支持版本
支持 ClickHouse 20.7+ 版本
使用限制
1. 支持使用 JDBC 连接 ClickHouse,且仅支持使用 JDBC Statement 读取数据。
2. 支持筛选部分列、列换序等功能,您可以自行填写列。
ClickHouse 离线单表读取节点配置
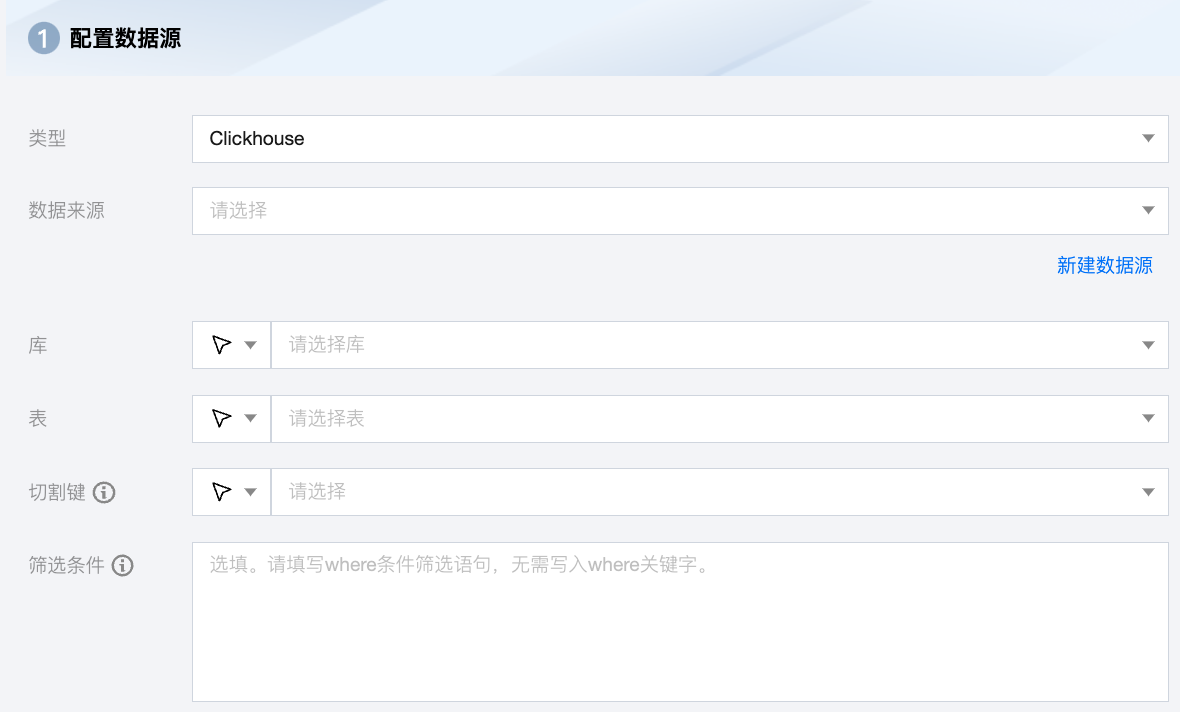
参数 | 说明 |
数据来源 | 可用的 Clickhouse 数据源。 |
库 | 支持选择、或者手动输入需读取的库名称 默认将数据源绑定的数据库作为默认库,其他数据库需手动输入库名称。 当数据源网络不联通导致无法直接拉取库信息时,可手动输入数据库名称。在数据集成网络连通的情况下,仍可进行数据同步。 |
表 | 支持选择、或者手动输入需读取的表名称。 |
切割键 | ClickHouse 进行数据抽取时,如果指定 splitPk,表示您希望使用 splitPk 代表的字段进行数据分片,数据同步因此会启动并发任务进行数据同步,提高数据同步的效能。 您可以将源数据表中某一列作为切割键,建议使用主键或有索引的列作为切割键,仅支持类型为整型的字段。
读取数据时,根据配置的字段进行数据分片,实现并发读取,可以提升数据同步效率。 |
筛选条件(选填) | 在实际业务场景中,通常会选择当天的数据进行同步,将 where 条件指定为 gmt_create>$bizdate。 where 条件可以有效地进行业务增量同步。 如果不填写 where 语句,包括不提供 where 的 key 或 value,数据同步均视作同步全量数据。 |
ClickHouse 离线单表写入节点配置
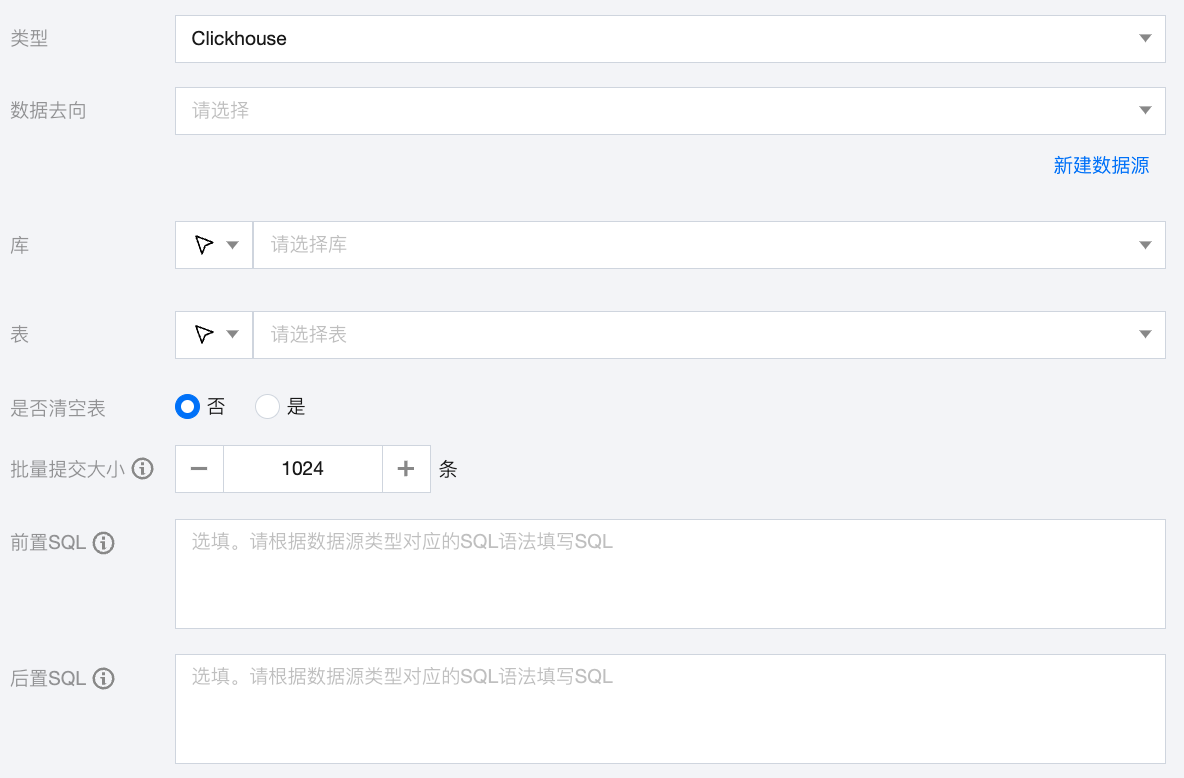
参数 | 说明 |
数据去向 | 需要写入的 Clickhouse 数据源。 |
库 | 支持选择、或者手动输入需写入的库名称 默认将数据源绑定的数据库作为默认库,其他数据库需手动输入库名称。 当数据源网络不联通导致无法直接拉取库信息时,可手动输入数据库名称。在数据集成网络连通的情况下,仍可进行数据同步。 |
表 | 支持选择、或者手动输入需写入的表名称 当数据源网络不联通导致无法直接拉取表信息时,可手动输入表名称。在数据集成网络连通的情况下,仍可进行数据同步。 |
是否清空表 | 在写入该 Clickhouse 数据表前可以手动选择是否清空该数据表。 |
批量提交大小 | 一次性批量提交的记录数大小,该值可以极大减少数据同步系统与 Clickhouse 的网络交互次数,并提升整体吞吐量。如果该值设置过大,会导致数据同步运行进程 OOM 异常。 |
前置 SQL(选填) | 执行同步任务之前执行的 SQL 语句,根据数据源类型对应的正确 SQL 语法填写 SQL,例如,执行前清空表中的旧数据(truncate table tablename)。 |
后置 SQL(选填) | 执行同步任务之后执行的 SQL 语句,根据数据源类型对应的正确 SQL 语法填写 SQL,例如,加上某一个时间戳 alter table tablename add colname timestamp DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP。 |
数据类型转换支持
读取
ClickHouse 数据类型 | 内部类型 |
Integer、Smallint、Tinyint、Bigint | Long |
Float32、Flout64、Decimal | Double |
String、Array、Null | String |
Date32、Datetime64 | Date |
写入
内部类型 | ClickHouse 数据类型 |
Long | Integer、Smallint、Tinyint、Bigint |
Double | Float32、Flout64、Decimal |
String | String、Array |
Date | Date32、Datetime64 |
常见问题
delete 数据后插入相同数据失败
问题原因:
对副本表 insert 的数据会划分为数据块。每个数据块会生成 block_id ,存储在 zookeeper 相应表目录的 block 子目录下。
数据块根据 block_id 自动去重,对于被多次写的相同数据块(大小相同且具有相同顺序的相同行的数据块),该块仅会写入一次。
因此同样的一份数据,多次 insert 副本表,只有第一次会写入数据。当对这份数据进行 delete 操作后,数据成功删除了,但是存在 zookeeper 上的 block_id 没有被一并删除。导致之后对这份数据进行 insert,会被表引擎判断为重复数据,而被略过,使数据没有落地到表里面,即查不出来这份数据。
解决方案:
设置 set insert_deduplicate=0 临时关闭去重机制,找到 zookeeper 下对应的 block_id ,手动删除这个 block_id。建议用 truncate table 删除数据。
ClickHouse 脚本 Demo
如果您配置离线任务时,使用脚本模式的方式进行配置,您需要在任务脚本中,按照脚本的统一格式要求编写脚本中的 reader 参数和 writer 参数。
"job": {"content": [{"reader": {"parameter": {"password": "******","column": [ //列名"id","name"],"connection": [{"jdbcUrl": ["jdbc:clickhouse://ip:8123/source_database"],"table": [ //源表"source_database.source_table"]}],"where": "id>10", //筛选条件"splitPk": "id", //切割键"username": "root"},"name": "clickhousereader"},"transformer": [],"writer": {"parameter": {"postSql": [ //后置sql""],"password": "******","column": [ //列名"id","name"],"connection": [{"jdbcUrl": "jdbc:clickhouse://172.1.1.1:1433/sink_database?compress=111","table": [ //目标表"sink_database.sink_table"]}],"batchSize": 1024, //批量提交大小"username": "root","preSql": [ //前置sql""]},"name": "clickhousewriter"}}],"setting": {"errorLimit": { //脏数据阈值"record": 0},"speed": {"byte": -1, //不限制同步速度,正整数表示设置最大传输速度 byte/s"channel": 1 //并发数量}}}



