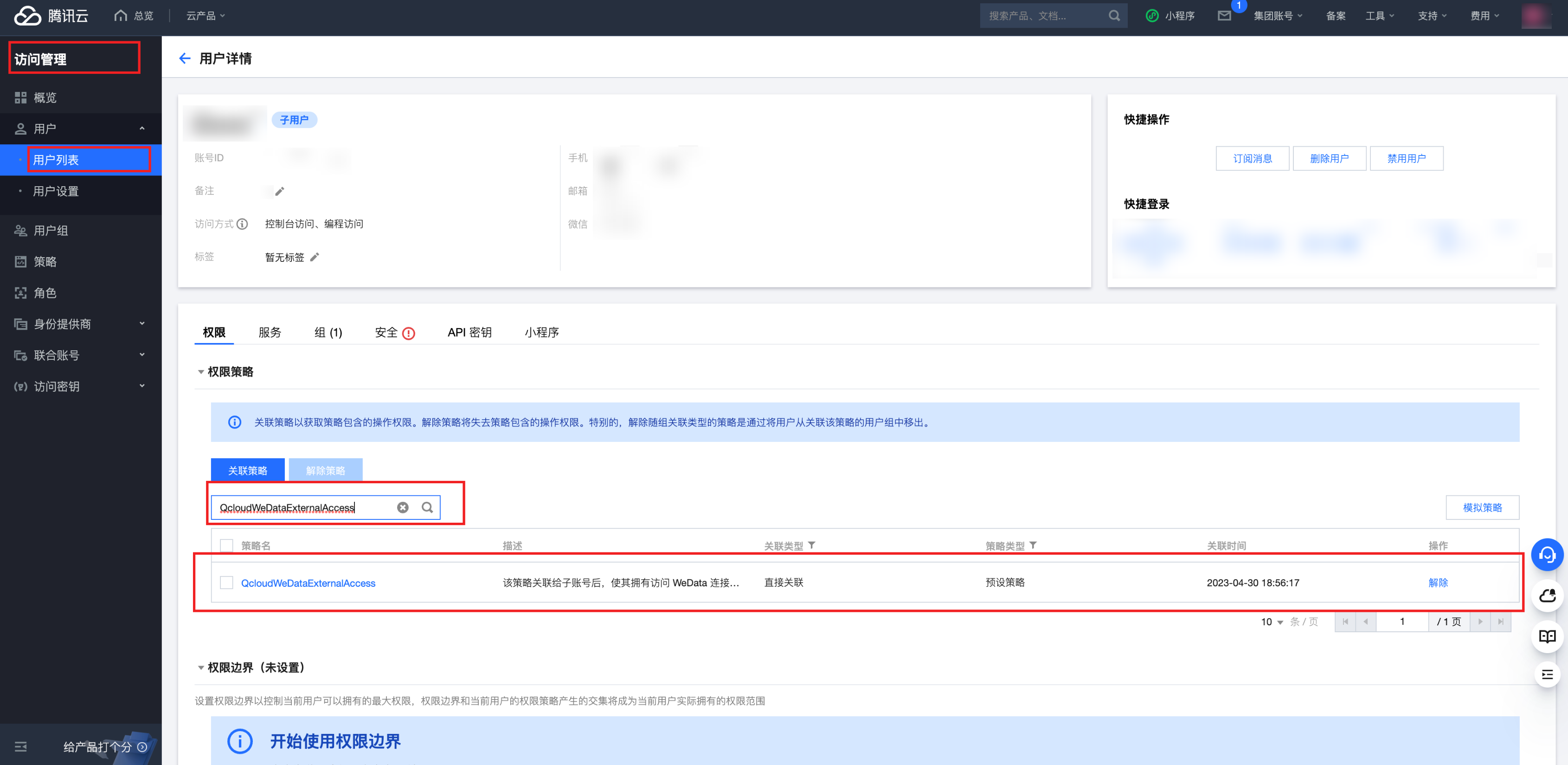
4. 在用户详情页中,找到权限管理模块下的关联策略 。
5. 单击关联策略中的新建关联按钮。选择从策略列表中选取策略关联,并输入 QcloudWeDataExternalAccess。
6. 勾选 QcloudWeDataExternalAccess,单击下一步按钮,完成策略绑定。
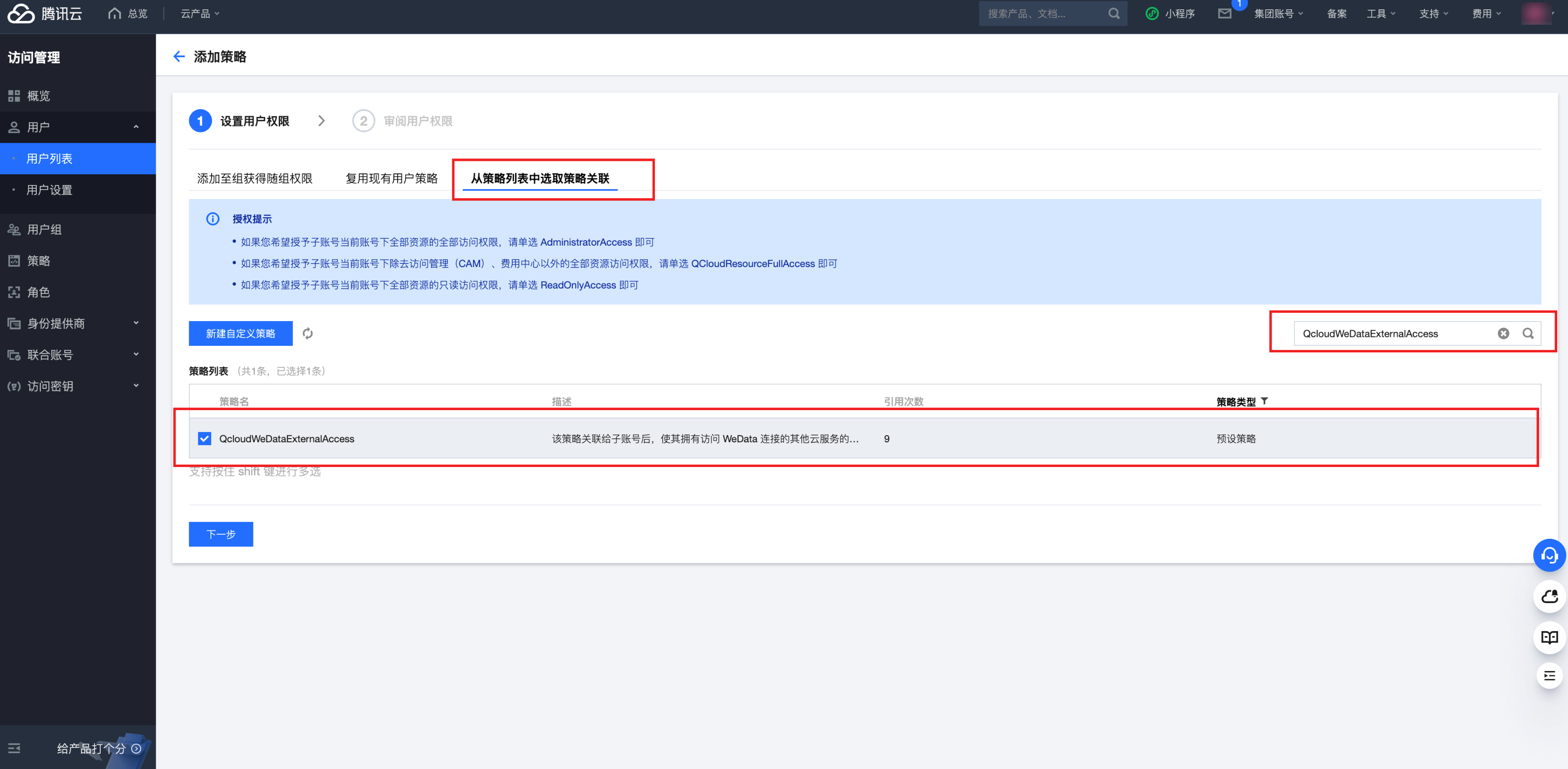
7. 绑定成功后,该用户即可使用 QcloudWeDataExternalAccess 策略中定义的权限。
检查表是 V1 表还是 V2 表(可选)
实时同步到 DLC,支持两种模式:Append 模式 和 Upsert 模式。其中 Upsert 模式必须为 Iceberg V2 表,并且开启设置 write.upsert.enabled=true。Append 模式支持 Iceberg V1 表以及 V2 表的 Append 模式( write.upsert.enabled=false)。
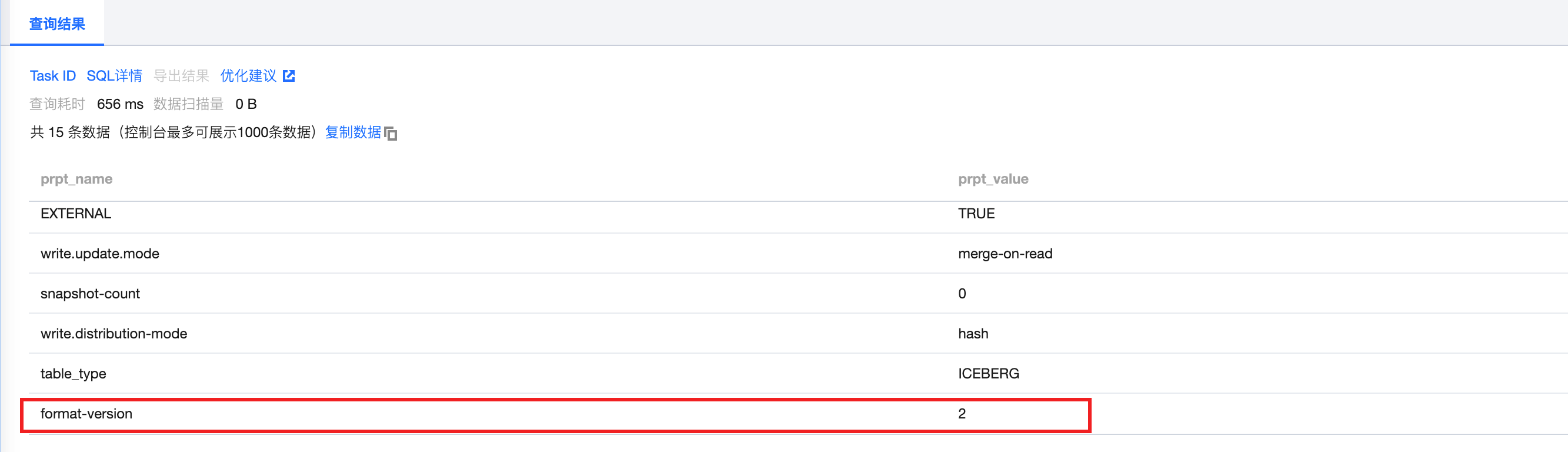
可使用下面命令查看创建的表属性:
SHOW TBLPROPERTIES `DataLakeCatalog`.`databases_name`.`table_name`;
创建 DLC 表(可选)
实时整库任务支持在任务运行期间自动创建 DLC 目标端不存在的目标表,也支持使用已存在的 DLC 目标表。用户可选择事先在 DLC 创建好目标表,也可选择让实时整库迁移任务自动建表。
1. 创建 V1 表
DLC 默认创建的表为 V1 表,V1 表不支持 Upsert 模式。建表语句参考下面:
CREATE TABLE IF NOT EXISTS `DataLakeCatalog`.`dbname`.`test_v1` (`id` int, `name` string, `ts` date) PARTITIONED BY (`ts`);
2. 创建 V2表
使用 upsert 模式写入 DLC,需要创建 V2 表,需要在建立表的时候指定,建表语句参考下面:
创建 V2 表,也一定要设置 'write.upsert.enabled' = 'true' 否则仍然是 Append 模式。
CREATE TABLE IF NOT EXISTS `DataLakeCatalog`.`dbname`.`test_v2` (`id` int, `name` string, `ts` date) PARTITIONED BY (`ts`) TBLPROPERTIES ('format-version' = '2', -- 创建 V2 表'write.upsert.enabled' = 'true', -- 写入时做 upsert 操作,只支持 V2 表'write.distribution-mode' = 'hash', -- 定义写入数据的分布,设置为hash,支持多并发写入'write.update.mode' = 'merge-on-read' -- 写入更新模式,在写入的时候做merge操作,只支持 V2 表)
3.
修改表属性(可选)
对于已经创建了的表,需要修改其属性,可以参考下面语法:
SHOW TBLPROPERTIES table_name [('property_name')]
下面是将已经存在的 V1 表改成 V2 表的示例:
ALTER TABLE`DataLakeCatalog`.`database_name`.`table_name`SETTBLPROPERTIES ('format-version' = '2','write.upsert.enabled' = 'true')
实时整库同步写入配置
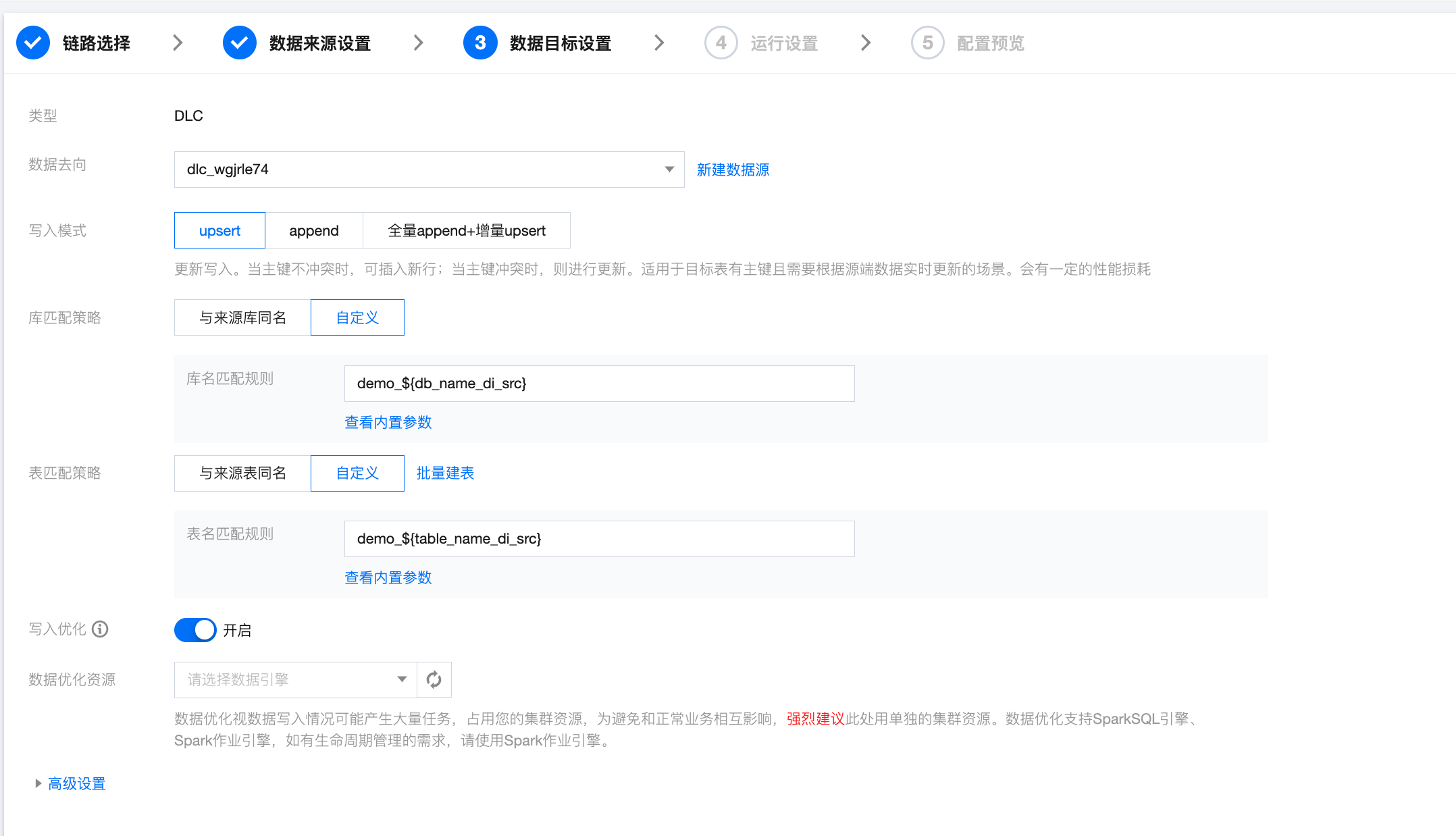
参数 | 说明 |
数据去向 | 选择需要同步的目标数据源。 |
写入模式 | Upsert:更新写入。当主键不冲突时,可插入新行;当主键冲突时,则进行更新。适用于目标表有主键且需要根据源端数据实时更新的场景。会有一定的性能损耗. Append:追加写入。无论是否有主键,以插入新行的方式追加写入数据,是否存在主键冲突取决于目标端。适用于无主键且允许数据重复的场景。无性能损耗。 全量 Append + 增量 Upsert:根据源端数据同步阶段自动切换数据写入方式,全量阶段采用 Append 写入提高性能,增量阶段采用 Upsert 写入进行数据实时更新。该模式当前仅支持来源端为 MySQL、TDSQL-C MySQL、TDSQL MySQL、Oracle、PostgreSQL 的数据源。 |
库/表匹配策略 | DLC 中数据库以及数据表对象的名称匹配规则。 |
写入优化 | 说明: 集成任务当前仅支持采用 DLC 写入优化的默认配置,用户如需修改相应配置,请前往 DLC 页面进行修改。 |
数据优化资源 | 数据优化视数据写入情况可能产生大量任务,占用您的集群资源,为避免和正常业务相互影响,强烈建议此处用单独的集群资源。数据优化支持 SuperSQL 引擎 > SparkSQL、SuperSQL 引擎 > Spark 作业,如有生命周期管理的需求,请使用 SuperSQL 引擎 > Spark 作业引擎。 |
高级设置 | 可根据业务需求配置参数。 |
实时分库分表同步写入配置
与实时整库同步写入配置项一致。
实时单表同步写入配置
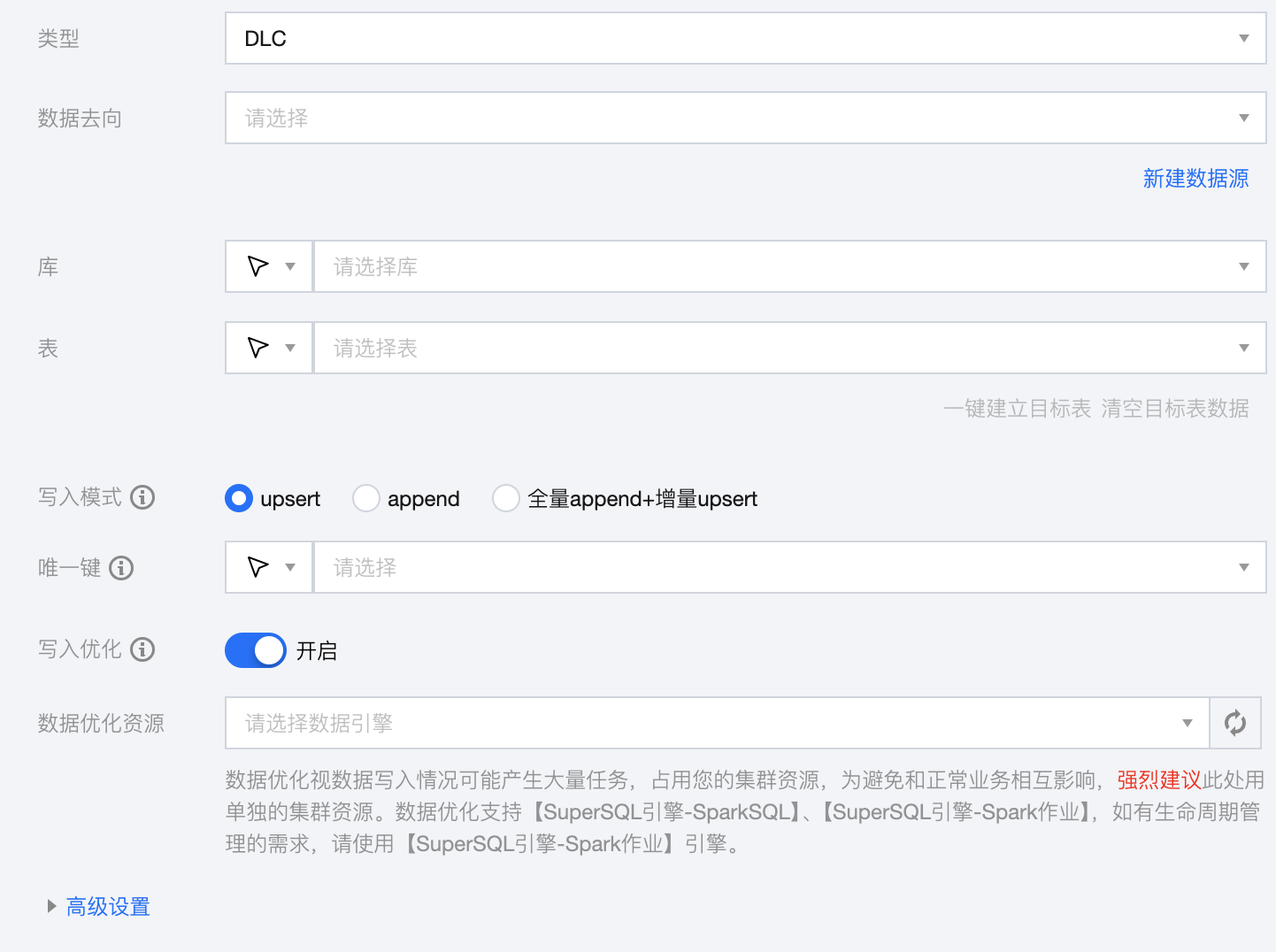
参数 | 说明 |
数据去向 | 需要写入的 DLC 数据源。 |
库 | 支持选择、或者手动输入需写入的库名称 默认将数据源绑定的数据库作为默认库,其他数据库需手动输入库名称。 当数据源网络不联通导致无法直接拉取库信息时,可手动输入数据库名称。在数据集成网络连通的情况下,仍可进行数据同步。 |
表 | 支持选择、或者手动输入需写入的表名称。 当数据源网络不联通导致无法直接拉取表信息时,可手动输入表名称。在数据集成网络连通的情况下,仍可进行数据同步。 |
写入模式 | DLC 实时同步写入支持两三种模式: Upsert:更新写入。当主键不冲突时,可插入新行;当主键冲突时,则进行更新。适用于目标表有主键且需要根据源端数据实时更新的场景。会有一定的性能损耗。 Append:追加写入。无论是否有主键,以插入新行的方式追加写入数据,是否存在主键冲突取决于目标端。适用于无主键且允许数据重复的场景。无性能损耗。 全量 Append + 增量 Upsert:根据源端数据同步阶段自动切换数据写入方式,全量阶段采用 Append 写入提高性能,增量阶段采用 Upsert 写入进行数据实时更新。该模式当前仅支持来源端为 MySQL、TDSQL-C MySQL、TDSQL MySQL、Oracle、PostgreSQL 的数据源。 |
唯一键 | Upsert 写入模式下,需设置唯一键保证数据有序性,支持多选。 |
写入优化 | 说明: 集成任务当前仅支持采用 DLC 写入优化的默认配置,用户如需修改相应配置,请前往 DLC 页面进行修改。 |
数据优化资源 | 数据优化视数据写入情况可能产生大量任务,占用您的集群资源,为避免和正常业务相互影响,强烈建议此处用单独的集群资源。数据优化支持 SuperSQL 引擎 > SparkSQL、SuperSQL 引擎 > Spark 作业,如有生命周期管理的需求,请使用 SuperSQL 引擎 > Spark 作业引擎。 |
高级设置 | 可根据业务需求配置参数。 |
支持的字段类型
内部类型 | Iceberg 类型 |
CHAR | STRING |
VARCHAR | STRING |
STRING | STRING |
BOOLEAN | BOOLEAN |
BINARY | FIXED(L) |
VARBINARY | BINARY |
DECIMAL | DECIMAL(P,S) |
TINYINT | INT |
SMALLINT | INT |
INTEGER | INT |
BIGINT | LONG |
FLOAT | FLOAT |
DOUBLE | DOUBLE |
DATE | DATE |
TIME | TIME |
TIMESTAMP | TIMESTAMP |
TIMESTAMP_LTZ | TIMESTAMPTZ |
INTERVAL | - |
ARRAY | LIST |
MULTISET | MAP |
MAP | MAP |
ROW | STRUCT |
RAW | - |
DLC 分区设置
分区说明
1. 整库迁移、分库分表任务,需开启自动建表,并在数据目标设置高级参数,进行如下格式的分区设置:
分区表1:分区字段1:分区策略1|分区表2:分区字段1,分区字段2:分区策略1,分区策略2
示例:sink.partition.rules=test1:age:bucket[8]|test2:date:year|test3:ts_wedata_di:day
上面表示对表名为 test1的表按 age 字段进行 bucket[8]分区,对表名为test2的表按date字段进行按年分区;对表名为 test3的表按 ts_wedata_di 系统元数据字段进行按天分区。
2. 多个表按“|”分隔,按先后顺序对表进行分区匹配,对同一个表设置多次分区仅第一次生效。
3. 同一个表一次可以设置多个分区字段,结果成功与否按DLC的返回结果处理。
4. 当前 bucket 及 truncate 后面的长度设置不可省略,暂时未做字段存在性及类型兼容性校验,表名的匹配规则按sink表名的匹配规则进行处理,即无论 source 表是什么,只要对应的 sink 表的表名满足分区规则的表名设置就表示匹配上,进而进行分区。
5. 如果第一项匹配成功,但类型不合适,后续仍不再匹配。
支持的分区函数
注意:
暂未对分区字段类型进行校验,如不成功,则会创建表失败。
分区函数 | 效果描述 | 支持的原字段数据类型 | 分区字段数据类型 |
identity | 原值 | 任何基础数据类型 | 与原字段数据类型一致 |
bucket[N] | 对原字段数据值按 N 取模进行 Hash | int, long, decimal, date, time, timestamp, timestamptz, string, uuid, fixed, binary | int |
truncate[W] | 对原字段数据值按宽度W进行截断 | int, long, decimal, string | 和原字段数据类型一样 |
year | 从 date 或 timestamp 类型的原字段,解析出 year | date, timestamp, timestamptz | int |
month | 从 date 或 timestamp 类型的原字段,解析出 month | date, timestamp, timestamptz | int |
day | 从 date 或 timestamp 类型的原字段,解析出 day | date, timestamp, timestamptz | int |
hour | 从 timestamp 类型的原字段,解析出 hour | timestamp, timestamptz | int |
常见问题
同步增量数据( changlog 数据)到 DLC 时报错
错误信息:
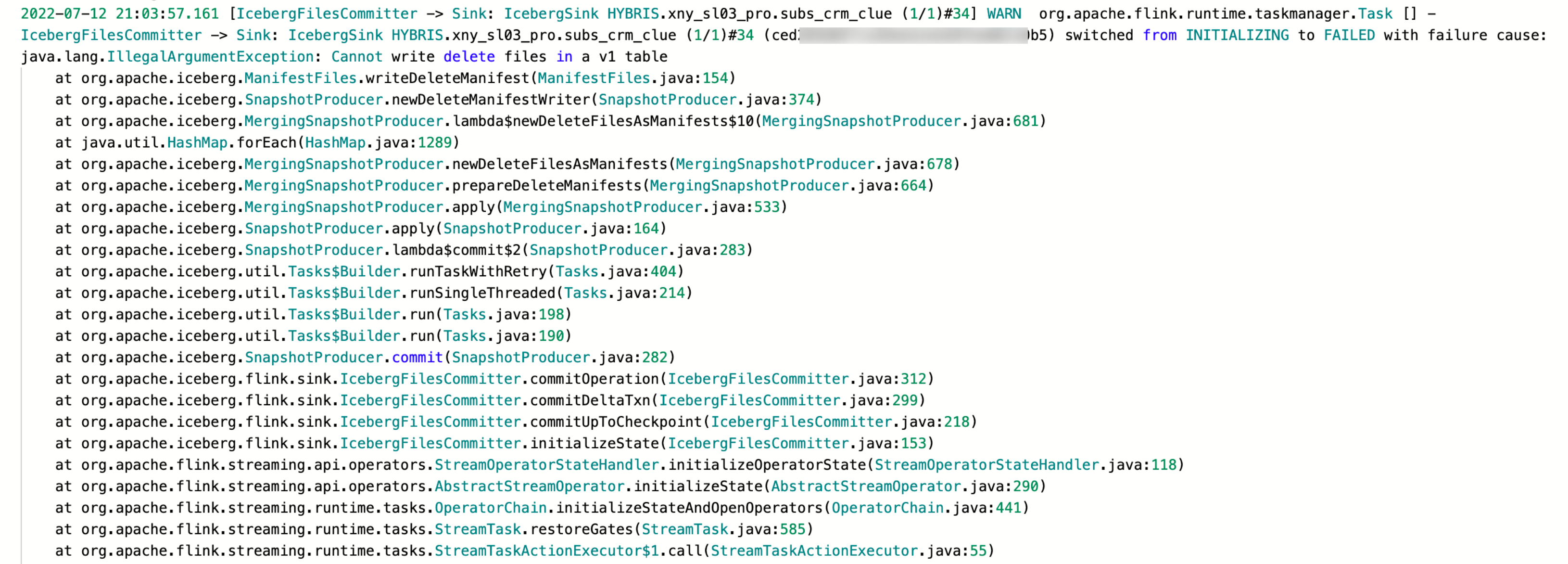
问题原因:
DLC 的表是 V1 表不支持 changlog 数据。
解决方法:
1. 修改 DLC 表为 V2 表和开启 Upsert 支持。
2. 修改表支持 Upsert:ALTER TABLE tblname SET TBLPROPERTIES ('write.upsert.enabled'='true')。
3. 修改表为 V2 表:ALTER TABLE tblname SET TBLPROPERTIES ('format-version'='2')。
显示表设置的属性是否成功 show tblproperties tblname。
Cannot write incompatible dataset to table with schema
错误详情:
Caused by: java.lang.IllegalArgumentException: Cannot write incompatible dataset to table with schema:* mobile should be required, but is optionalat org.apache.iceberg.types.TypeUtil.checkSchemaCompatibility(TypeUtil.java:364)at org.apache.iceberg.types.TypeUtil.validateWriteSchema(TypeUtil.java:323)
错误原因:
用户建 DLC 表时,字段设置了 NOT NULL 约束。
解决办法:
建表时不要设置 NOT NULL 约束。
同步 mysql2dlc,报数组越界
问题详情:
java.lang.ArrayIndexOutOfBoundsException: 1at org.apache.flink.table.data.binary.BinarySegmentUtils.getLongMultiSegments(BinarySegmentUtils.java:736) ~[flink-table-blink_2.11-1.13.6.jar:1.13.6]at org.apache.flink.table.data.binary.BinarySegmentUtils.getLong(BinarySegmentUtils.java:726) ~[flink-table-blink_2.11-1.13.6.jar:1.13.6]at org.apache.flink.table.data.binary.BinarySegmentUtils.readTimestampData(BinarySegmentUtils.java:1022) ~[flink-table-blink_2.11-1.13.6.jar:1.13.6]at org.apache.flink.table.data.binary.BinaryRowData.getTimestamp(BinaryRowData.java:356) ~[flink-table-blink_2.11-1.13.6.jar:1.13.6]at org.apache.flink.table.data.RowData.lambda$createFieldGetter$39385f9c$1(RowData.java:260) ~[flink-table-blink_2.11-1.13.6.jar:1.13.6]
错误原因:
时间字段做主键导致的问题。
解决方法:
1. 不用时间字段做主键。
2. 用户还是需要时间字段保证唯一性,建议用户在 DLC 新增一个冗余字符串字段,将上游的时间字段使用函数转换后映射到冗余字段。
DLC 任务报不是一个 Iceberg 表
错误信息:

错误原因:
1. 可以让用户在 DLC 执行语句查看表到底是什么类型。
2. 语句:desc formatted 表名。
3. 可以查看表类型。
解决办法:
选择正确的引擎建 Iceberg 类型的表。
flink sql 字段顺序跟 DLC 目标表字段不一致导致报错
解决方法:
不修改任务表字段顺序。



