说明:
WeData 中支持基于 SQL 的血缘解析,由于 Kyuubi 支持不同类型的数据源查询,因此该功能依赖 Kyuubi 中的 Catalog 配置来确定具体查询的数据源类型,当前用户可以手动设置和管理 Catalog 映射。
Kyuubi 数据源血缘解析配置
Kyuubi 数据源血缘解析依赖 Catalog 配置,当前 Kyuubi 数据源支持系统创建和自定义创建两种方式:
系统源:
用户在存算引擎配置中绑定安装了 Kyuubi 组件的 EMR 集群,由系统自动创建。该数据源无需配置,默认会映射到 Hive 系统源对应的 Catalog。
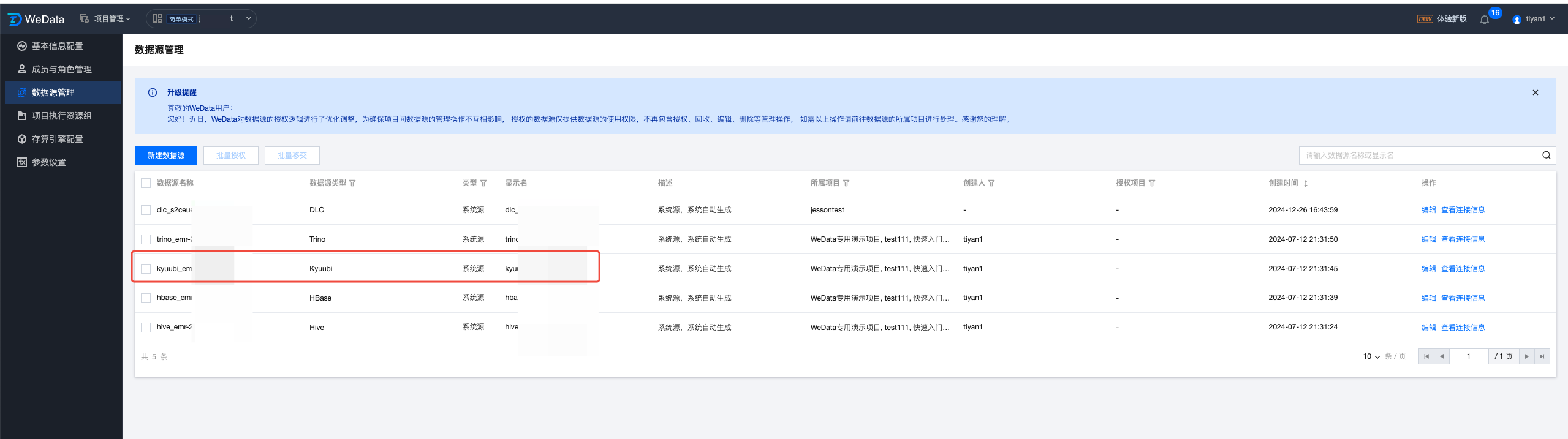
自定义源:
用户在数据源管理中配置的 Kyuubi 数据源。
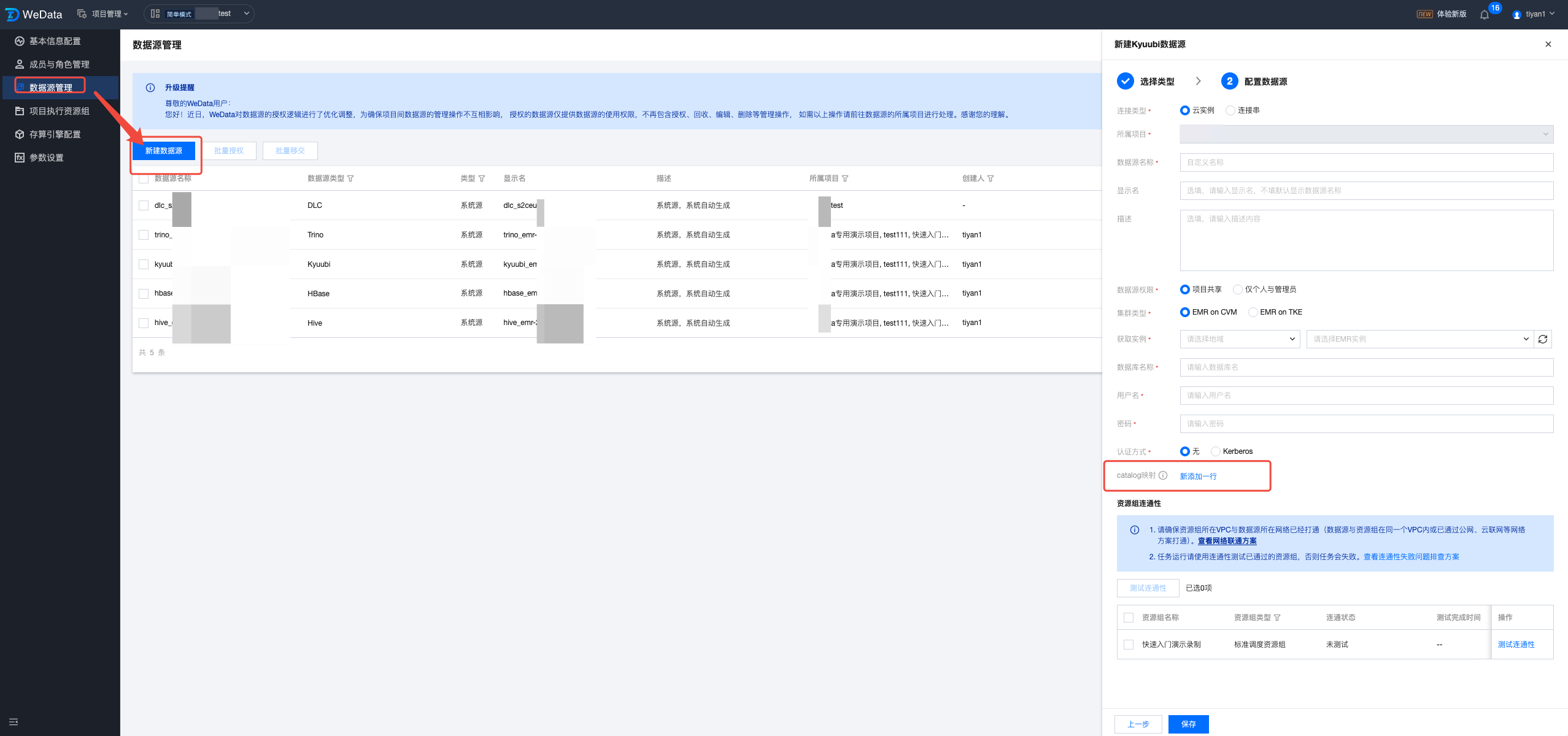
在 Catalog 映射配置中配置 Kyuubi 数据访问使用的 Catalog 映射,用于基于 SQL 的血缘解析获取正确的数据类型,示例如下:
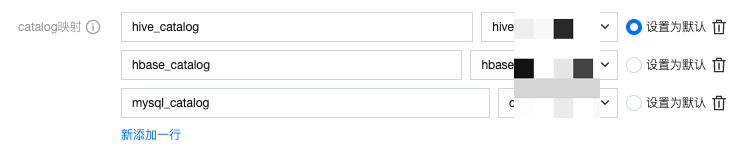
示例说明:
该配置中包含了3个 Catalog 名称:hive_catalog,hbase_catalog,mysql_catalog,该名称需要与 Kyuubi 下 Spark 的 Catalog一致,比如 hive_catalog 配置:
--定义新的Hive类型CatalogSET spark.sql.catalog.hive_catalog=org.apache.iceberg.spark.SparkCatalog;SET spark.sql.catalog.hive_catalog.type=hive;SET spark.sql.catalog.hive_catalog.uri=thrift://ip-new:9083;SET spark.sql.catalog.hive_catalog.warehouse=s3a://mybucket/warehouse;
填写好 Catalog 名称后,选择对应的数据源即可。
“设置为默认”:当被设置为默认的 Catalog 时,Kyuubi SQL 中无指定 Catalog 时的默认值。若有多个 Catalog 时,可在 Kyuubi SQL 中指定 Catalog:
select * from hive_catalog.db.table01;
配置数据源:Kyuubi
腾讯云大数据基础产品,以 EMR 中 Kyuubi 组件配置数据源为例进行讲解。Kyuubi 数据源支持云实例和连接串两种连接方式。
通过云实例方式创建数据源。
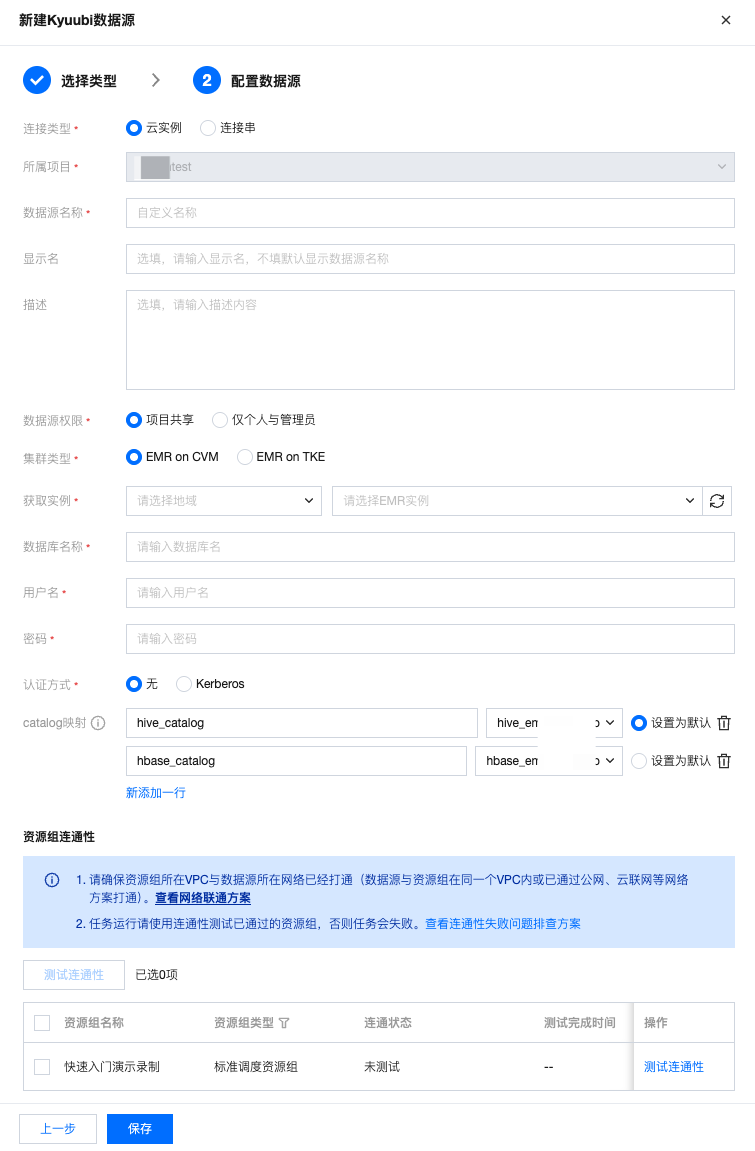
参数 | 说明 |
连接类型 | 选择云实例或连接串的数据源连接形式。 |
所属项目 | 当前数据源创建时的归属项目。 |
数据源名称 | 新建的数据源的名称,由用户自定义且不可为空。命名以字母开头,可包含字母、数字、下划线。长度在20字符以内。 |
显示名 | 数据源在产品中使用时的显示名称,不填默认显示数据源名称。 |
描述 | 选填,对本数据源的描述。 |
数据源权限 | 项目共享表示当前数据源项目所有成员均可使用 ,仅个人和管理员表示该数据源仅创建人和项目管理员可用。 |
集群类型 | 支持 EMR on CVM(基于腾讯云虚拟机) 和 EMR on TKE (基于腾讯云容器服务)两种。 |
获取实例 | 选择账户下云实例所在的地域、实例名称及 ID 信息。 |
数据库名称 | 需要连接的数据库名称。 |
用户名 | 连接数据库的用户名称。 |
密码 | 连接数据库的密码。 |
认证方式 | 支持无认证和 Kerberos 两种认证方式。 Kerberos:需要上传 Kerberos 认证所需的 keytab,conf 配置文件,并填写 principal。  |
Catalog映射 | 该配置用于 Kyuubi SQL 任务血缘解析后将库表信息映射到对应的数据源上,需要确保输入的 catalog 和 kyuubi 配置一致。 |
数据连通性 | 测试是否能够连通所配置的数据库。 |
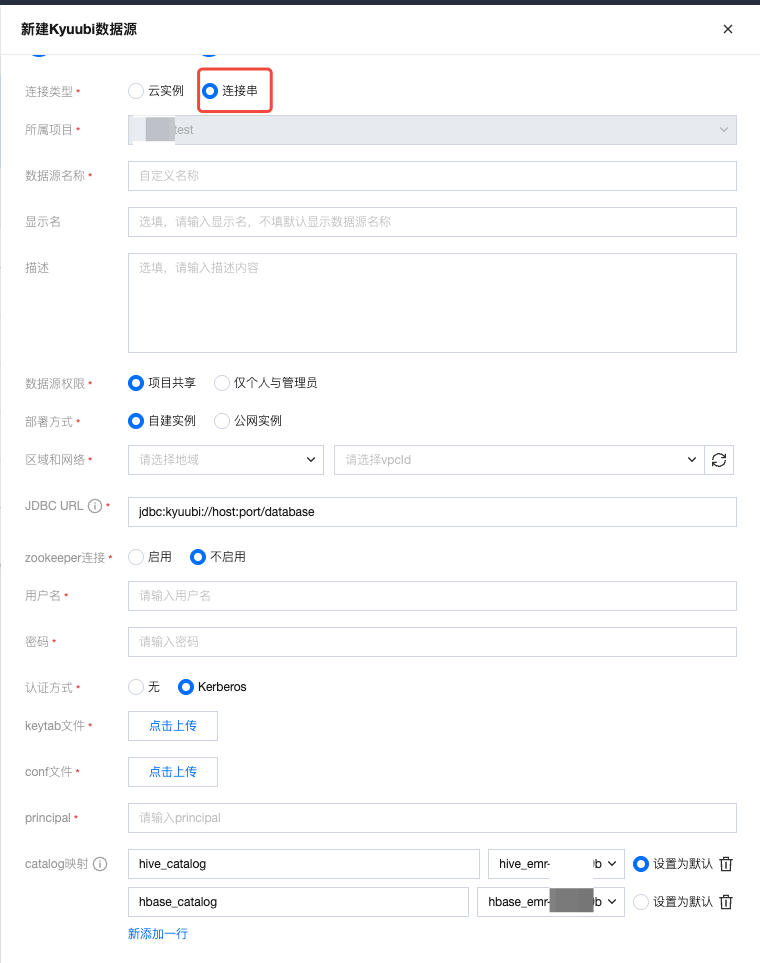
通过连接串创建数据源。
参数 | 说明 |
连接类型 | 选择云实例或连接串的数据源连接形式。 |
所属项目 | 当前数据源创建时的归属项目。 |
数据源名称 | 新建的数据源的名称,由用户自定义且不可为空。命名以字母开头,可包含字母、数字、下划线。长度在20字符以内。 |
显示名 | 数据源在产品中使用时的显示名称,不填默认显示数据源名称。 |
描述 | 选填,对本数据源的描述。 |
数据源权限 | 项目共享表示当前数据源项目所有成员均可使用 ,仅个人和管理员表示该数据源仅创建人和项目管理员可用。 |
部署方式 | 支持自建实例、公网实例两种部署方式,其中自建实例为在腾讯云服务器上部署的数据源实例,公网实例为在客户本地IDC或其他云上资源实例,支持通过公网进行访问连接。 |
区域和网络 | 当选择自建实例时,需要选择数据源实例所在地域与 vpcID。 |
JDBC URL | 用于连接 Kyuubi 数据源实例的连接串信息,包含 host ip、port、数据库名称等信息。 连接 kyuubi 数据源,填写样例:jdbc:hive2://<host>:<port>/<database>;principal=<principal>;transportMode=<transportMode>;ssl=<ssl>;httpPath=<httpPath> 通过 kyuubi 访问 hive,填写样例:jdbc:hive2://<kyuubi_host>:<kyuubi_port>/;transportMode=binary;httpPath=<hive_jdbc_url> 通过 kyuubi 访问 spark,填写样例:jdbc:hive2://<kyuubi_host>:<kyuubi_port>/;transportMode=binary;httpPath=<spark_jdbc_url> 通过 kyuubi 访问 presto,填写样例:jdbc:hive2://<kyuubi_host>:<kyuubi_port>/<presto_catalog>;schema=<presto_schema> |
zookeeper 连接 | 填写 zookeeper 连接地址。 填写样例:jdbc:hive2://zk01:2181,zk02:2181,zk03:2181/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2 |
用户名 | 连接数据库的用户名称。 |
密码 | 连接数据库的密码。 |
认证方式 | 支持无认证和 Kerberos 两种认证方式。 Kerberos:需要上传 Kerberos 认证所需的 keytab,conf 配置文件,并填写 principal。  |
Catalog 映射 | 该配置用于 Kyuubi SQL 任务血缘解析后将库表信息映射到对应的数据源上,需要确保输入的 Catalog 和 Kyuubi 配置一致。 |
数据连通性 | 测试是否能够连通所配置的数据库。 |



