1. 我有数据实时集成需求,需要购买多少资源?
如果只涉及实时同步,不涉及离线同步,可以只购买实时资源包。
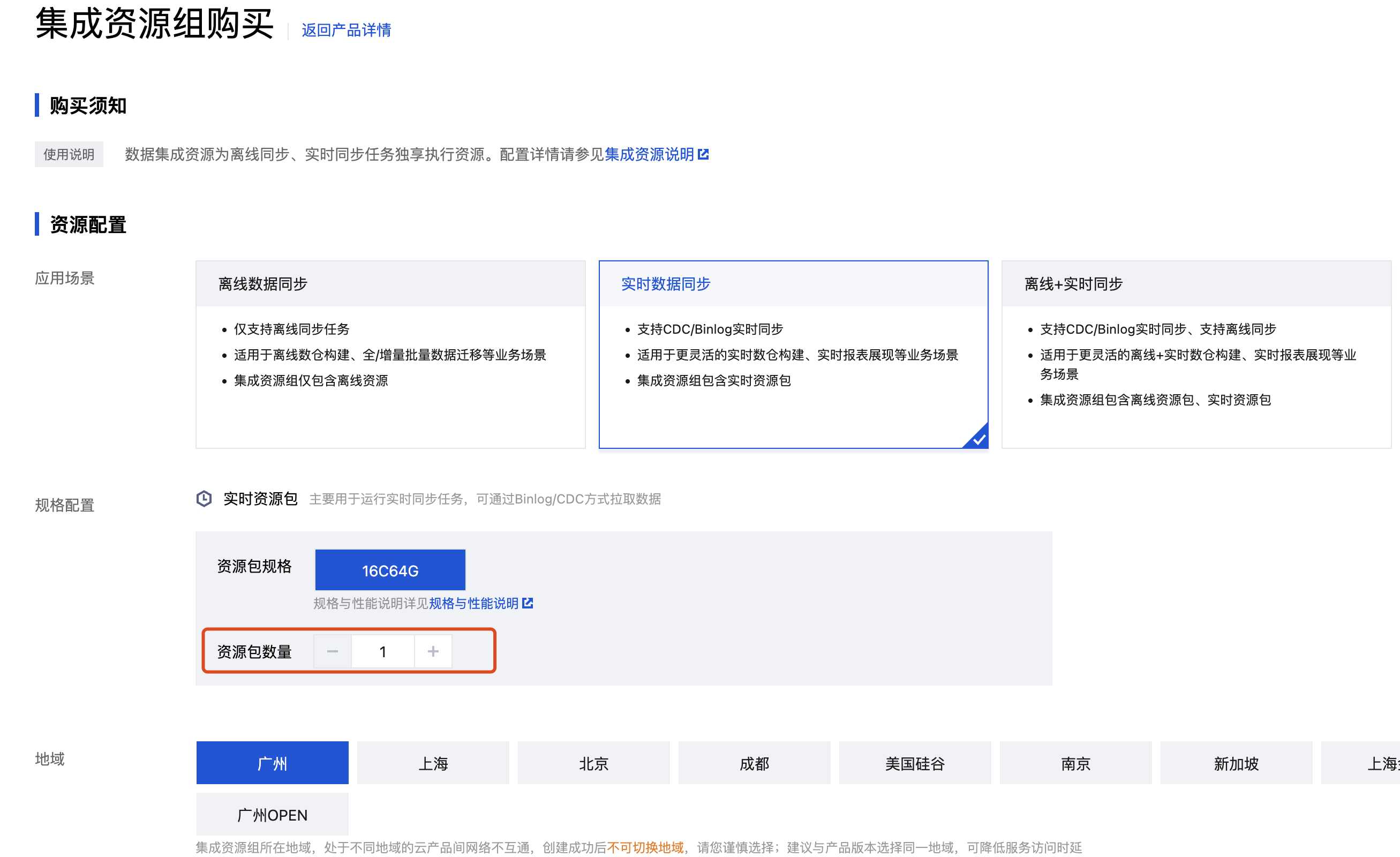
目前仅支持16C64G一个规格。1个16C64G的资源包推荐配置8个整库迁移/分库分表任务(一个整库任务推荐最少使用2CU,大概支持50张表 ),16个单表同步任务(一个单表任务推荐最少使用1CU)。资源包的数量取决于不同种类的任务数,例如:如果需要建64个整库迁移,则至少需要64/8=6个实时资源包;如果需要建16个整库迁移,32个单表任务,则至少需要16/8+32/16=4个实时资源包。
资源包类型 | 规格 | 整库迁移/分库分表推荐最大任务数 | 单表实时同步推荐最大任务数 |
实时资源包 | 16C64G | 8 | 16 |
2. 如何选择实时集成任务类型?
实时集成支持整库迁移、分库分表、单表同步三种任务类型。
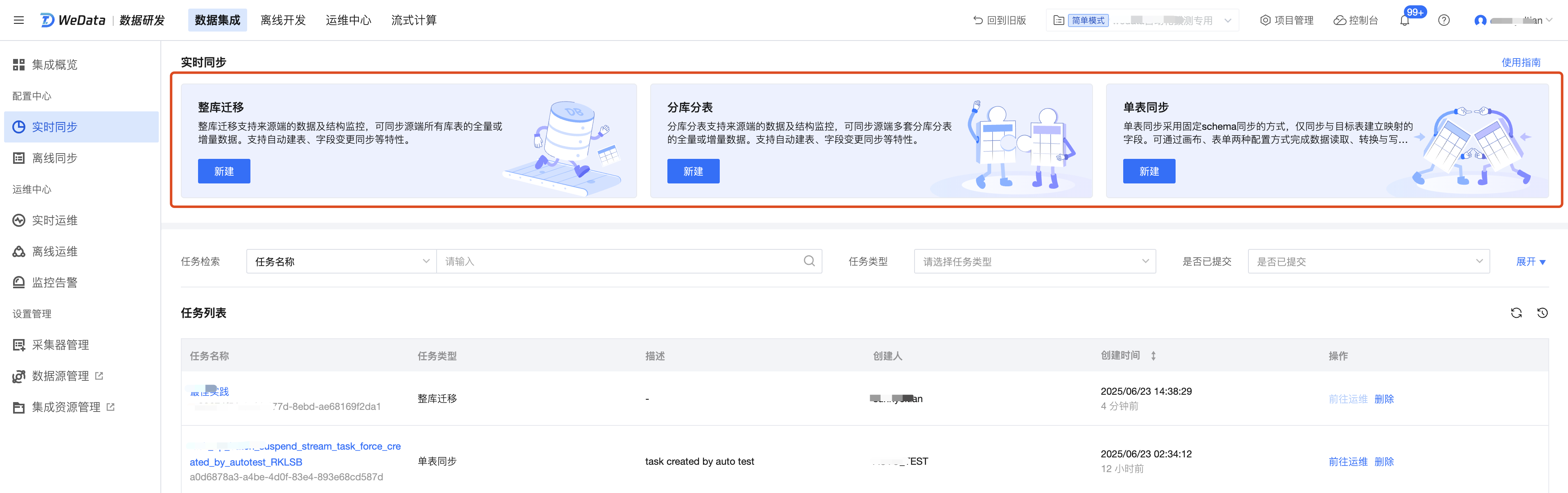
整库迁移任务:官方推荐的任务类型。一个同步任务中支持同步1张表或多张表的数据到目标端。任务提交运行后支持根据源端表结构自动创建目标表,源表的数量和目标表的数量是一对一的关系。任务运行期间源表若发生 Schema 变更可以自动同步到目标表。由于整库迁移任务一个任务可支持同步多表数据,所以占用源端链接较少,所需的同步资源整体较少,建议优先使用整库迁移任务。
分库分表任务:若源表由于业务需要被拆分成分库分表,多个分表的数据需要实时同步到目标端的一张表中,该场景下可使用分库分表任务。分库分表任务与整库迁移任务机制类似,只是会将源端的分表抽象成逻辑表后再同步到目标端。
单表同步任务:一个同步任务只支持一张源表和一张目标表。目标表需要事先创建好,任务运行期间不支持自动建表,源表发生Schema变更也不支持同步到目标端。占用的数据源链接和整体资源较多,整库迁移任务有对应链路的情况下不建议用单表同步任务类型。
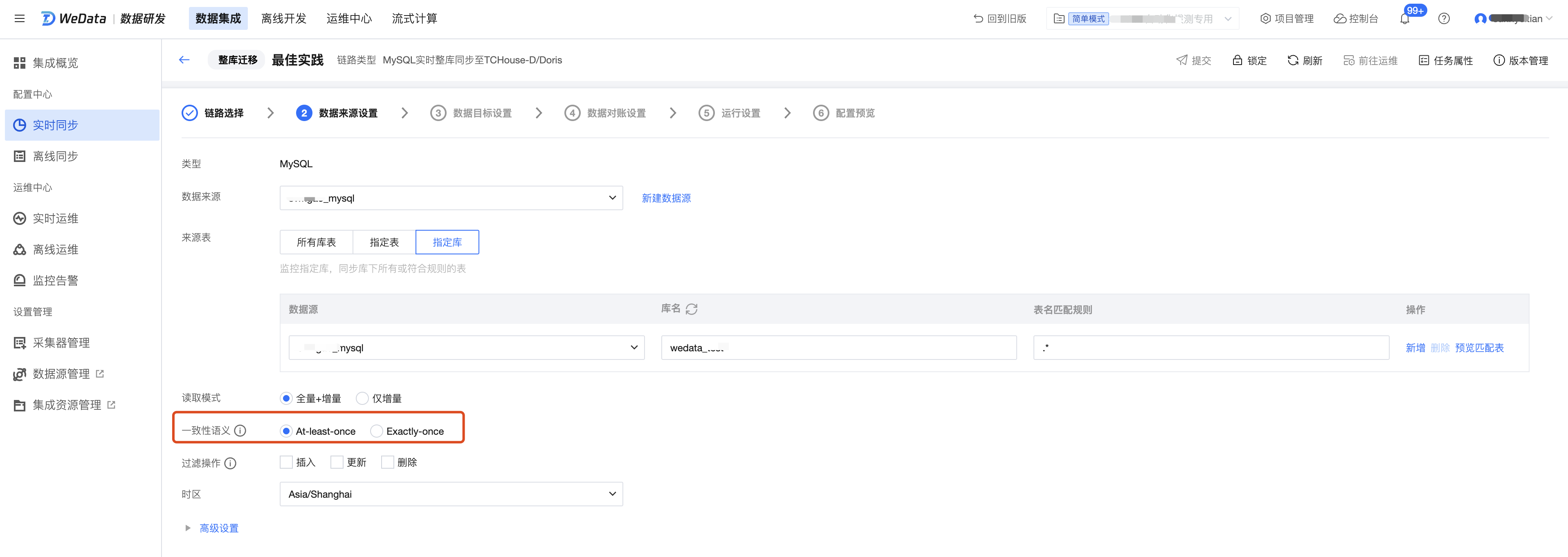
3. 如何选择源端全量同步阶段的一致性语义和目标端的写入模式?
部分数据来源全量阶段支持 At-least-once 和 Exactly-once 两种读取语义:
部分数据目标端支持 upsert 和 append 两种写入模式:
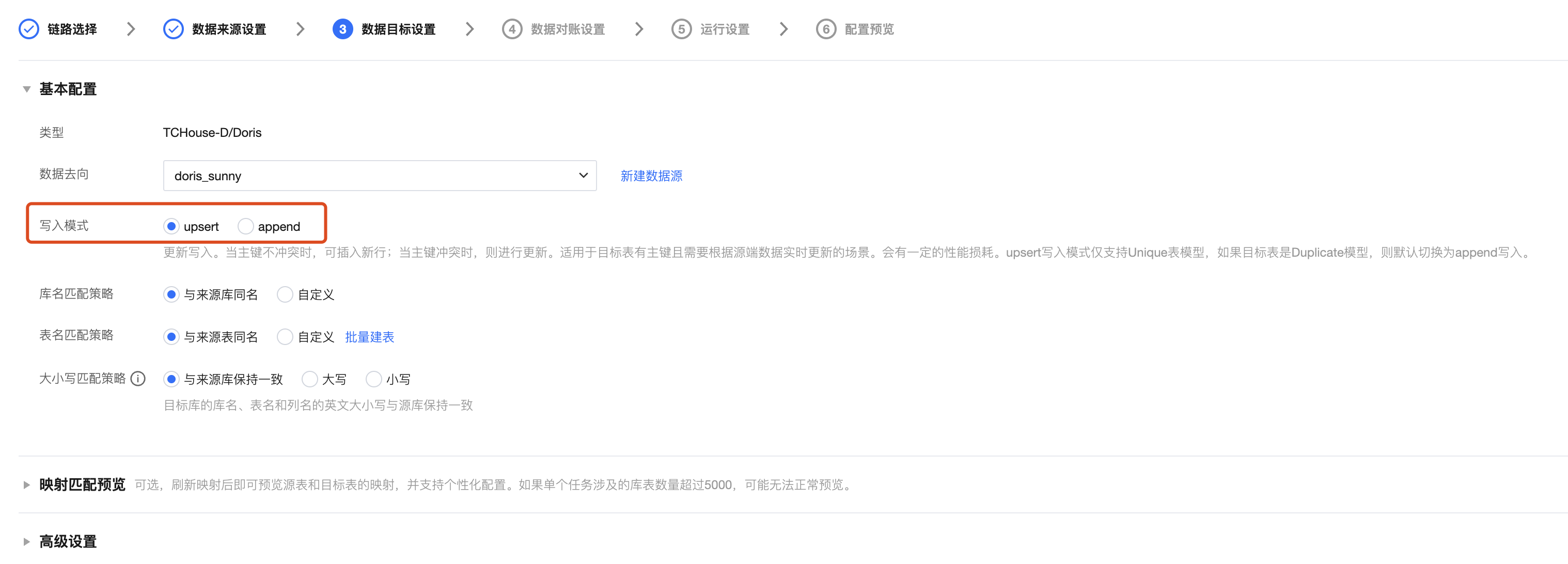
整库迁移/分库分表任务
源端有主键表推荐使用 At-least-once 读取 +upsert 写入,任务异常重启后不会有数据重复问题;源端无主键表推荐使用 At-least-once 读取 +append 写入,任务异常重启后可能会有数据重复问题。
At-least-once:数据可能存在重复读取,需要依赖目标端去重(目标端支持 upsert 写入),如果目标端是 append 写入方式,则可能出现数据重复写入。但该语义下读取性能较好,且支持无主键且无唯一索引的表。当任务全量阶段首次运行或任务重启时,会先将目标端数据清空,再进行全量数据同步。
Exactly-once:数据严格只读取一次,有性能损耗,不支持无主键且无唯一索引的表。当任务全量阶段首次运行或任务重启时,不会清空目标端数据。后续计划下线。
注意:
如果源端既有主键表或唯一索引表,又有无主键表,建议拆分为不同的任务,将有主键表或唯一索引表放到一个任务里,将无主键表放到另外的任务里。分别采用上面的原则进行读取和写入模式配置。
单表任务
源端默认走 Exactly-once 读取,不支持 At-least-once。源端只支持有主键表,目标端推荐用 upsert 写入。
4. 如何配置实时集成任务资源?
4.1 整库/分库分表任务
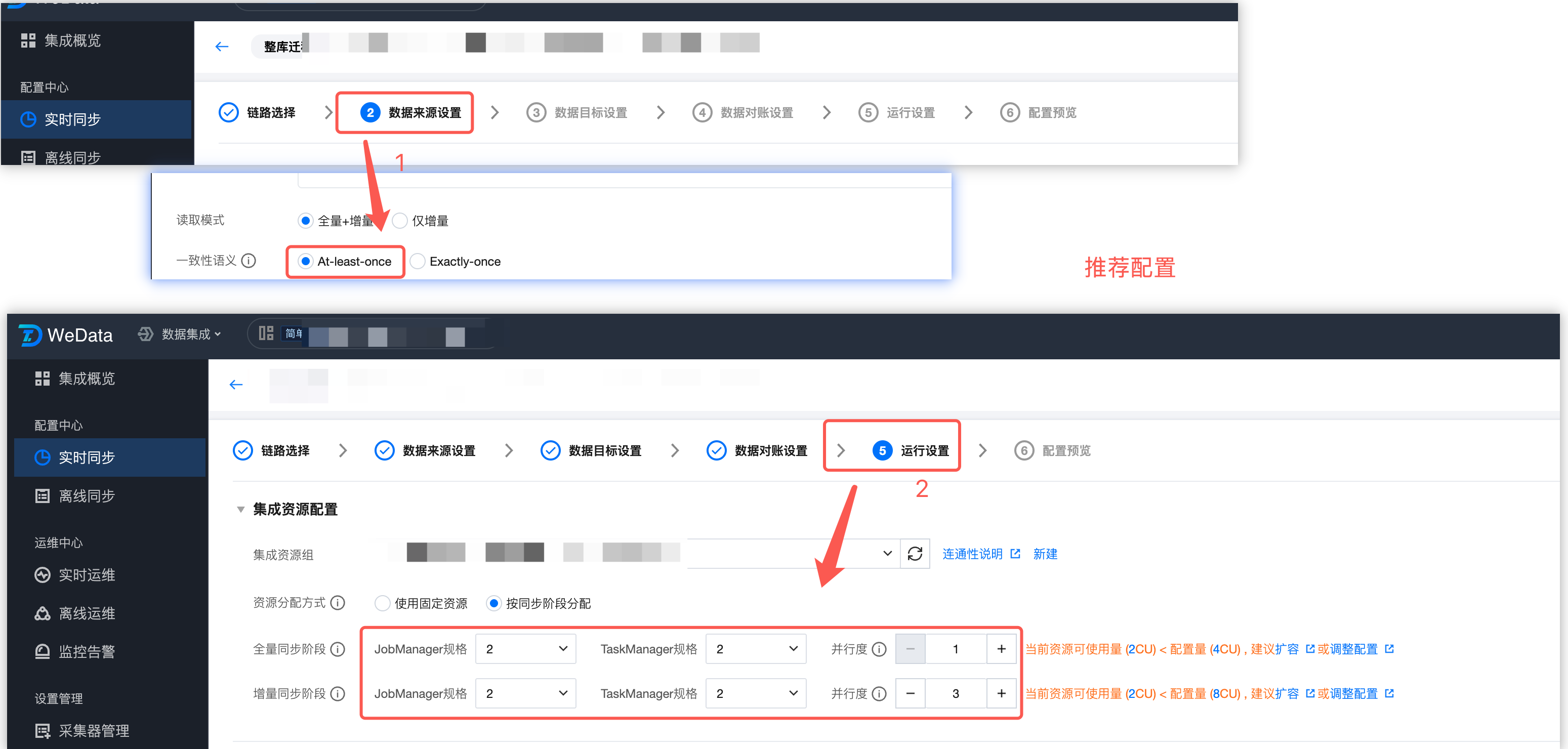
推荐按同步阶段分配资源。
全量阶段
At-least-once 模式
JM 规格:会缓存所有表的 Schema 信息。建议最小1CU;表个数每增加200个,则增加1CU。
TM 规格:建议最小1CU。如果目标端是 Iceberg/hive/DLC 等需要两阶段提交生效的数据源,则建议使用2CU。
TM 并发数:每个并发同步一张表,同步完成后再同步下一张表,多个并发则同时同步多张表,每个并发之间互不影响。表数量跟并发数关系参考下表:
表数量 | 并发数 |
1 | 1 |
(1,10] | 2 |
(10,100] | 3 |
(100,200] | 4 |
(200,5000] | 5及以上,建议单任务包含的表数量不超过5000。 |
Exactly-once 模式(不推荐)
JM 规格:会缓存所有表的 Schema 信息和分块信息。建议配置2CU。配置的表个数达到百级,则配置3CU。表数量达到千级,则配置4CU。如果表更多,则建议切换 At-least-once 语义。
TM 规格:跟分块大小有关。使用默认分块大小(8096条记录)时建议最小配置2CU,分片大小每增加10w条,则增加1CU。
TM 并发数:每个并发同步一个分块,同步完成后再同步下一分块,多个并发则同时同步多个分块,每个并发之间互不影响。表数量跟并发数关系参考下表:
表数量 | 并发数 |
1 | 2 |
(1,10] | 3 |
(10,100] | 4 |
(100,200] | 5 |
(200,5000] | 6及以上,建议单任务包含的表数量不超过5000。 |
增量阶段
JM 规格:会缓存所有表(包括全量阶段)的 Schema 信息。建议最小1CU;表个数大于200个,则增加1CU。
TM 规格:和增量阶段速度正相关。建议最小1CU。上游实例数据变更速度较大时,或者目标端是 Iceberg/hive/DLC 等需要两阶段提交生效的数据源时,则建议2CU及以上。
TM 并发数:配置为1即可。
4.2 单表任务
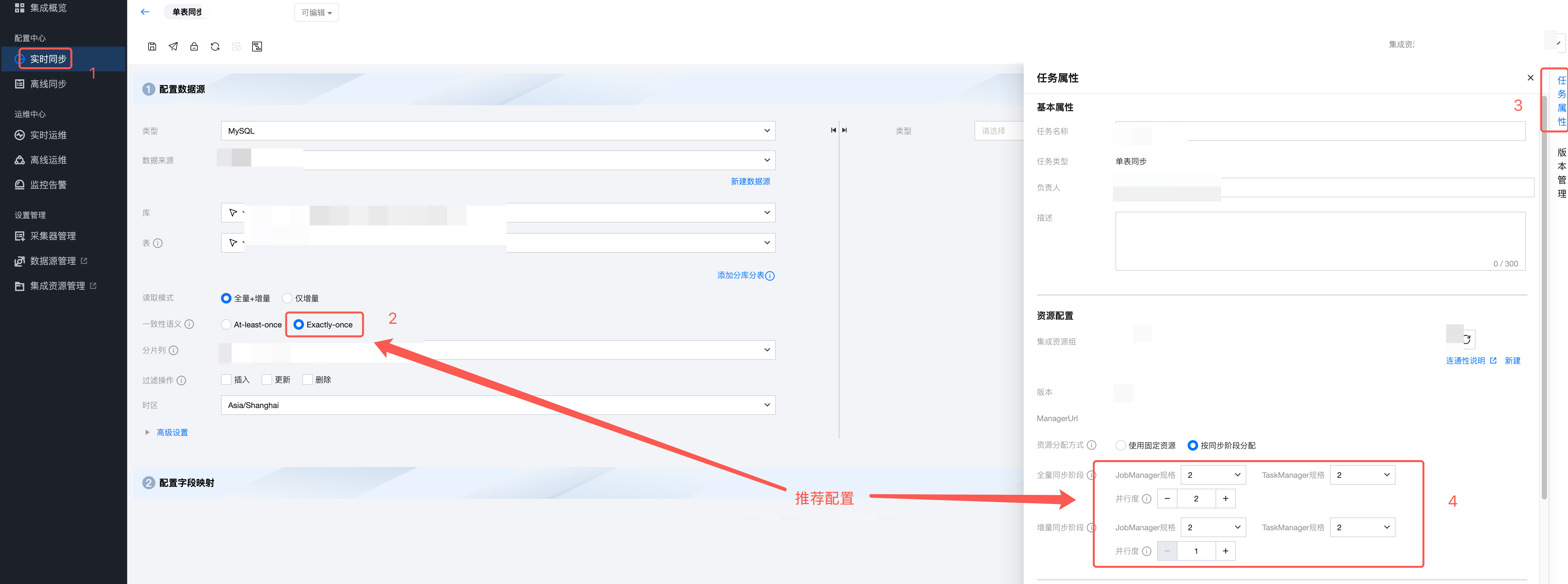
推荐按同步阶段分配资源。
全量阶段
JM 规格:会缓存所有表的 Schema 信息和分块信息。建议配置2CU。
TM 规格:跟分块大小有关。使用默认分块大小(8096条记录)时建议最小配置2CU,分片大小每增加10w条,则增加1CU。
TM 并发数:每个并发同步一个分块,同步完成后再同步下一分块,多个并发则同时同步多个分块,每个并发之间互不影响。建议3并发。
增量阶段
JM 规格:会缓存表的 Schema 信息。建议最小1CU。
TM 规格:和增量阶段速度正相关。最小0.5CU,建议1CU。上游实例数据变更速度较大时,或者目标端是 Iceberg/hive/DLC 等需要两阶段提交生效的数据源时,则建议2CU及以上。
TM 并发数:配置为1即可。
5. 如何选择任务的启动方式?不同的启动方式会有什么影响?
实时集成任务配置完后可以提交到运维中心运行。提交过程后需要选择提交策略,如下图:
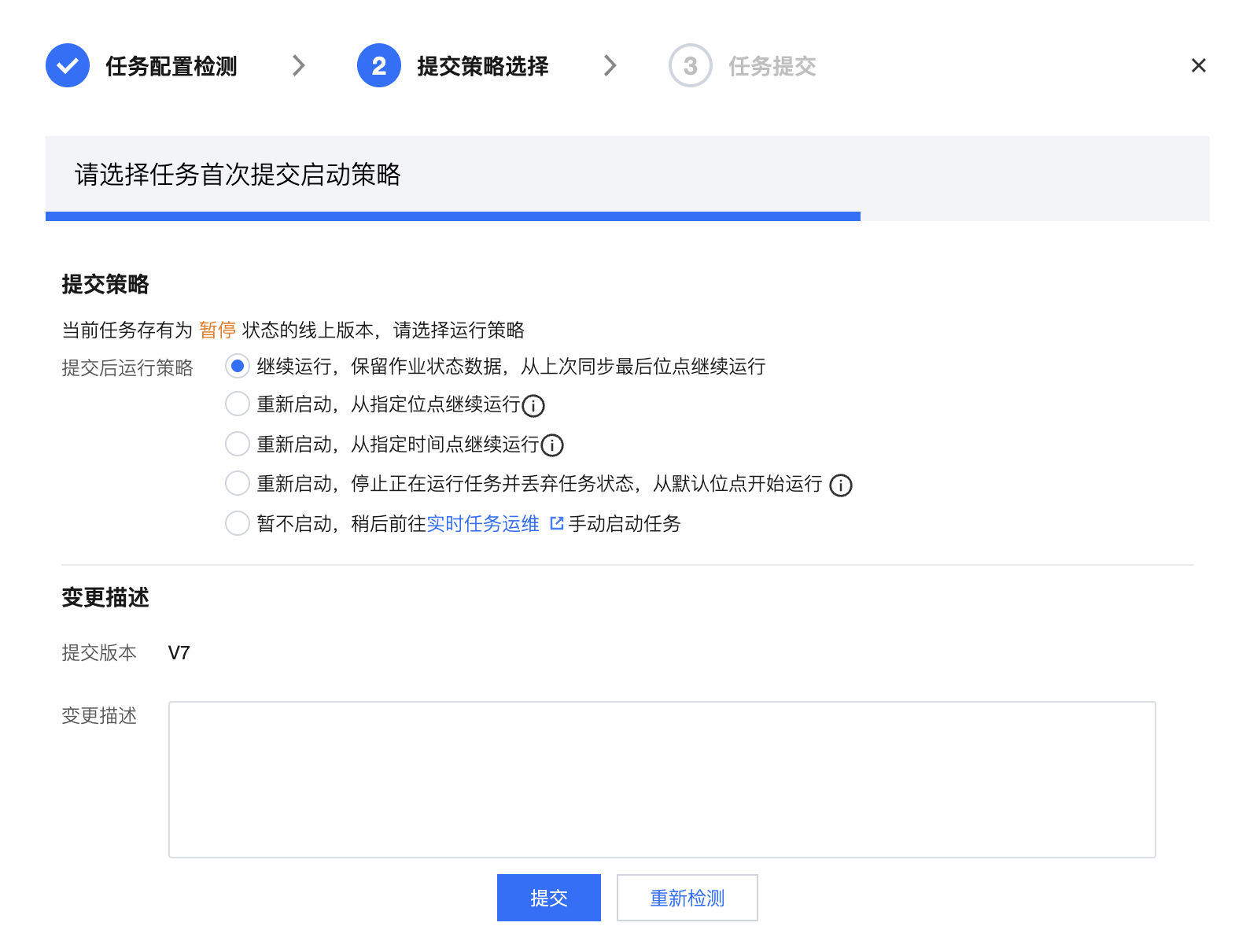
不同的任务运行状态支持的提交策略有所差异:
任务状态 | 提交运行策略 | 说明 |
1. 首次提交 2. 已停止/检测异常/初始化(非首次提交) | 立即启动,从默认位点开始同步 | 注意: 正常情况下建议选择该策略进行提交。 此策略下将根据源端配置从默认位点开始读取。若源端配置为“全量+增量”读取方式,则默认先同步存量数据(全量阶段),完成后即可消费 binlog 获取变更数据(增量阶段);若源端配置为 “仅增量”读取,则默认使用binlog最新位点开始读取。 |
| 立即启动,指定位点开始同步 | 注意: 仅 MySQL/TDSQL-C MySQL 数据源支持该策略。 1. 从指定的日志位点开始读取数据。若未匹配到指定位点,任务则默认从binlog最早位点开始同步 2. 若您源端读取方式为【全量+增量】,选择此策略将默认跳过全量阶段从增量的指定位点开始同步 3. 不同的数据源日志位点格式有所差异,如 MySQL 日志位点由两个部分组成:filename 和 position 。假设您的 binlog 文件名是 mysql-bin.000001,并且当前的位点是1234,那么可以输入:mysql-bin.000001:1234 。如果MySQL开启了GTID ,也可以直接填写GTID set,如 gtids=xxx,其中xxx需替换为具体的值。 |
| 立即启动,指定时间点开始同步 | 注意: 仅 MySQL/TDSQL-C MySQL 数据源支持该策略。 此策略下需选择具体的开始时间,根据时间匹配位点。 1. 从指定时间点开始读取数据。若未匹配到指定位点,任务则默认从 binlog 最早位点开始同步 2. 若您源端读取方式为全量 + 增量,选择此策略将默认跳过全量阶段从增量的指定时间位点开始同步 |
| 暂不启动,稍后前往实时任务运维手动启动任务 | 此策略下仅提交任务到实时运维,不进行任务启动,后续可从实时运维页面批量启动任务。 |
运行中(非首次提交) | 继续运行,保留作业状态数据,从上次同步最后位点继续运行 | 注意: 正常情况下建议选择该策略进行提交。 此策略下新版本任务提交后,将从上次同步最后位点继续运行。 |
| 重新启动,从指定位点继续运行 | 注意: 仅 MySQL/TDSQL-C MySQL 数据源支持该策略。 1. 从指定的日志位点开始读取数据。若未匹配到指定位点,任务则默认从 binlog 最早位点开始同步 2. 若您源端读取方式为“全量+增量”,选择此策略将默认跳过全量阶段从增量的指定位点开始同步 3. 不同的数据源日志位点格式有所差异,如 MySQL 日志位点由两个部分组成:filename 和 position 。假设您的 binlog 文件名是 mysql-bin.000001,并且当前的位点是1234,那么可以输入:mysql-bin.000001:1234 。如果 MySQL 开启了 GTID ,也可以直接填写 GTID set,如 gtids=xxx,其中xxx需替换为具体的值。 |
| 重新启动,从指定时间点继续运行 | 注意: 仅 MySQL/TDSQL-C MySQL 数据源支持该策略。 此策略下您可指定重新启动读取的位点,任务将忽略老版本从指定位点重新开始读取。若未找到指定的时间位点任务将默认从binlog最早位点开始同步。 |
| 重新启动,停止正在运行任务并丢弃任务状态,从默认位点开始运行 | 此策略下将停止正在运行的任务并丢弃任务状态,然后根据源端配置从默认位点开始读取。若源端配置为“全量 + 增量”读取方式,则默认先同步存量数据(全量阶段),完成后即可消费 binlog 获取变更数据(增量阶段);若源端配置为 “仅增量”读取,则默认使用 binlog 最新位点开始读取。 |
已暂停(非首次提交) | 继续运行,保留作业状态数据,从上次同步最后位点继续运行 | 注意: 正常情况下建议选择该策略进行提交。 此策略下新版本任务提交后,将从上次同步最后位点继续运行。 暂停操作时会生成快照,任务重新提交支持从最后位点继续运行。 强制暂停时不生成快照,任务重新提交支持从任务运行时最近一次生成的快照运行。这种暂停会导致任务数据重放一部分,如果目标写入是 Append 会有重复的数据,如果目标写入是 Upsert 则不会有重复问题。 |
| 重新启动,从指定位点继续运行 | 注意: 仅 MySQL/TDSQL-C MySQL 数据源支持该策略。 不推荐使用该选项。如果指定位点在上次同步最后位点的前面,Append 写入模式下可能会有数据重复;如果指定位点在上次同步最后位点的后面,中间的这段数据没有同步,可能导致数据同步不完整。该选项会影响加、减表的默认行为,具体参考加、减表场景说明。 1. 从指定的日志位点开始读取数据。若未匹配到指定位点,任务则默认从binlog最早位点开始同步 2. 若您源端读取方式为“全量+增量”,选择此策略将默认跳过全量阶段从增量的指定位点开始同步 3. 不同的数据源日志位点格式有所差异,如 MySQL 日志位点由两个部分组成:filename 和 position 。假设您的 binlog 文件名是 mysql-bin.000001,并且当前的位点是1234,那么可以输入:mysql-bin.000001:1234 。如果 MySQL 开启了 GTID ,也可以直接填写 GTID set,如 gtids=xxx,其中xxx需替换为具体的值。 |
| 重新启动,从指定时间点继续运行 | 注意: 仅 MySQL/TDSQL-C MySQL 数据源支持该策略。 不推荐使用该选项。如果指定时间点在上次同步最后时间点前面,Append 写入模式下可能会有数据重复;如果指定时间点在上次同步最后时间点的后面,中间的这段数据没有同步,可能导致数据同步不完整。该选项会影响加、减表的默认行为,具体参考加、减表场景说明。 此策略下您可指定重新启动读取的位点,任务将忽略老版本从指定位点重新开始读取。若未找到指定的时间位点任务将默认从 binlog 最早位点开始同步。 |
| 重新启动,停止正在运行任务并丢弃任务状态,从默认位点开始运行 | 此策略下将停止正在运行的任务并丢弃任务状态,然后根据源端配置从默认位点开始读取。若源端配置为“全量 + 增量”读取方式,则默认先同步存量数据(全量阶段),完成后即可消费 binlog 获取变更数据(增量阶段);若源端配置为 “仅增量”读取,则默认使用 binlog 最新位点开始读取。 |
失败(非首次提交) | 从上次运行失败(checkpoint)位点恢复运行 | 注意: 正常情况下建议选择该策略进行提交。 此策略下将从任务上一次运行失败的位点继续运行。 |
| 重新启动,根据任务读取配置从默认位点开始运行 | 此策略下将根据源端配置从默认位点开始读取。若源端配置为“全量 + 增量”读取方式,则默认先同步存量数据(全量阶段),完成后即可消费binlog获取变更数据(增量阶段);若源端配置为 “仅增量”读取,则默认使用binlog最新位点开始读取。 |
操作中(非首次提交) | 不支持 | 线上有同名任务且状态为操作中时,不支持重新提交任务。 |
6. 整库迁移/分库分表任务有加、减表需求该如何操作?
由于业务变化,源端表可能存在变动,新增了部分表或下线了一些表。
新增表场景
如果有新增表场景,建议任务中的来源表配置为“指定库”,指定库的情况下通过正则表达式匹配来源表。DDL 新增表策略选择“自动建表”,此时可以不修改任务配置的情况下自动同步新增表。如果原有任务配置不能匹配到源端新增的表,此时需要修改原有任务配置添加新表。
影响说明如下:
是否修改任务配置 | 加表逻辑(新增数据库/新增Schema/新增表) |
不修改任务配置 | 新增表(空表)从增量阶段开始,不同步全量数据;已有表不受影响。 |
修改任务配置后继续运行 | 新增表从默认位点开始(全量+增量模式从全量开始,仅增量模式从增量开始);已有表从最后位点继续运行。 |
删除表场景
删除表的行为以及对其他表的影响说明如下:
是否修改任务配置 | 减表 | 其他说明 |
不修改任务配置 | 自动剔除写入异常的表,不影响其他表(需要配置为“部分写入异常”策略) | 目标端的表不会自动删除 |
| 源端物理表删除,根据DDL删除表策略执行 | |
修改任务配置后继续运行 | 修改任务配置移除表,重启后按运行策略正常执行 | |
减表后加表场景
是否修改任务配置 | 减表后加表 |
不修改任务配置 | 减的表和加的表不重名,按不修改任务配置的加表逻辑和减表逻辑分别处理。 |
| 减的表和加的表重名,但表结构不变,新表按不修改任务的加表逻辑处理。(新表从增量阶段开始同步,目标端的已有数据不会清空) |
| 减的表和加的表重名,但表结构变了。按原有目标表的表结构进行写入,可能导致数据有问题或任务报错。 |
修改任务配置后重启 | 减的表和加的表不重名,按修改任务配置的加表逻辑和减表逻辑分别处理。 |
| 减的表和加的表重名,但表结构不变,新表从默认位点开始(全量+增量模式从全量开始,仅增量模式从增量开始)。 |
| 减的表和加的表重名,但表结构变了。新表从默认位点开始(全量+增量模式从全量开始,仅增量模式从增量开始),如果目标端表结构未变更会导致数据有问题或任务报错。 |
7. 无主键表或唯一索引的表如何进行实时同步?
如果源表无主键且无唯一索引,无论数据量大小,来源端只能用 At-least-once 语义读取,目标端只能用 Append 模式写入。可能会有数据重复问题,建议将源表增加主键或唯一索引。
8. 暂停、强制暂停、停止三者的区别和影响?
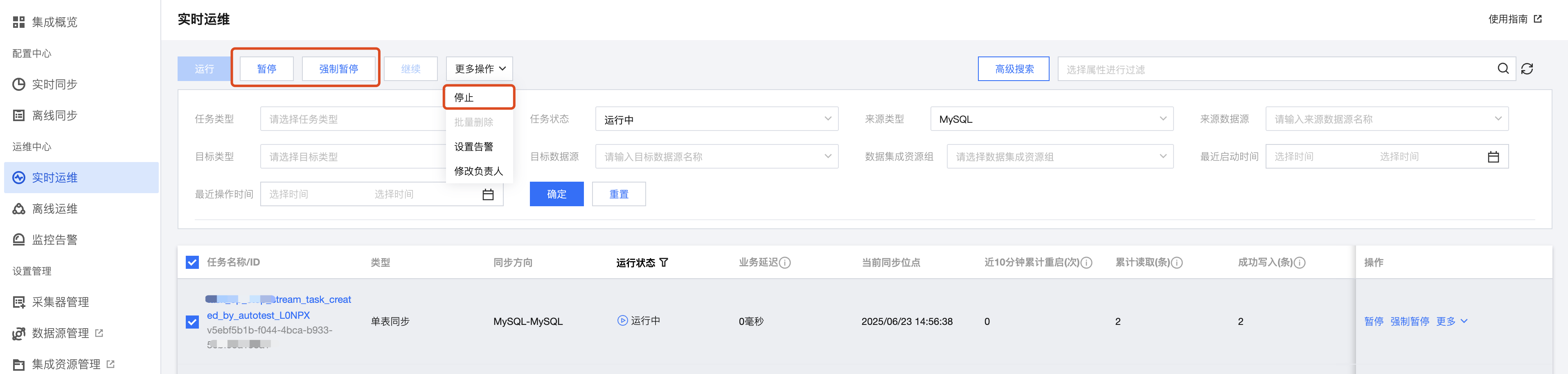
暂停:操作时会生成快照,任务重新提交支持从最后位点继续运行。正常情况下如果要临时暂停任务,建议都用暂停操作。
强制暂停:操作时不生成快照,任务重新提交支持从任务运行时最近一次生成的快照运行。这种暂停会导致任务数据重放一部分,如果目标写入是 Append 会有重复的数据,如果目标写入是 Upsert 则不会有重复问题。只有在暂停操作不生效时(任务有特殊异常情况下可能导致暂停操作不生效)才建议启用强制暂停操作。
停止:该操作将丢弃任务状态,任务会停止运行。后续再启动时跟第一次运行无差别。只有在任务有异常需要重跑的时候,或者将任务下线时才进行停止操作。
9. 如果发现任务延迟较大,如何排查和解决?
10. 什么时候需要使用高级参数进行调优?
11. 常见链路配置指引
实时集成提供以下常用链路的端到端配置指引,在以上大原则的基础上可参考下方文档进行任务配置:
其他链路可参考每个数据源的说明文档进行配置:



