功能概述
WeData SQL 探索功能,面向数据开发人员和业务分析人员,提供便捷、快速的数据查询分析 IDE,支持连接 EMR、DLC 等大数据引擎进行数据探索。目前已覆盖的数据源范围包括:EMR-Hive、EMR-Kyuubi、EMR-Trino、EMR StarRocks、DLC、TCHouse-X。
说明:
目前 SQL 探索处于公测阶段,可免费体验“数据探索体验资源组”,公测结束后会按照查询的使用量按量计费。
操作步骤
进入 SQL 探索页面
1. 登录 数据开发治理平台 WeData 控制台。
2. 单击左侧菜单中的项目列表,找到需要操作 SQL 探索功能的目标项目。
3. 选择项目后,单击进入数据分析模块。
4. 单击顶部菜单中的 SQL 探索。
库表
库表筛选
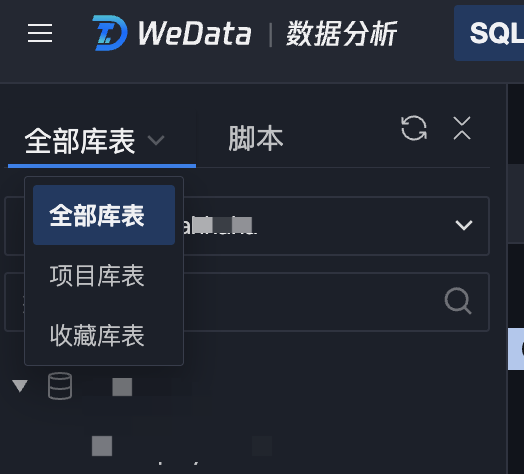
库表支持通过三种方式筛选查看:全部库表、项目库表、收藏库表。
筛选条件 | 筛选结果 |
全部库表 | 查看数据源中的所有库表 |
项目库表 | 查看数据源中归属于当前项目的库表 |
收藏库表 | 查看数据源中用户收藏的库表 |
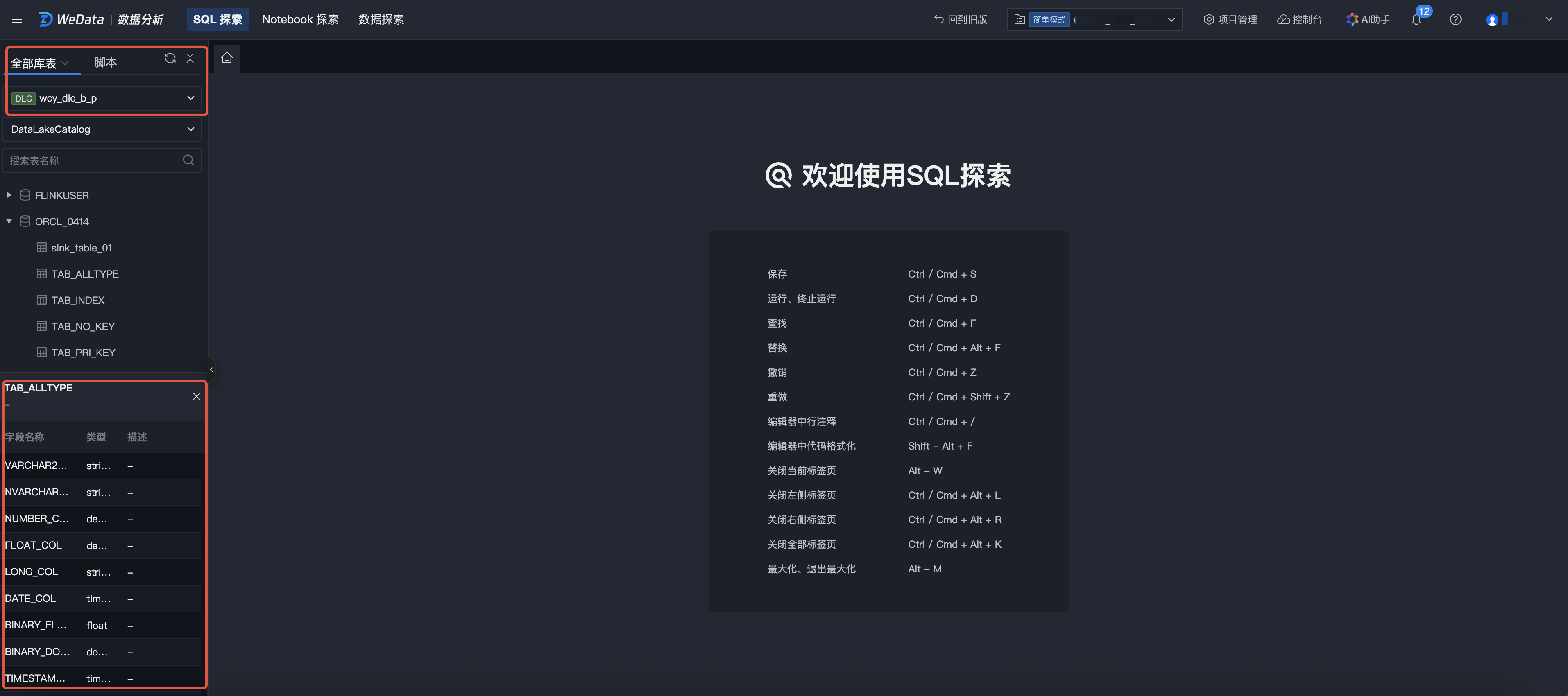
库表查询
1. 选择筛选条件和数据源,下方会显示该筛选条件和数据源下的所有数据库、表信息。
2. 支持输入表名称进行检索。
3. 单击数据表名称,可以快速查询表字段名称、字段类型、描述信息。
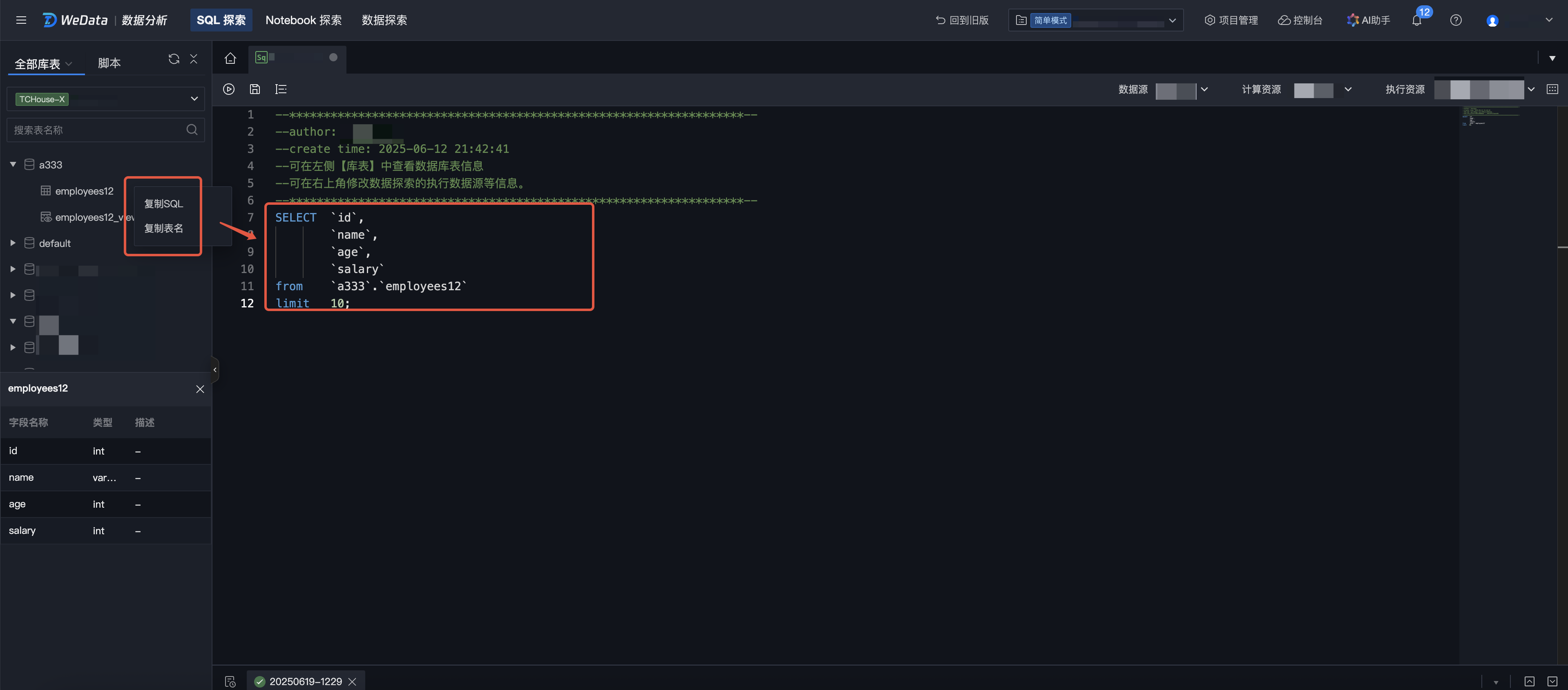
快捷操作
1. 在左侧目录树中选择某一张数据表,单击更多 > 复制 SQL > 复制表名,可以复制该数据表的查询语句和表名称。
2. 在右侧脚本编辑区,可以将复制内容快捷粘贴。
脚本
新建文件夹
方法一:切换至“脚本”栏,单击“+”,选择新建文件夹。
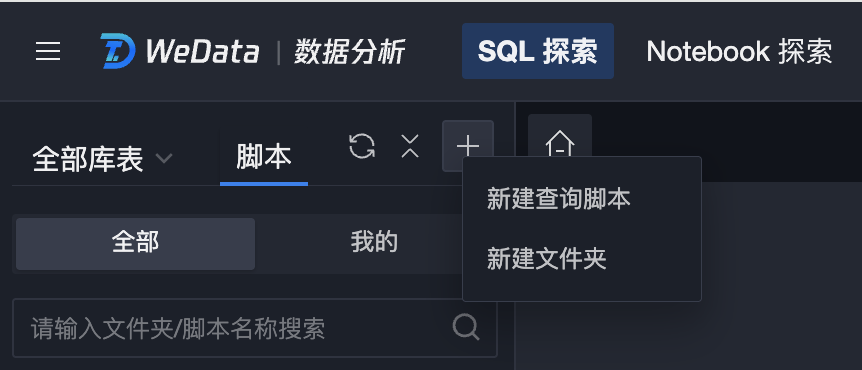
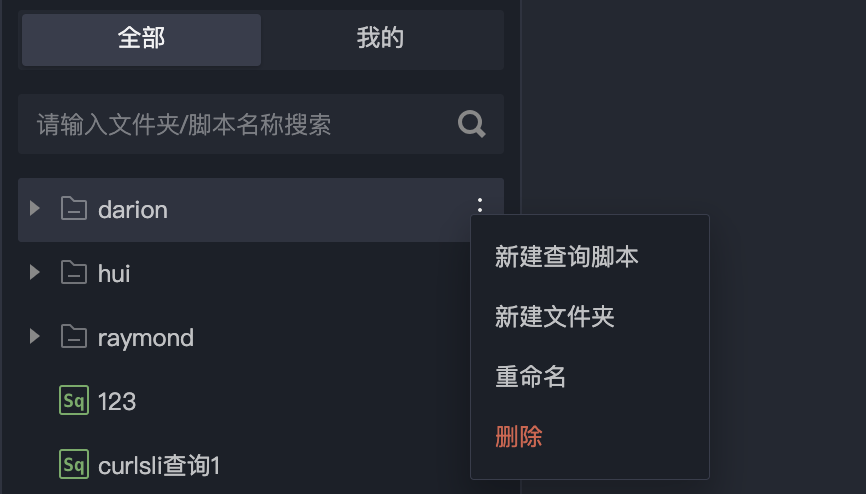
方法二:单击目录树的“更多”按钮,选择新建文件夹。
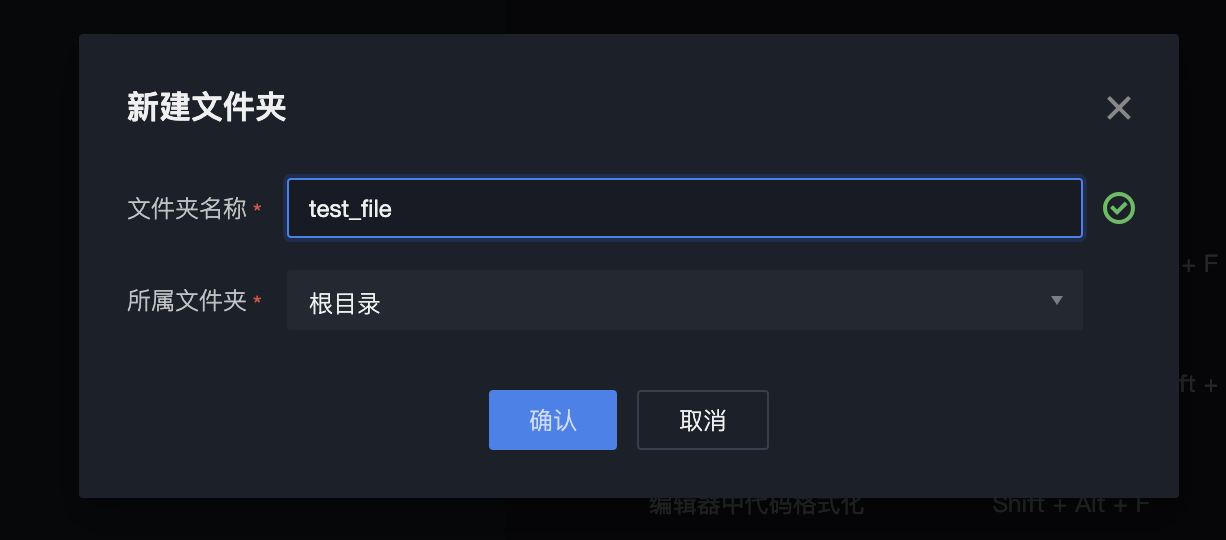
填写文件夹名称,选择所属文件夹,单击确认后,即可创建成功。
新建查询脚本
方法一:单击“+”,选择新建查询脚本。
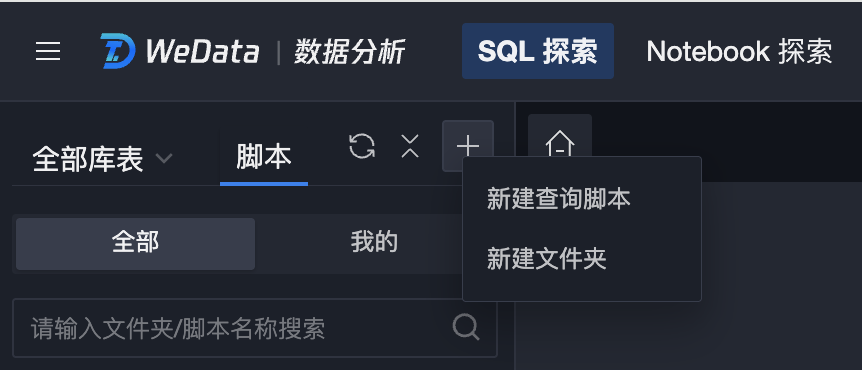
方法二:单击目录树的更多,选择新建查询脚本。
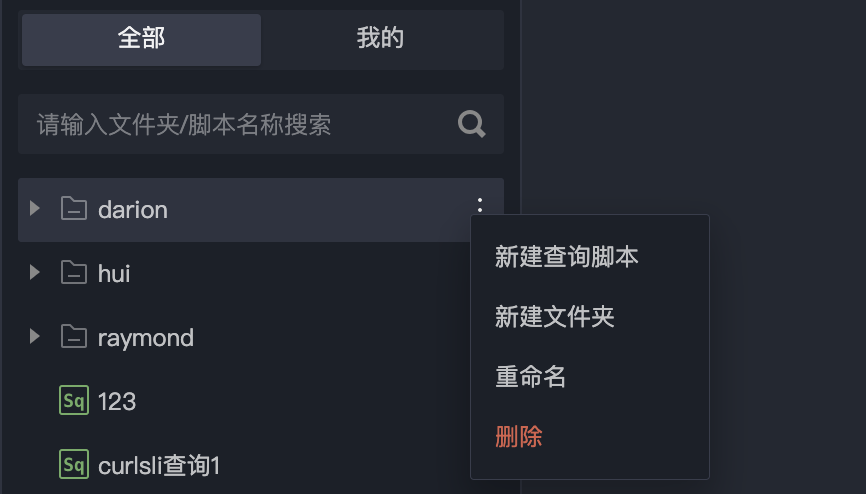
填写脚本名称,选择脚本类型和所属文件夹,单击确认后,即可创建成功。
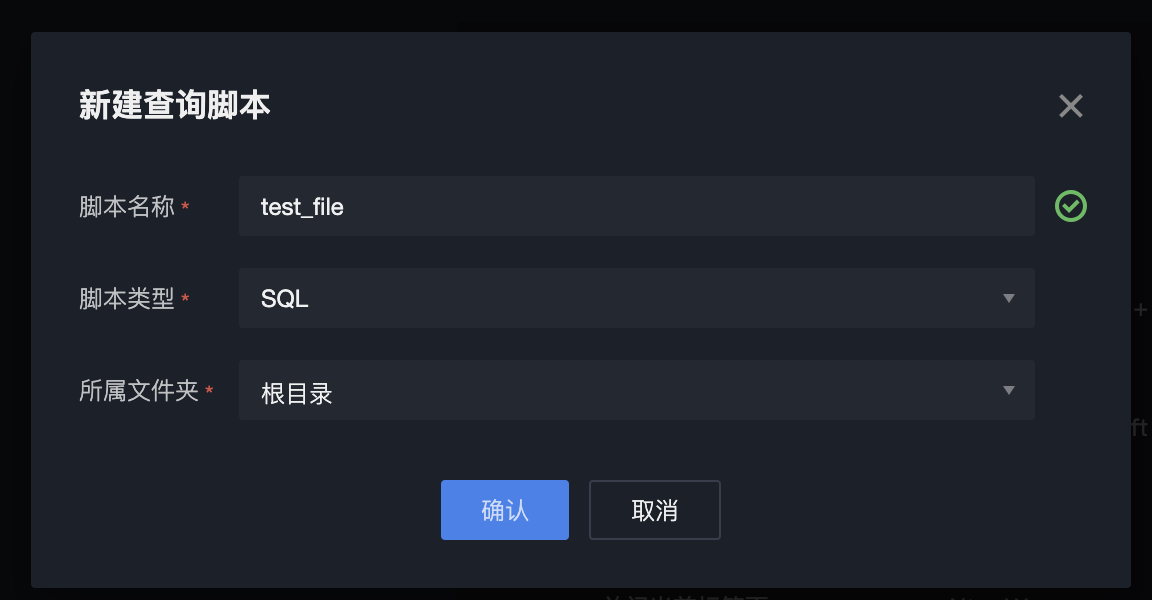
1. 为当前查询脚本配置数据源、计算资源和执行资源。
配置项 | 配置项说明 |
数据源 | 目前支持的数据源类型包括 EMR-Hive、EMR-Kyuubi、EMR-Trino、DLC、TCHouse-X。 说明: EMR-Hive、EMR-Kyuubi、EMR-Trino 数据源目前仅支持系统数据源,暂不支持自定义数据源。 |
计算资源 | 用于具体执行数据读写的引擎计算资源: 当选择 EMR-Hive、EMR-Kyuubi 数据源时,下拉选项为所在 EMR 集群的队列信息; 当选择 EMR-Trino 数据源时,无需选择计算资源; 当选择 DLC 数据源时,下拉选项为 DLC 引擎所绑定的计算资源。 |
执行资源 | 用于执行当前查询脚本的计算资源,目前仅支持选择“数据探索体验资源组”。 说明: 邀测阶段用户可免费使用“数据探索体验资源组”,支持的性能参数为每个主账号20并发,邀测结束后将进行商业化计费。 |
2. 在代码编辑区(标识4)输入 SQL 语句,目前支持的 SQL 语句包括 DDL、DML、DQL 等。
3. 单击格式化(标识3),可以对当前代码段进行格式化处理。
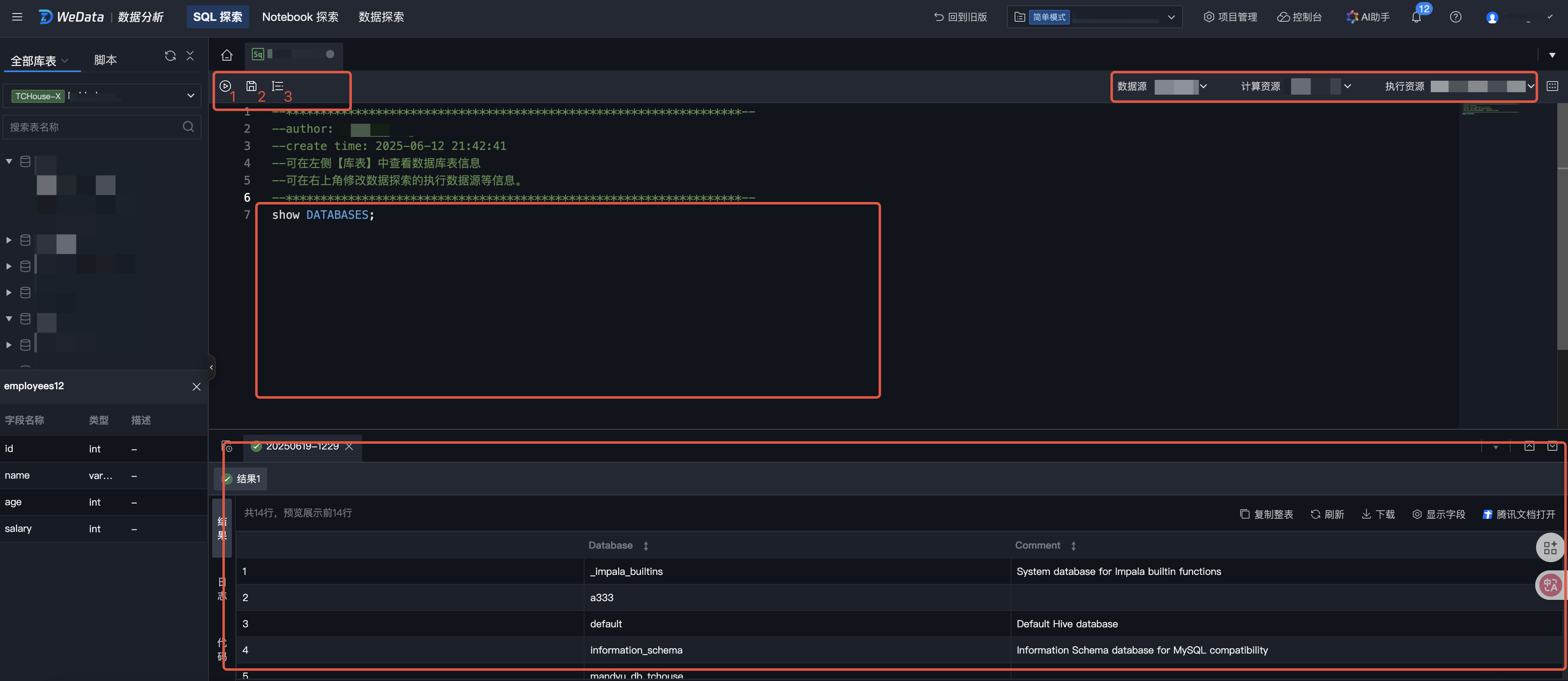
4. 单击运行(标识1),即可执行当前脚本,会在下方区域(标识4)返回运行结果。如果有多条 SQL 语句,将分为多条结果进行返回。
5. 单击保存(标识2),可以保存当前脚本内容,便于下次快速打开查询。



