支持版本
支持 HDFS 2.x、3.x 版本。
使用限制
离线读取
HDFS Reader 支持以下功能:
支持TXT、ORC、PARQUET、CSV、JSON 格式的文件,且要求文件内容存放的是一张逻辑意义上的二维表。
支持多种类型数据读取(使用 String 表示),支持列裁剪,支持列常量。
仅支持 * 和 ? 作为文件通配符,指定通配符后将遍历多个文件信息。
多个 File 可以支持并发读取。
目前插件中 Hive 版本为2.3.7,Hadoop 版本为3.2.3。
说明:
HDFS Reader 暂不支持单个 File 多线程并发读取,此处涉及到单个 File 内部切分算法。
离线写入
使用 HDFS Writer 时,请注意以下事项:
1. 目前 HDFS Writer 仅支持 TXT、ORC、PARQUET、CSV 四种格式的文件。
2. 由于 HDFS 是文件系统,不存在 Schema 的概念,因此不支持对部分列写入。
HDFS 离线单表读取节点配置
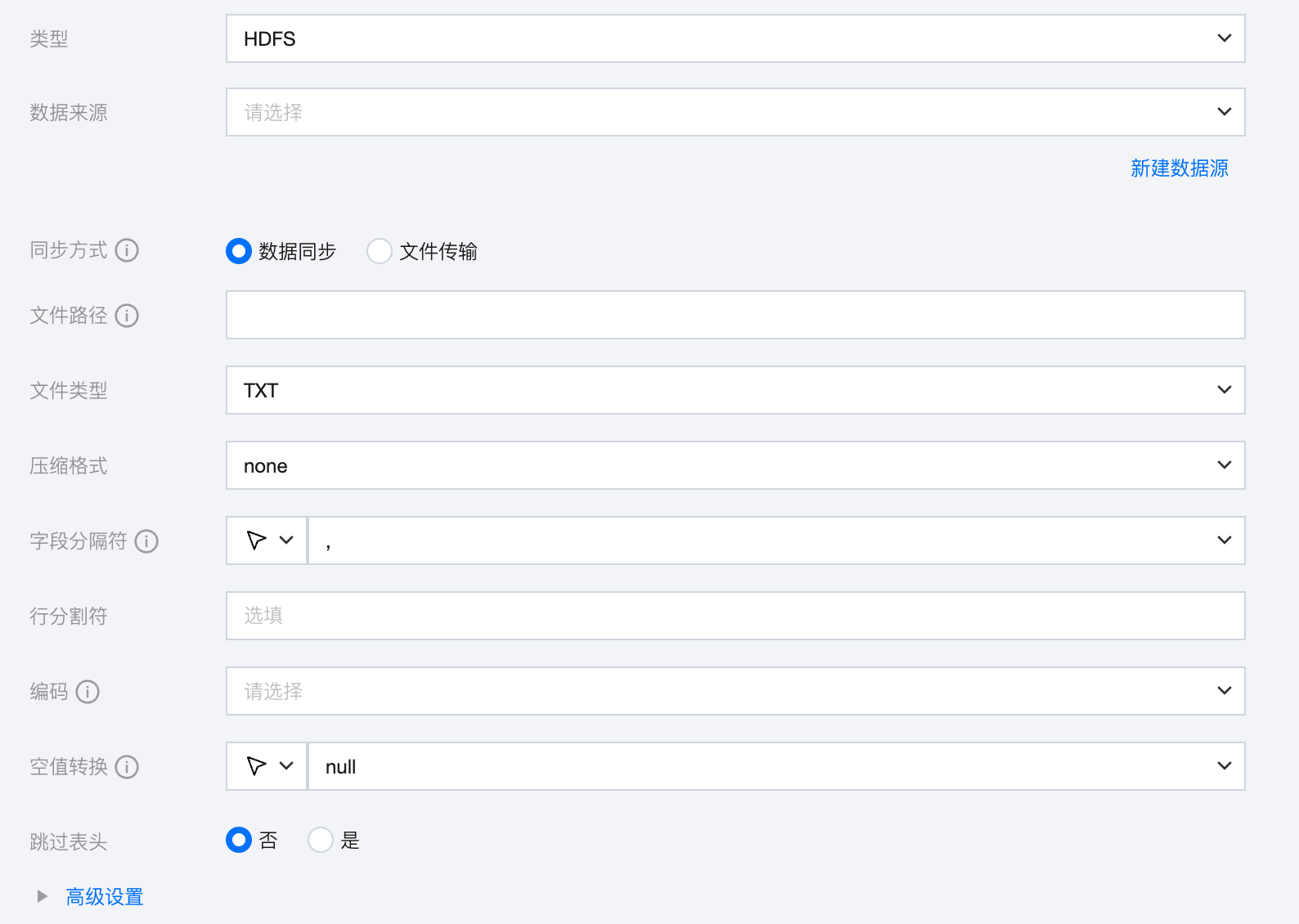
参数 | 说明 |
数据来源 | 选择当前项目中可用的 HDFS 数据源。 |
同步方式 | HDFS 支持两种同步方式: 数据同步:解析结构化数据内容,按字段关系进行数据内容映射与同步。 文件传输:不做内容解析传输整个文件,可应用于非结构化数据同步。 注意: 文件传输仅支持来源端、目标端均为文件类型(COS/HDFS/SFTP/FTP)的数据源,且来源端、目标端同步方式均需要为文件传输。 |
文件路径 | 文件系统的路径信息。路径支持使用‘*’作为通配符,指定通配符后将遍历多个文件信息。例如,指定/代表读取/目录下所有的文件,指定 /bazhen/ 代表读取 bazhen 目录下所有的文件。HDFS 目前只支持 * 和 ? 作为文件通配符,语法类似于通常的 Linux 命令行文件通配符。 |
文件类型 | HDFS 支持五种文件类型:TXT、ORC、PARQUET、CSV、JSON TXT:表示 TextFile 文件格式。 ORC:表示 ORCFile 文件格式。 PARQUET:表示普通 Parquet 文件格式。 CSV:表示普通 HDFS 文件格式(逻辑二维表)。 JSON:表示 JSON 文件格式。 |
压缩格式 | 目前支持:none、deflate、gzip、bzip2、lz4、snappy。 由于 snappy 目前没有统一的 stream format,数据集成目前仅支持最主流的 hadoop-snappy(hadoop 上的 snappy stream format)和 framing-snappy(google 建议的 snappy stream format)。 |
字段分隔符 | 读取的字段分隔符,HDFS 在读取 TXT 、CVS 数据时,需要指定字段分隔符,如果不指定默认为逗号(,)。 其他可用分隔符:' \\t ' 、' \\u001 ' 、' | '、' 空格 ' 、 ' ;' ' , '。 如果您想将每一行作为目的端的一列,分隔符请使用行内容不存在的字符。例如,不可见字符 \\u0001。 说明: 仅文件格式为 TXT 、CVS 支持填写。 |
行分割符(选填) | linux 默认是 \\n , windows 默认是 \\r\\n,手填支持单个字符作为行分割符。 说明: 仅文件格式为 TXT 、CVS 支持填写。 |
编码 | 读取文件的编码配置。支持 utf8 和 gbk 两种编码。 |
空值转换 | 读取时,将指定字符串转为 NULL。 支持下拉选择或手动输入,下拉选择支持:空字符串、空格、\\n、\\0、null |
跳过表头 | 否:读取时不包含表头。 是:读取时包含表头。 说明: 仅文件格式为 TXT 、CVS 支持填写。 当来源端包含表头,且选择不跳过表头时,目标端建议选择不包含表头,否则可能导致表头数据重复。 |
HDFS 离线单表写入节点配置
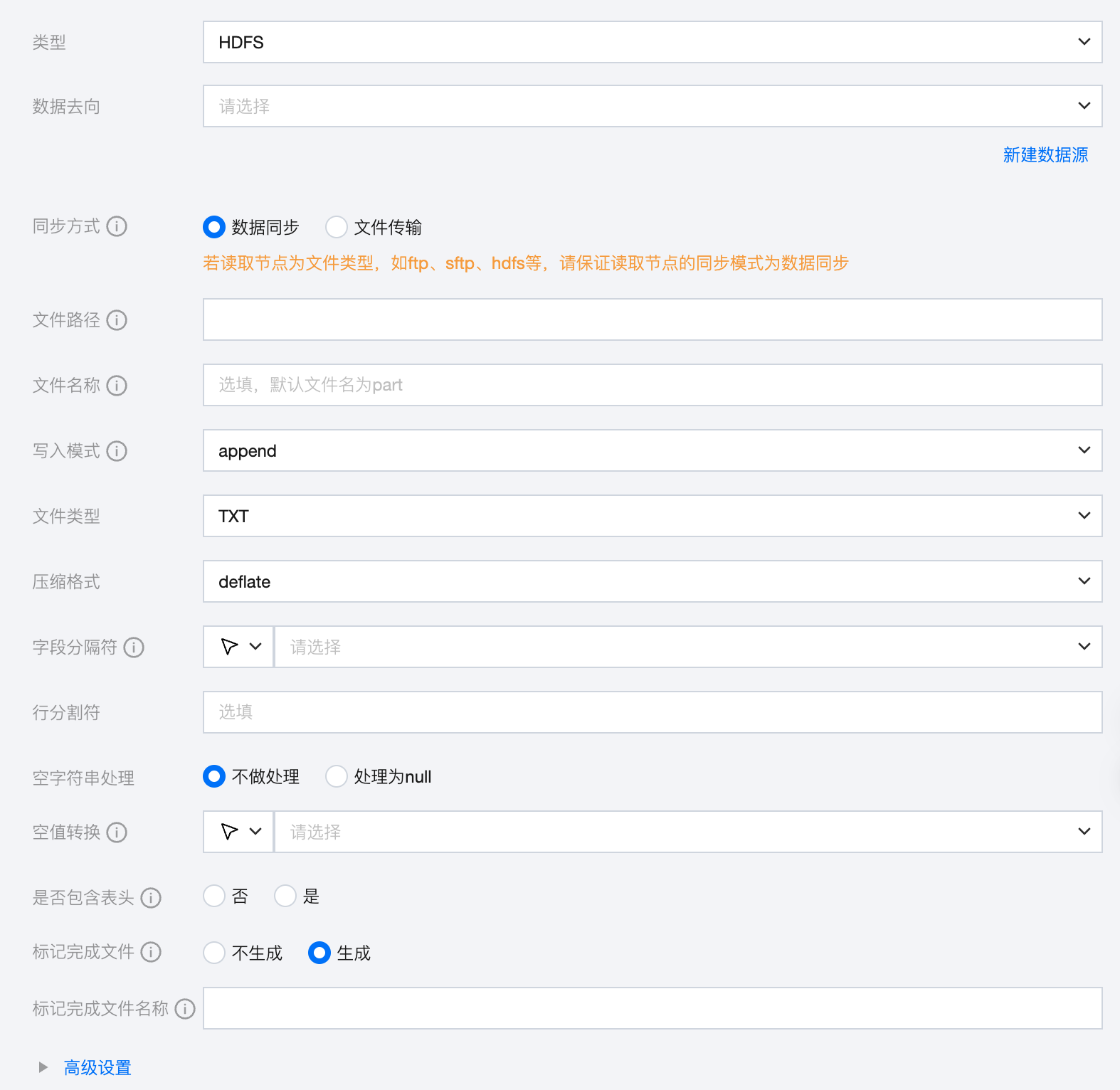
参数 | 说明 |
数据去向 | 选择当前项目中可用的 HDFS 数据源。 |
同步方式 | HDFS 支持两种同步方式: 数据同步:解析结构化数据内容,按字段关系进行数据内容映射与同步。 文件传输:不做内容解析传输整个文件,可应用于非结构化数据同步。 注意:文件传输仅支持来源端、目标端均为文件类型(COS/HDFS/SFTP/FTP)的数据源,且来源端、目标端同步方式均需要为文件传输 |
文件路径 | 文件系统的路径信息。路径支持使用‘*’作为通配符,指定通配符后将遍历多个文件信息。 |
文件名称 | 选填,默认文件名称为 part。 |
写入模式 | HDFS 支持三种写入模式: append:写入前不做任何处理,直接使用 filename 写入,保证文件名不冲突。 nonConflict:文件名重复时报错。 overwrite:写入前清理以文件名为前缀的所有文件,例如,"fileName": "abc",将清理对应目录所有 abc 开头的文件。 |
文件类型 | HDFS 支持四种文件类型:TXT、ORC、PARQUET、CSV TXT:表示 TextFile 文件格式。 ORC:表示 ORCFile 文件格式。 PARQUET:表示普通 Parquet 文件格式。 CSV:表示普通 HDFS 文件格式(逻辑二维表)。 |
压缩格式 | 目前支持:none、deflate、gzip、bzip2、lz4、snappy。 由于 snappy 目前没有统一的 stream format,数据集成目前仅支持最主流的 hadoop-snappy(hadoop 上的 snappy stream format)和 framing-snappy(google 建议的 snappy stream format)。 |
字段分隔符 | HDFS 写入时的字段分隔符,需要您保证与创建的 HDFS 表的字段分隔符一致,否则无法在 HDFS 表中查到数据。可选:'\\t ' 、 ' \\u001 ' 、' | '、' 空格 ' 、',' 、';'、'\\u005E\\u0001\\u005E'。 说明: 仅文件格式为 TXT 、CVS 支持填写。 |
行分割符(选填) | linux 默认是 \\n , windows 默认是 \\r\\n,手填支持单个字符作为行分割符。 说明: 仅文件格式为 TXT 、CVS 支持填写。 |
空字符串处理 | 不做处理:写入时,不处理空字符串。 处理为 NULL:写入时,将空字符串处理为 NULL。 |
空值转换 | 写入时,将 NULL 转为指定字符串。NULL 代表未知或不适用的值,不同于0、空字符串或其他数值。 说明: 仅文件格式为 TXT 、CVS 支持选择。 |
是否包含表头 | 否:写入时不包含表头。 是:写入时包含表头。 说明: 仅文件格式为 TXT 、CVS 支持填写。 当来源端包含表头,且选择不跳过表头时,目标端建议选择不包含表头,否则可能导致表头数据重复。 |
标记完成文件 | 空白的 .ok 文件,标志任务传输完成。 不生成:任务完成后,不生成空白的 .ok 文件(默认选中) 生成:任务完成后,生成空白的 .ok 文件 |
标记完成文件名称 | 填写时需包含完整文件路径、名称、后缀,默认在目标路径下按照目标文件名称及后缀生成 .ok 文件。 支持在数据同步、文件传输模式下使用时间调度参数 ${yyyyMMdd} 等; 支持在文件传输模式下使用内置变量 ${filetrans_di_src} 代表源文件名称。如:/user/test/${filetrans_di_src}_${yyyyMMdd}.ok。 注意: 在文件传输模式下目标文件名称中如果使用 ${filetrans_di_src} 引用源文件名称,并且标记完成文件按照目标文件名称及后缀生成 .ok 文件时,生成的标记完成文件个数取决于来源端的文件数量。 |
高级设置(选填) | 可根据业务需求配置参数。 |
数据类型转换支持
读取
HDFS 读取支持的数据类型及转换对应关系如下(在处理 HDFS 时,会先将 HDFS 数据源的数据类型和数据处理引擎的数据类型做映射):
HDFS(Hive 表) 数据类型 | 内部类型 |
TINYINT,SMALLINT,INT,BIGINT | LONG |
FLOAT,DOUBLE | DOUBLE |
STRING,CHAR,VARCHAR,STRUCT,MAP,ARRAY,UNION,BINARY | STRING |
BOOLEAN | BOOLEAN |
DATE,TIMESTAMP | DATE |
写入
HDFS 读取支持的数据类型及转换对应关系如下:
内部类型 | HDFS(Hive 表 )数据类型 |
LONG | TINYINT,SMALLINT,INT,BIGINT |
DOUBLE | FLOAT,DOUBLE |
STRING | STRING,CHAR,VARCHAR,STRUCT,MAP,ARRAY,UNION,BINARY |
BOOLEAN | BOOLEAN |
DATE | DATE,TIMESTAMP |
HDFS 脚本 Demo
如果您配置离线任务时,使用脚本模式的方式进行配置,您需要在任务脚本中,按照脚本的统一格式要求编写脚本中的 reader 参数和 writer 参数。
"job": {"content": [{"reader": {"parameter": {"path": "/path/source.txt", //文件路径"nullFormat": "null", //空值转换"hadoopConfig": { //如果hadoop为高可用集群,需要配置NameNode高可用配置信息"dfs.namenode.https-address.mycluster.nn2": "ip:4009","dfs.namenode.https-address.mycluster.nn1": "ip:4009","dfs.nameservices": "mycluster","dfs.ha.namenodes.mycluster": "nn1,nn2","dfs.namenode.servicerpc-address.mycluster.nn2": "ip:4010","dfs.namenode.servicerpc-address.mycluster.nn1": "ip:4010","fs.defaultFS": "hdfs://mycluster","dfs.namenode.rpc-address.mycluster.nn2": "ip:4007","dfs.namenode.rpc-address.mycluster.nn1": "ip:4007","dfs.namenode.http-address.mycluster.nn2": "ip:4008","dfs.namenode.http-address.mycluster.nn1": "ip:4008","dfs.client.failover.proxy.provider.mycluster": "org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider",},"column": [{"name": "null","index": 0,"type": "string"}],"defaultFS": "hdfs://ip:4007","skipHeader": "false", //是否跳过表头"fieldDelimiter": ",", //字段分割符"encoding": "utf-8", //编码方式"fileType": "text" //文件类型},"name": "hdfsreader"},"transformer": [],"writer": {"parameter": {"path": "/path/sink", //文件路径"fileName": "sink_table", //文件名"nullFormat": "null", //空值转换"hadoopConfig": { //如果hadoop为高可用集群,需要配置NameNode高可用配置信息"dfs.namenode.https-address.mycluster.nn2": "ip:4009","dfs.namenode.https-address.mycluster.nn1": "ip:4009","dfs.nameservices": "mycluster","dfs.ha.namenodes.mycluster": "nn1,nn2","dfs.namenode.servicerpc-address.mycluster.nn2": "ip:4010","dfs.namenode.servicerpc-address.mycluster.nn1": "ip:4010","fs.defaultFS": "hdfs://mycluster","dfs.namenode.rpc-address.mycluster.nn2": "ip:4007","dfs.namenode.rpc-address.mycluster.nn1": "ip:4007","dfs.namenode.http-address.mycluster.nn2": "ip:4008","dfs.namenode.http-address.mycluster.nn1": "ip:4008","dfs.client.failover.proxy.provider.mycluster": "org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider",},"column": [ //列名{"name": "1","type": "string"}],"defaultFS": "hdfs://ip:4007","emptyAsNull": false, //空字符串是否处理,处理的话将空字符串处理为null"writeMode": "append", //写入模式"suffix": "txt", //文件后缀"fieldDelimiter": ",", //字段分割符"encoding": "utf-8", //编码方式"fileType": "text" //文件类型},"name": "hdfswriter"}}],"setting": {"errorLimit": {"record": 0 //脏数据阈值},"speed": {"byte": -1, //不限制同步速度,正整数表示设置最大传输速度 byte/s"channel": 1 //并发数量}}}



